Архив недели @xnimorz
Понедельник
Всем привет! Я @xnimorz. Работаю в @hh_ru. Прошел в hh.ru путь от фронтендера до тимлида и сейчас работаю ведущим разработчиком в команде архитектуры. Не специализируюсь на каком-то определенном фреймворке. Люблю и пишу на vanilla, react и svelte, слежу за vue.
В какой-то момент я осознал, что люблю больше чистый язык, чем фреймворки, но удобство, которое дают при разработке тот же vue, react или svelte — все равно круто. И тут есть философский вопрос — как погружаться в другой стек, отличный от работы?
Я для себя получил ответ в pet-projects и open-source проектах. Так, мой последний эксперимент был со Svelte: github.com/xnimorz/svelte… Главный минус — на них тоже нужно время.
На этой неделе постараемся чередовать технические темы и soft skills. Пока план такой
- Браузерные расширения
- Работа и процессы в @hh_ru
- Клиентские метрики производительности
- Байки про разработку на реакте и миграцию
- Процесс ревью
- Похоливарим над "нужностью" алгоритмов
Предлагаю начать с паранойи. И несколько вопросов: Сколько браузерных расширений у вас установлено?
🤔
46.0% Меньше 5🤔
32.3% Меньше 10🤔
21.7% Больше 10Вы их проверяли, что они "белые и пушистые"?
🤔
88.9% Нет, доверяю площадкам🤔
6.0% Да, проверяю код🤔
5.1% Еще и обновления отключаюЯ свое знакомство с разработкой браузерных расширений начал еще в 2015 году с написания плагина, который заменял new tab page в хроме на список todo, чтобы всегда список держать в фокусе (он есть у меня в репозиториях на гитхабе).
Уже затем я создавал плагин для нашей системы для HR менеджеров: chrome.google.com/webstore/detai… и после этого занимался периодически вопросами анализа и защиты от браузерных расширений.
Главная проблема с браузерными расширениями — их редко воспринимают как реальную угрозу.
Однако, у них есть все инструменты для заработка за счет других сайтов, воровства персональной информации и даже промышленного шпионажа. Проблемы с ними сравнимы с проблемами с node_modules.
Расскажу несколько тру-стори, а потом уже перейдем к техническому разбору.
История 1 про безопасность: Cоздаю себе аккаунт в некоторой условной социальной сети, ввожу телефон и email. В настройках безопасности: отображать контактные данные только друзьям.
Через пару дней на email \ телефон начинает приходить спам. Что происходит? Соц. сеть продает мои данные? Она взломана?
На самом деле все куда как проще. У пользователя стоит плагин, который делает какую-то полезную штуку для него. Но в фоне, она внедряет ContentScript на страницу, который при загрузке страницы или по MutationObserver ищет телефоны и email на странице.
Затем передает это в BackgroundScript, который уже отправляет наши контакты в спам-базы, причем с именем, фамилией и кличкой домашнего животного :)
Самое грустное в этой истории, что отследить, что твой сайт кто-то "парсит" таким способом — практически нереально. Все вызовы происходят в Content Script, который исполняется в специальном environment — isolated world, о нем я расскажу чуть позже
Тред (@xnimorz)
@jsunderhood @xnimorz @hh_ru А можно подробнее об опыте на svelte ? Сколько уже натыкаюсь на стоить на хабре про него. но что-то внутри отказывается воспринимать его как что-то серьёзное
Да, конечно. Сразу предупреждаю — опыт не production, личный.
По svelte у меня есть один проект на github — маски ввода: github.com/xnimorz/svelte….
Они мне нужны были, потому что у меня есть маленькая цель: сделать приложение комбайнер для домашних финансов. twitter.com/DonnaInsolita/…
Учет финансов, синхронизация между всеми членами семьи, разделение прав и многое-многое другое.
Я периодически делаю заходы на это приложение и в какой-то момент дошел до рабочего прототипа на реакте, которым пользовался почти год. Там не было шаринга.
В какой-то момент, я проникся svelte и появилось желание разобраться, насколько он удобен, можно ли им пользоваться. Первые ощущения были: вау-вау, круто-круто, мне кажется, у многих подобное было, когда переходили с условного бекбона на реакт.
А потом при том же переходе на реакт появлялись боли: тут нужно PureComponent, там отписку правильную сделать, здесь в ref null может прийти, с хуками тоже были боли, например, useCallback и useMemo когда использовать?
Немного по-другому у меня сложилась история со svelte.
Про плюсы svelte тут уже писали и мне лично svelte очень по душе. Но я расскажу про неприятные вещи с которыми столкнулся. Это не фатальные минусы, это то, от чего страдает DX.
Нестабильность API. Я разрабатывал на 3.12.1, а демку делал на другой версии (ниже). У меня в итоге сломался
bind:this. Описание ошибки не нашел в истории браузера, но выглядела она как internal_somevar is not defined. Что усложнило поиск и пришлось лезть в код svelteВам часто нужно будет разбираться в коде, который сгенерировал svelte. Особенно если вы делаете большое приложение. Когда делаете небольшой компонент или виджет — все сильно проще. Плюсом будет то, что код генерируется достаточно простой (обычно)
Если вам нужно прокинуть класс, вам придется объявить его как :global(класс) codesandbox.io/s/svelte-input… (вот здесь в App.svelte пример).
Если вы делаете утилитарный компонент и вы хотите прокинуть все props в обычный элемент (например aria атрибуты или еще что-то), вам придется делать деоптимизацию обращаясь к $$props.
Еще неудобство вот github.com/sveltejs/svelt…
Иногда вы зависите от порядка переменных: github.com/sveltejs/svelt…
Это те боли, которые у меня возникли за последние примерно 2 месяца.
Тред (@xnimorz)
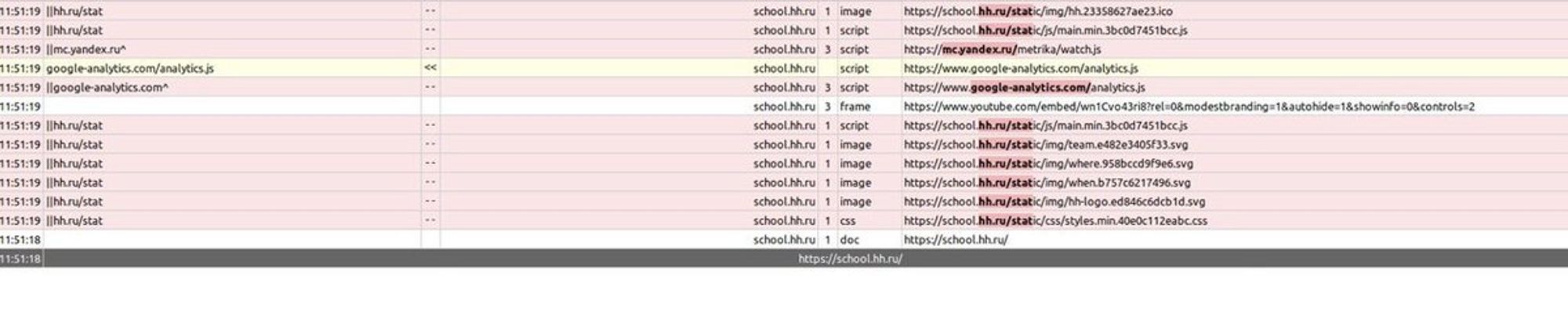
История 2 про "случайно сломать статику сайта": блокировщики рекламы очень эффективно блокируют запросы к ресурсам. У них есть чему поучиться. Вот так выглядит наш сайт с включенным блокировщиком:
А все дело в том, что плагин просто решил, что STATic — это сбор статистики пользователя, поэтому радостно заблочил все урлы вида school.hh.ru/static/bla-bla

@DonnaInsolita @jsunderhood @xnimorz @hh_ru Посмотри доклад Климова, почему использовать Свелт может быть больно.
Если я правильно понял, то речь об этом выступлении? youtube.com/watch?v=0cFoEP… twitter.com/Oleg75113370/s…
Последняя история: расширения прокси могут также зарабатывать на пользователях. Это это не только то, что они получают на проксирующих серверах http страницы. Как насчет майнинга криптовалюты? habr.com/ru/post/421735/
Почитайте, там хорошо описан процесс разбора плагина.
После публикации они правда сменили способ монетизации :)
Итак, набор проблем ясен, скрипт может выполняться в фоне, может внедряться на страницу. Остается открытым вопрос, что делать мне как человеку, который ставит себе плагины?
Всегда лучше знать, кого берешь себе. Можно проводить кучу действий над площадками, чтобы выдрать код, а можно (вот же ирония судьбы) установить плагин. Он open source. Github: github.com/Rob--W/crxview…, стор: chrome.google.com/webstore/detai…
Этот плагин будет крайне полезен при установке дополнений. Открыли стор, запустили плагин, посмотрели — насколько здесь все плохо. Например вот так выглядит FastProxy из одной из историй сейчас:
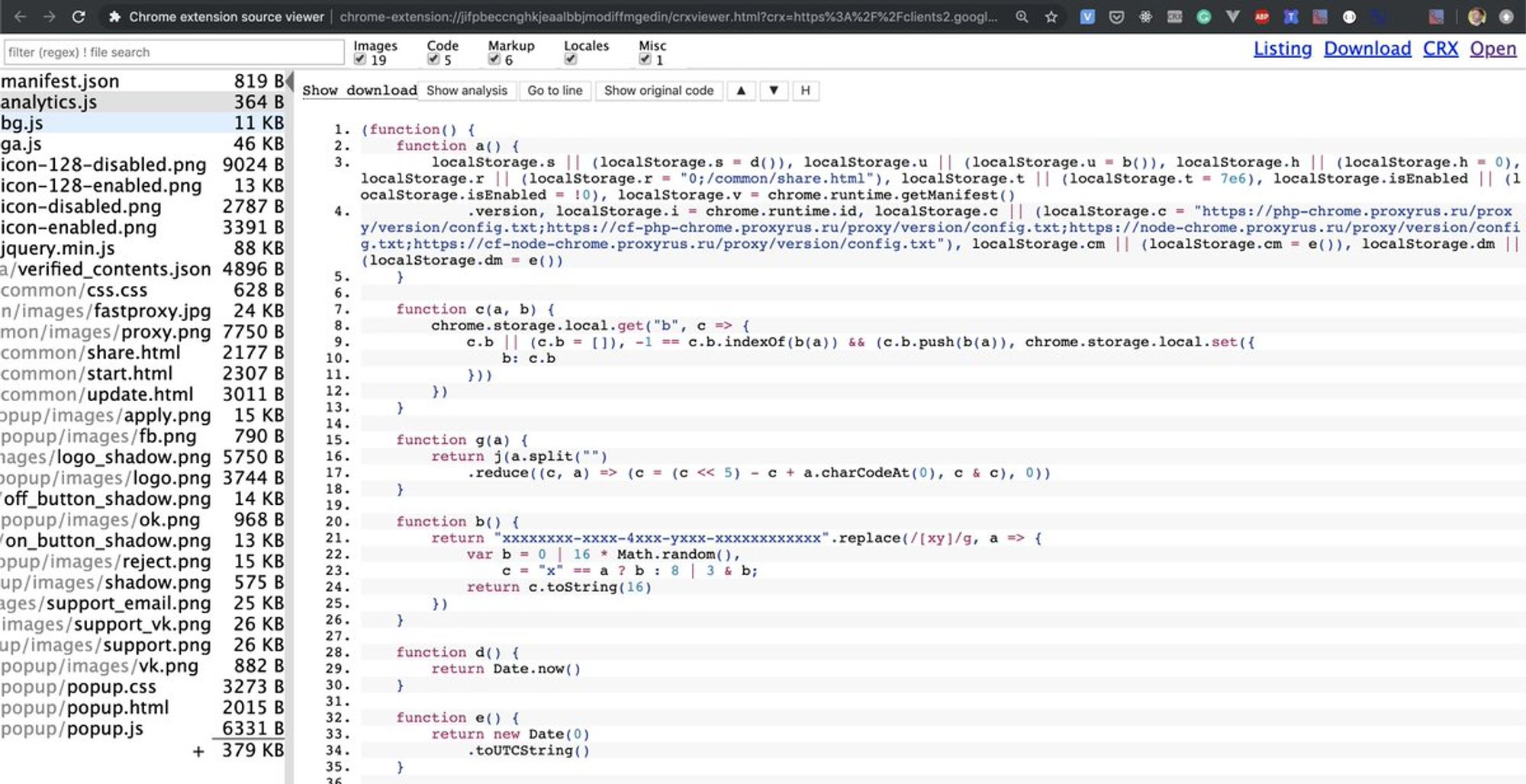
В первых же строках его кода должно закрасться сомнение, что его стоит устанавливать себе на машину.
Он откуда-то удаленно берет конфиг, зачем-то держит все в storage и не факт, что это просто конфиг. Вполне возможно, что это js.
Тред (@xnimorz)
Если попытаться выработать алгоритм для паранойи, то что мне делать как пользователю?
Проверять каждое расширение перед установкой. Причины не добавлять — подозрительный код, например eval \ подгрузка скриптов с сервера.
Отключить обновление расширений, в которых не уверены или вообще всех: stackoverflow.com/questions/2765…
Что делать с проблемой мне как разработчику сайта? Я постараюсь дать ответ с разбором на HolyJs holyjs-moscow.ru/2019/msk/talks… Интересные практики с работы и суровые примеры плагинов прилагаются. Постараемся выработать способы защиты для разных случаев. Приходите, будет весело 😀
@jsunderhood А есть расширение, которое бы проверяло другие расширения на подозрительный код автоматически?
Хорошая идея, но мне встречать такое расширение не доводилось. Может быть кто-то встречал подобное? twitter.com/BasherTheJedi/…
@jsunderhood Все дело в том, что автор фильтров перестарался.
Тут больше играет роль то, что мы на основном сайте используем урл
/stat для баннерки и мониторинга клиентской производительности.
А так как hh.ru очень популярный сайт (около 4000 RPS и стабильный TOP в similarweb.com/top-websites/c…), то под нас пишут правила :) twitter.com/maximtop/statu…Ключевая проблема здесь — правило пишут для домена, и все поддомены автоматом наследуют эти правила
@jsunderhood В рабочем (Хром) — 1, в личном (Сафари) — 0
Круто! Я провел эксперимент и понял, что не смогу отказаться от трех плагинов :( twitter.com/SanichKotikov/…
@jsunderhood Браузеры это проверяют автоматом перед паблишем, но не на 100%
В Firefox такая проверка присутствует и такой фокус обычно не пройдет. Аналогично в сафари.
В Chrome store же можно запаблишить код, который будет выполнять удаленный скрипт, который вставляют например в качестве content script. twitter.com/mr_mig_by/stat…
@BasherTheJedi @jsunderhood Это делают веб-сторы. У Оперы вообще даже ручным режимом, если автоматика показала угрозу
В Firefox проводят (проводили, когда я паблишил) также в ручном режиме. Более того, там проверяют очень подробно, мне в свое время не дали запаблишить расширение, потому что оно localStorage использовало. twitter.com/mr_mig_by/stat…
@jsunderhood Им еще можно настраивать доступ, у меня один экстеншн(notion) имеет доступ ко всем сайтам, а гугл транслейт, реакт и редакс - по клику.
Да, это хорошо позволяет уменьшить аппетиты и чуть больше быть уверенным, что за вами не следят👍. Настраивается обычно уже после установки расширения при клике на details. На скриншоте это раздел Site access: twitter.com/oburejin/statu…
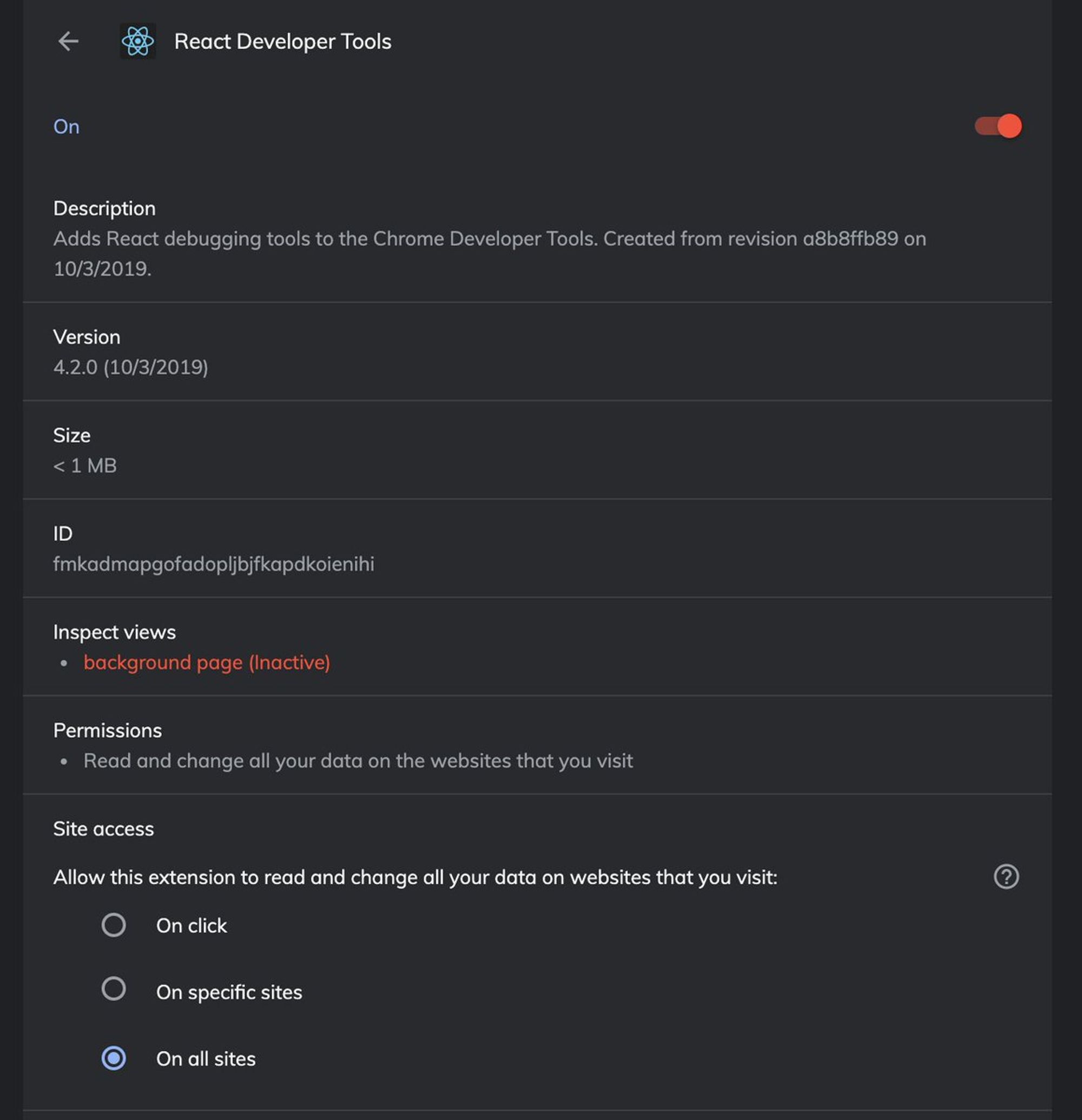
@jsunderhood А это вообще нормально, что расширения( в хроме точно) имеют доступ кл всем твоим куки. Это разве не дыра в безопасности?
Любое расширение, которое получило пермишен к сайту (либо маска сайта, либо <all_urls>) может внедрять свой код на сайт. Этот код почти никак не отличим от нашего js. Поэтому да, потенциально, это дырка. С точки зрения защиты, все авторизационные куки лучше хранить как httpOnly twitter.com/ch1sKey/status…
httpOnly прямо обязательно для любых авторизационных кук. Такие куки недоступны со стороны js.
Также можно использовать Secure в дополнение к httpOnly, но Secure метка не говорит о секьюрности куки, только то, что запросы без SSL защиты не будут их использовать.
Справедливости ради, проблема с плагинами вырастает из-за того, что большая часть возможностей им нужна, чтобы творить добро.
Скорее всего большинство из нас пользуется react или vue devtools. Им нужны пермишены для общения с вкладками, обработкой нод, замера перфоманса и т.д.
Если вы получаете обращение в саппорт "сайт тормозит", часто саппорту приходится объяснять пользователю, как сделать замер перфоманса, записать har файл...
Плагины позволяют "полу-автоматизировать" это. Например, сбор HAR файлов: developer.chrome.com/extensions/dev…
В тему плагинов и блокировщиков рекламы (особенно, если у вас хром) — пробовали ли вы Brave вместо Chrome + блокировщики рекламы? brave.com
@jsunderhood Уже пол года им пользуюсь
Я тоже в какой-то момент попробовал Brave и понял, что он меня всем устраивает. twitter.com/lyserzilla/sta…
Но с brave были некоторые сложности. Например, он блокировал сайт mvideo. Получилось зайти, только отключив guard
@jsunderhood А если использовать атрибут integrity для скриптов на сайте, в этом случае расширение сможет внедрить и выполнить js?
Обычно Content Security Policy — одна из первых штук, которая приходит в голову для защиты от плагинов. Сама по себе идея — хорошая, но к сожалению, в случае со скриптами не работает так, как хочется. twitter.com/SanichKotikov/…
Integrity или Subresource Integrity идет вместе c Content-Security-Policy: require-sri-for script; что требует проверки хешсум. Скрипты же действуют по-другому: либо внедряют content script на страницу, либо inline script. require-sri-for работает же для отдельных ресурсов.
Плюс с поддержкой у require-sri-for все пока еще не радужно: developer.mozilla.org/en-US/docs/Web…
Куда эффективнее будет запретить все скрипты, включая inline, кроме своего домена, но и тут плагины будут исполняться.
Маленькое дополнение к svelte: пару дней назад выложили "The Return of 'Write Less, Do More'" от Rich Harris youtube.com/watch?v=BzX4aT…
Но выступление больше побуждающее, мотивирующее, чем техническое. Откладывал себе посмотреть. Отлично подходит к просмотру во время дороги домой
Не "Скрипты же действуют по-другому:", а "Расширения же действуют по-другому"
Тред (@xnimorz)
@jsunderhood Единственная возможность защитить приложение от браузерных расширений, на сколько я понимаю, описана тут: youtube.com/watch?v=lXQTSX…
Здесь рассматривается только подмножество проблем — отправка данных, подписка данных ключом и получение данных. Сама же проблема этим не заканчивается.
Сюда можно смело добавлять сниффинг данных на странице, вставка рекламы от плагина на сайт, модифицирование данных на сайте. twitter.com/artalar_dev/st…
Как пример: приложение вставляет свои данные к нам на сайт, для добавления комментариев: chrome.google.com/webstore/detai…
Само по себе ему не интересны наши сетевые запросы.
Защита от плагинов — это сразу несколько разных классов проблем.
Мое выступление на HolyJs holyjs-moscow.ru/2019/msk/talks…
Как раз будет про различные векторы атак и защиту от них.
Вторник
@jsunderhood @xnimorz @hh_ru Привет! Хотелось бы услышать про организационную структуру фронтенда и отдельно про команду архитектуры, какие ответственности и как устроено взаимодействие с фронтенд командами. Если, конечно, дозволено такие детали освещать. Спасибо! Обязательно почитаю про "vanilla js".
Сегодня как раз поговорим о работе и процессах в компании. twitter.com/ggarek/status/…
Как и обещал, сегодня поговорим про тех.деп хх и процессы. Я сейчас работаю в команде архитектуры, где 100% времени занимаюсь техническими вопросами.
Что входит в мою работу? Мне приходит в голову старый добрый мем:

Что есть типичная задача в моей команде?
На самом деле они очень сильно разнятся. Начиная от внедрения SSR для реакта, как отдельного сервиса, и отладкой утечек памяти node.js сервера при 500-ках, заканчивая созданием подхода к работе с иконками, которым я занимаюсь сейчас.
Кстати, организовать удобную работу с иконками на большом сайте — это может быть (внезапно) не самой тривиальной задачей. Интересно было бы почитать про это?
Предлагаю начать с паранойи. И несколько вопросов: Сколько браузерных расширений у вас установлено?
Результаты по количеству плагинов в браузере: twitter.com/jsunderhood/st…
Команда архитектуры занимается всем, что позволит повысить скорость разработки или качество кода. Из того, что первое приходит в голову: инфраструктура окружения, в том числе юнит-тестов, автоматический фетч данных и разбор по редьюсерам при SPA переходах, eslint, babel плагины
Все изменения делаются для всей фронтенд группы, а не локально. Иногда во время таких задач появляются разные open-source плагины. Например, мои коллеги сделали крутой плагин, отображающий понятные и удобные имена React компонентов: github.com/hhru/babel-plu… Он включен и на проде:
Здесь будет тред, о том, как организован технический департамент HeadHunter (большими мазками) >>>
У нас нас есть страница на tech.hh.ru/about.html, где описано достаточно подробно все, какие технологии мы используем, как разрабатываем задачи. Информации много, поэтому выделю наиболее интересные моменты.
Технический департамент на текущий момент — это более 130 человек и 25 команд. Каждая команда — отдельный unit, который может решить задачу от начала до конца.
Поэтому стандартная конфигурация команды это 1 фронтенд-разработчик, 1 бекенд, 1 тестировщик и 1 тимлид. В зависимости от задач команды конфигурация может отличаться
Владение кодом общее. Поэтому если команде, которая занимается работодательскими фичами, нужно добавить что-то в поиск, она не ждет команду поиска, а идет и добавляет сама.
Команды разбиваются по своим ролям: работодательские фичи, соискательские сервисы, поиск, реклама, команды сайд-проектов. Команд, которые занимаются, например, работодательскими фичами может быть несколько.
Бывает так, что какая-то команда больше занимается определенной частью возможностей, например, созданием вакансий. Здесь открывается огромный мир задач. Шаблоны вакансий, типы, настройки, адреса офисов, аналитика — куча всего, что может быть переплетено с другими фичами сайта.
У каждой команды есть product owner, с которым команда прорабатывает задачи. Команда участвует в проработке задач полноценно, а не только как технический консультант.
Большинство задач выпускаем под AБ-тестами. Обычно на проде одновременно включено десятки (а то и сотни) тестов. Есть собственная система аналитики и подсчета метрик.
Полезная-интересная штука: кроме бизнес-задач у нас есть понятие "технического налога" — это термин похож на техдолг, включает в себя задачи на рефакторинг, улучшение кодовой базы, переезд на новые технологии, упрощение потока данных и т.д.
Более того, есть соглашение, что 30% времени работы команды могут тратить на налог.
К предыдущему пункту — еще более хорошая новость, что договоренность про 30% соблюдается.
Код храним на Github, ревьювим код через pull request. Коротко про ревью — любой может участвовать, должен быть один ответственный ревьюер. В идеале ревьюить код должен человек, которому эта часть ближе всего
Релизы ежедневные. Сегодня сделал \ протестировал задачу — можно сегодня собрать релиз или завтра она автоматически попадет в релиз дня.
Самих релизов в день может быть много. Очень много. Они могут быть большими. Пару недель назад было 4 релиза фронтенд части основного сайта в один день, в одном из них выходило около 20 задач.
Это не считая остальных сервисов, которых у нас много (так как идем в стороу микро-сервисной архитектуры).
Тред (@xnimorz)
Тредик с фактами о фронтенд части (компиляция tech.hh.ru/about.html и интересных фактов): >>
Фронтенд делится на 2 стека: старый и новый. Старый это ванильный js + jQuery, на сервере html рендерится через xslt, на клиенте mustache. Новый стек — это почти классическое React-Redux приложение.
Стили пишем в less, используем АНБ подход для разграничения стилей АНБ — верстка независимыми блоками, одно из первый названий БЭМ, которое очень у нас прижилось и очень похоже на классический БЭМ без миксинов и с большим упором на блоки.
На новом стеке включен SSR везде. Миграция отдельная большая тема, о ней поговорим на следующий день
Есть UIToolkit — блоко. Работает на двух стеках и состоит более чем из 120 компонентов. Начиная от кнопок и заканчивая сложными компонентами древовидного выбора с тегами, поиском и т.д. Документирована либа на styleguidist, спасибо @iamsapegin за удобное и расширямое решение.
Кстати, на styleguidist документированы и легаси компоненты. Для написания примеров у нас используется кастомный рендер, который выглядит вот так:
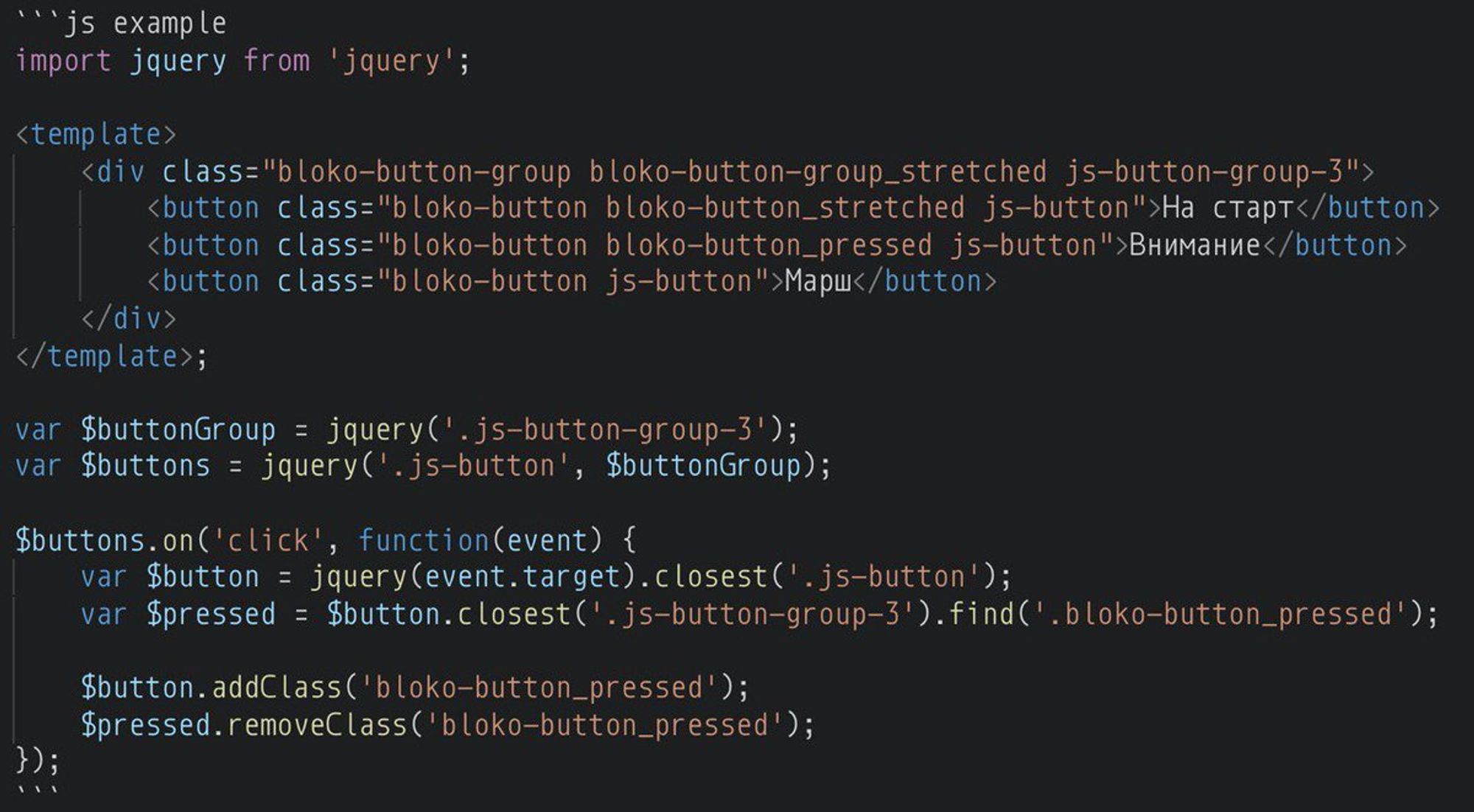
Код транспайлится бабелем (тайпскрипта у нас пока нет). Используем в том числе такие штуки как optional chainig: github.com/tc39/proposal-… и async-await
Есть самописные бабель плагины. Некоторые могут быть полезны всем, некоторые специфичны: github.com/hhru?utf8=%E2%…
Код автоматически проверяем eslint github.com/hhru/eslint-co… — наш конфиг. Для стилей используем stylelint. Prettier настроен на js, css, less, json, md
Все фронтендеры пишут прослойку на питоне — это сервис, который выполняет роль API Gateway. Получить запрос пользователя, сделать 100500 запросов на бекенды (обычно параллельно), собрать воедино и отдать на рендер xslt или React.
Код в прослойке очень простой, веб-сервер c открытым кодом: github.com/hhru/frontik
Юнит-тесты. Их пишем на новом стеке обязательно. Кроме юнит-тестов есть более 8000 сьютов автотестов. Автотесты прогоняются при тестировании задачи, перед выкладкой релиза. Все автотесты проходят примерно за час.
В каждом PR мы сделали индикацию code-coverage в зависимости от base branch. Основное правило — желательно, чтобы покрытие юнит-тестами не уменьшалось с твоей задачей. Вот так выглядит отчет, когда покрытие не изменилось:

Если стало меньше и если увеличилось:
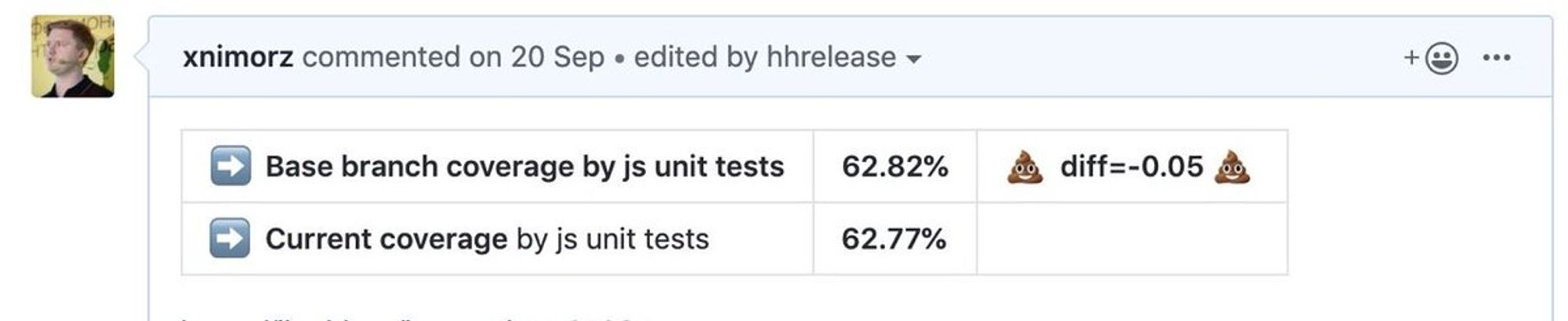

Fun Fact: такой простой прием позволил заметно повысить code coverage
У каждого разработчика, тестировщика в компании есть отдельная виртуалка, со всеми сервисами. Вся разработка сводится к синку кода с виртуалкой. За счет чего у тебя всегда под рукой все нужные сервисы.
Накатка веток, запуск тестов, обновление стенда — все автоматизированно. Например, у меня в 8 утра всегда происходит обновление моего стенда. Я приезжаю на работу — у меня все свежее.
Тред (@xnimorz)
Во второй половине дня поговорим про Kanban, визуализацию процессов и как удобная и хорошая визуализация помогает разработке.
В хх я работаю больше 5 лет. И за это время я сменил 5 команд. В разных командах процессы могут отличаться очень заметно.
Я подумал, что будет интересно посмотреть на процессы, которыми занимаются разработчики и пообсуждать их. Если у вас есть какие-то другие вопросы — велкам :)
Сейчас в ХХ используется Kanban методология. Обычно для новых разработчиков это: стендапы, отсутствие спринтов и прогнозируемость выхода задач. Прогнозируемость нарабатывается через сбор статистики с течением времени. Затем данные за месяц \ квартал обсуждаются на ревью поставки
Кроме разработки (product delivery) все разработчики участвуют в проработке проекта (product discovery). Как должен выглядеть поток задач начиная от идеи и заканчивая разработкой? >>>
В книгах можно встретить понятие бутылочного горлышка (bottleneck). Идея такая: во время проработки отказатсья от идей проще и дешевле, чем во время разработки. Команда привлекается и в роли аналитиков, и в роли тех. помощи (подсказать продакту какие подводные камни могут быть).
Каждая команда определяет свой состав участников на такие проработки. Где-то 2 человека от команды, где-то вся команда, у кого-то — только тимлид. Пара команд даже практикует такую штуку как "проработка за один день".
Команда вместе с продактом разбирает проблему, набрасывает идеи решения и описывает user story. Обычно применяются популярные везде подходы story и impact маппинга. А какие нестандартные подходы к проработке задач вы встречали? Пишите, я буду ретвитить :)
Остальной процесс проработки задачи типовой — построили видение задачи, отдали на отрисовку, декомпозировали, задача упала в беклог.
В хх мы построили систему, которая рисует графики, помечает долгие фичи и позволяет даже "гадать", что происходило с командой в тот или иной момент времени. Хорошая визуализация таких процессов — очень крутая штука. На картинке кумулятивная диаграмма (с вымышленными данными)
Мы используем базовые инструменты — кумулятивная диаграмма, box plot, гистограмму по статусам и сводные таблицы.
Нашел хорошую иллюстрацию, которая описывает что позволяет визуализировать кумулятивная диаграмма:
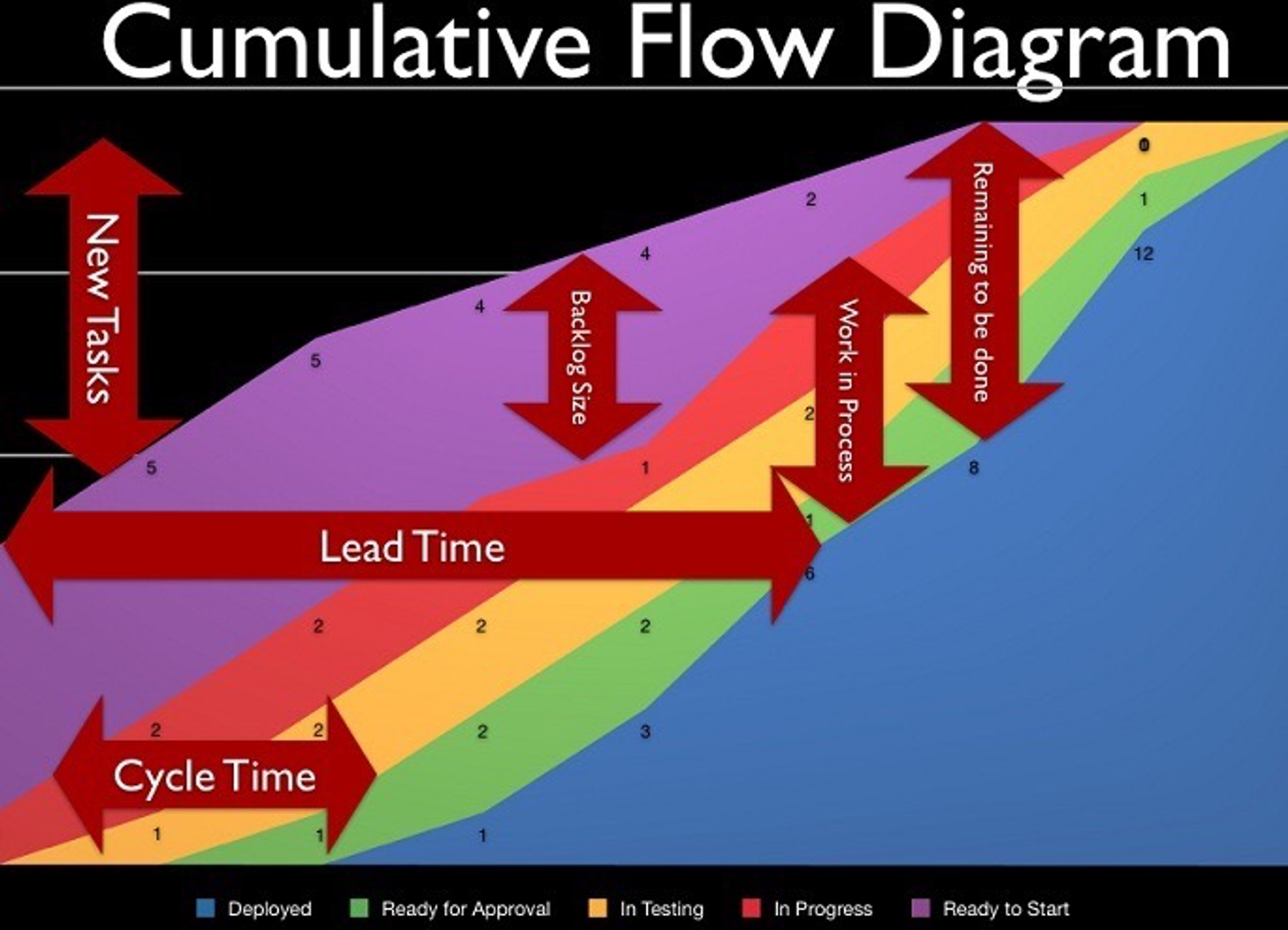
Тред (@xnimorz)
@MrL1n @_bravit @PodlodkaPodcast @mobileunderhood @jsunderhood ещё им не покорён. возможно фронтендеры смогут своими костылями перегородить ему дорогу
Надо звать! :-) twitter.com/seminioni/stat…
Нашёл абсолютно волшебный сайт littlebigdetails.com с клёвыми маленькими фичами, делающими жизнь лучше.
Это великолепно :) twitter.com/govorov_n/stat…
Часто может возникнуть вопрос: а чем отличается канбан от скрама?
Про это есть хорошая статья от Алексея Пименова: medium.com/@pimenaus/scru…
Если говорить на практике, которую замечают разработчики, то это: >>>
Отсутствие спринтов. Никто никогда не пытается "выпустить все задачи в пятницу, потому что спринт заканчивается". Большому спокойствию также помогают ежедневные релизы.
Если у меня задача сегодня протестировалась, то завтра она уже будет на проде. Кроме того, если очень хочется, можно собрать неограниченное количество релизов в день :) Релизы выходят практически автоматизированно.
Более явная вытягивающая система — "запросы" на задачи поступают от команд по мере образования вакуума на этапах разработки. Например, команда договорилась иметь всегда 2 user story в беклоге. Команда проводит еженедельные демо заказчику, на которых синхронизирует статус.
Как только команда берет user story, в колонке "беклог" образуется вакуум. Это сигнал для продакта, что его нужно чем-то заполнить (то есть система вытягивает из проработки новую задачу).
Визуализация — чем лучше визуализирован процесс, тем лучше команда понимает, в каком состоянии она находится, на каких задачах нужно концентрироваться и т.д. Здесь, кстати, есть много интересного.
Тред (@xnimorz)
@jsunderhood А зачем на проде то?
Не нужно при каждом вопросе подключать VPN для стенда, не нужно грепать по проекту — открыл сайт, выбрал нужный элемент — готово, компонент виден, можно с ним работать. Упрощает поиск и разбор кода.
Кроме того, если случается ошибка, в репорте будет указан displayName компонента twitter.com/SanichKotikov/…
Насколько важна визуализация процесса? Я для себя вывел, что хорошая визуализация решает 2 задачи:
Быстрее ориентируешься в приоритетах задач
Быстрее принимаешь решения
Дальше будет тред, основанный на реальных болях, как можно с помощью визуализации упорядочить хаос >>>
Этот тред можно смело будет назвать — "о чем я бы хотел знать про визуализацию перед тем, как стал тимлидом"
Классический подход, который я встречал в куче мест: это когда заводят для задач разработчиков 5 колонок: туду, в работе, ревью, тестирование, релиз. И обычно во время туду \ работы и ревью задача висит на разработчике, а потом на тестировщике.
Тут мы сталкиваемся с первой проблемой. Если мы перевели задачку в тестирование, она тестируется или нет? Что с ней происходит?
Чтобы решить эту проблему, иногда возникает желание добавить метку или комментарий в задачку "ожидает тестирования". Но это желание порочно. Потому что сейчас мы разбираем только одно место. Затем появляется еще одно и еще одно. Становится вот так:

Это плохо тем, что любому члену команды, чтобы понять "а что там с задачей" придется открывать каждую задачу, искать комментарий и т.д. Лучше придерживаться правила "что было в вегасе, остается в вегасе" ой, "что можно визуализировать, лучше визуализировать в одном месте".
Решением может быть разделение колонки Ревью на 2: "ревью: в процессе" и "ревью: готово". В этой системе тестировщик, придя на работу, видит текущие задачи, которые нужно завершить, и свой "беклог" задач, которые можно вытягивать когда появляется вакуум.
Решение легко масштабируется и на другие подобные проблемы. Мы получаем доску, на которой мы понимаем, что происходит. Это полезно как самой команде (легче выбирать задачи, проще договариваться), так и тимлиду.
Вторая проблема: тестировщик находит критические баги в задаче. Выпускать нельзя. Здесь есть разные пути решения. Можно реопнуть задачу и для всех переоткрытых задач иметь свой swimline, либо оставить в текущем статусе, но указать на доске исполнителем разработчика.
Зачем в этом случае такие навороты?
Задачка уже сделана, на нее уже потрачены силы\нервы\деньги\обсуждения. Приоритет такой задачи, скорее всего, выше, чем у других. Поэтому если мы оставляем ее на уровне тестирования — разработчик легко видит такой "блок" и с большим приоритетом переключается туда.
И тут мы подходим к такой штуке как определение приоритетов на доске.
Самый простой и "нативный" способ — это чтение справа налево по строкам. Т.е. мы сортируем наши swimlines по приоритетам — вначале критикалы, потом баги, потом задачи (например).
Члены команды при выборе очередной задачи проходят по этим swimlines и выбирают первую задачу, над которой они работали \ могут взять в работу.
В результате, если тестировщик перевесил задачку на разработчика, то разработчик, закончив текущую работу, открывает доску и видит, что справа у него есть задачка.
Преимуществом такого подхода является отсутствие излишних коммуникаций.
Этот подход можно использовать и для проведения стендапов. Идти по задачкам, справа налево. В теории, это позволяет быстро ответить на вопрос "а что нужно сделать, чтобы задачу быстрее выпустить" и не обсуждать излишние вещи на стендапах.
Мы в двух командах пробовали сделать так для стендапа и каждый раз мы терпели фиаско. Потому что, во-первых, этот подход требует определенной зрелости команды, во-вторых, можно терять в коммуникации.
Тред (@xnimorz)
@jsunderhood Чувствуют-ли себя разработчики винтиками в системе? Процесы - как по книге у Пименова - охренительные. Пол твиттера уже хочет у вас работать.
Хороший вопрос! Если хочется просто "закрывать входящие таски и чтобы меня не трогали" то будет ощущения винтика. Никто не будет бегать и ждать, пока такой человек скажет свои идеи. Если же есть желание — то всегда можно вносить свои идеи. У меня такого ощущения не возникало >> twitter.com/Oleg75113370/s…
HeadHunter не идеален, как и везде есть свои недостатки. Каждая команда может сама донастраивать процессы. Вот прям как по книге — есть в части команд. В другой части процессы могут изменены слегка. В третьей части — процессы могут быть кардинально другие.
Поэтому главный инструмент, как и везде — общение и улучшение команды в которой работаешь, чтобы всем было комфортно, или (если видишь, что в другой команде процессы тебе лучше подходят) поговорить с менеджером о переходе.
@jsunderhood Зачем переводить задачу на тестировщика? QA просто берет из “to verify” и либо закрывает, либо перемещает обратно в “open”.
Переводить на тестировщика не обязательно, особенно, если есть отдельная колонка «ревью:готово», из которой тестировщики берут себе задачи в тестирование.
Ключевая мысль: если тестировщик просто переводит задачу в «open» — это ломает процесс. twitter.com/oburejin/statu…
Потому что тестировщик должен писать в чат или делать какой-то другой call, что эту задачу нужно доделать. Все из-за того, что по внешним признакам задача никак не будет отличаться от других из колонки open.
А сакральным знанием «она уже готова, нужно ещё чуть-чуть» обладает только разработчик и тестировщик. И про эту задачу легко забыть будет на том же стендапе.
Куда как проще тестировщику навесить задачку прямо на доске на разработчика, не меняя этапа. И как только начнётся стендап — это бросится в глаза. Задача в колонке теста на другом человеке. Непривычно. Нужно посмотреть, что там. И дальше окажется, что и стендапа не нужно.
Есть ещё одна причина тестировщика не идти / писать сразу в чат. Это асинхронность коммуникации. Разработчик может быть сосредоточен на какой-то задаче. Если тестировщик придёт ногами к разработчику — он вырвет разработчика из контекста.
Правильно настроенная доска работает как single source of truth — сама может разрулить коммуникацию.
Тред (@xnimorz)
@jsunderhood Мы скорее не сталкивались с необходимостью это знать, на долго они там не задерживаются всё равно.
Хороший пример того, что не существует единого рецепта для всех.
Кому-то дополнительные колонки могут оказаться излишней информацией. И ничего не мешает при появлении необходимости пересматривать решение twitter.com/oburejin/statu…
@jsunderhood @boriscoder Делается очень просто: .parent-class :global('.child-class') Подробнее: habr.com/ru/post/438834/
Клево! Вы все также создаете глобальный класс, но везде, кроме .parent-class он не будет иметь смысла, так как селекторы будут по типу .parent-class.unique .child-class. Чуть расширил пример с демо svelte.dev/repl/4aef873d9… twitter.com/PaulMaly/statu…
Главное помнить, что это все еще css и если вы создадите просто :global(.child-class) то эти стили также применятся.
Но используя любой фреймворк нужно не забывать, что, например, в данном случае это все еще css и он так работает.
В моей карьере фронтендера было 2 жестких бага, на которые я убил кучу времени (примерно по 2 месяца) и понял, что без внешнего вмешательства их практически никак не исправить. И в обоих случаях было два фактора, которые все усложняли: идеализм и жадность заказчика. 👇
Страшилки на ночь :) twitter.com/mr_mig_by/stat…
Среда
Вчера я спрашивал про иконки — было бы интересно послушать, что там нетривиального и как с ними работать. Иконки, да и куча подобных задач имеют похожий флоу. Это базовые ограничения, которые будут справедливы для большинства сайтов. И есть специфика конкретного сайта, соглашений
Тред про иконки. >>>
Ограничения в задаче: есть базовые иконки, которые используются везде. Есть специфические иконки, которые выполняют одну задачку и их не планируется использовать где-то еще. Есть специфические для платформы.
Сверху добавляем браузерную поддержку и желание, чтобы иконки кешировались, реиспользовались и работали на двух стеках: xslt + mustache, react. Последнее уже наша специфика, но все остальное справедливо для большинства проектов.
Накидываем, прототипируем варианты:
Inline svg. Идея проста: каждую svg вставляем inline в код. fill, stroke убираем и будем стилизовать иконку через css классы.
Чтобы просто было использовать в react пишем свой loader.
Код прототипа для inline варианта (вместе с кастомным webpack loader): gist.github.com/xnimorz/8dfe0c…
Лоадер направляем на .svg иконки.
Выглядит просто и легко, но каждая иконка — это куча тегов в DOM, а значит куча данных, которые используются при SSR, увеличение количества DOM нод.
Вроде бы сам подход удобный, но что-то не хочется.
В защиту решения: можно сделать поддержку многоцветных иконок, анимацию цветовых переходов.
Можем улучшить этот вариант и использовать inline svg + use директиву.
Идея такая: на этапе сборки превращаем все иконки в одну большую мега-иконку, где весь контент описан, например в
<symbol /> теге. Вставляем эту иконку на страницу (она будет не видна для пользователя), а все реальные иконки просто используют тег <use />Код становится проще, нам уже не обязательно делать кастомный лоадер. Достаточно обычного react-компонента: gist.github.com/xnimorz/543dc8…
Вместо одной большой мега-иконки можно использовать другой подход: в компоненте icon храним singleton-Map, в ней отмечаем, какая иконка была использована.
Если добавляется новая иконка, то вставляем эту иконку через
symbol, помечаем в singleton и добавляем реальное использование через use.
Этот подход избавляет нас от необходимости клеить все в одну иконку и делает подгрузку иконок на странице ленивой.Главная проблема подхода: у
<symbol> должен быть id. А значит мы получаем опасность пересечений, если иконки не сосредоточены в одном месте и мы не берем их id по пути к файлу. То есть мы приходим к глобальной области видимости, от которой так стараемся в том же css уходить.Можно для иконок сделать решение аналогичное подходу css-modules и добавлять хеши например. Но мы начинаем строить космические корабли и переусложнять архитектуру.
Сама идея inline svg + use хороша и для многих проектов может зайти. Этот подход экономит и размер данных, и имеет хорошие возможности кастомизации.
Спрайты. Старые-добрые спрайты. Сама иконка выглядит примерно так: gist.githubusercontent.com/xnimorz/e0f107… Через use задаем состояния иконки и через background-position управляем тем, какую иконку увидит пользователь.
Теряем удобные анимации по сравнению с предыдущими случаями, получаем возможность работать с многоцветными иконками и отсутствуют глобальные имена.
Если вы не поддерживаете "старые" браузеры типа IE11, то можно выбрать хипстерский способ через filter. Работает очень просто, вставляете иконку через background-image одного цвета и фильтрами настраиваете нужный вам цвет.
Здесь есть даже готовый калькулятор таких стилей codepen.io/sosuke/pen/Pjo…
Главные минусы: вас будут не очень сильно любить за стили вида: filter: invert(17%) sepia(32%) saturate(5440%) hue-rotate(344deg) brightness(89%) contrast(93%); Также не работает в старых браузерах и поддержку нескольких цветов настроить будет сложно.
Здесь этот способ описан подробнее: css-tricks.com/solved-with-cs…
Плюсы — удобно, все средствами css.
Можно использовать css mask и затем через background-color задавать цвет. способ крайне простой, и нативно понятный, но с поддержкой все еще хуже caniuse.com/#feat=css-masks. И иконки в этом случае должны быть одноцветные (или градиентные)
Можно сделать свой иконочный шрифт. Про его проблемы не писал разве что ленивый. (отложенная загрузка, разное отображение в разных системах, браузерах и т.д. и т.п.)
Какое бы вы решение выбрали?
🤔
60.6% inline (c use или без)🤔
22.1% Спрайты🤔
5.8% filter или mask🤔
11.5% Свой вариантТред (@xnimorz)
@jsunderhood Удобство это понятно, а что с оверхедом на размер бандла? Средняя длина имени - 50 букв, то есть 64 байта на компонент, с учётом displayName и кавычек. Для 100 компонентов это будет уже 6 килобайт, что немало
Сам бандл разбиваем на chunks по странице. Общий код для нескольких страниц выносится отдельно. В итоге:
оверхед на размер данных для отдельной страницы компенсируется удобством.
4-8 кб данных на страницу на 95 перцентиле не увеличивают заметно времени TTI twitter.com/justboriss/sta…
Мы проводили ряд АБ тестов направленных на улучшение и деградации производительности клиентского приложения, с целью выяснить влияние перфоманса на бизнес-показатели
Про перфоманс планирую отдельно поговорить, но если коротко, то нам наиболее критично это fmp.
И опять же данные сжимаем brotli, в итоге оверхед на страницу — меньше
В опросе про иконки с большим отрывом лидирует вариант использовать inline иконки (с use тегом или без).
Расскажу о наших метаниях в выборе подхода: >>>
Если сейчас попытаться оценить решение, то
по экономии размера, самыми эффективными будут решения через filter или mask
По вариативности расцветок — самый простой вариант — использование спрайтов.
Inline вариант с use — также хорошо экономит размер, но хуже, чем filter или mask
Правильный выбор между этими решениями сделать сложно. Субъективно меня очень тянет к решениям с inline + use, filter или mask. Последние два варианта отпадают потому что IE11 и Android 4.4.
Если вы не поддерживаете эти браузеры — рекомендую посмотреть в сторону filter или mask для иконок. Делается очень просто и они лучше всего экономят память.
Выбираем из оставшегося.
Если рассматривать вариант просто inline без use. На моменте, когда вспоминается, что кроме React у тебя есть еще mustache и xslt и для этих двух шаблонизаторов нужно писать свои обертки или precompiled template понимаешь, что это будет очень высокий оверинжиниринг.
В любой задаче приходится искать баланс. Решение должно позволять очень просто вставить иконку, но не должно быть крайне сложным и запутанным. Иначе мы повышаем стоимость поддержки решения
Пробуем вариант с inline svg + use. Само решение простое: мы инлайним + используем use при первой вставке иконки на страницу, а при повторном используем только use. Как писал выше, для нас основная проблема была с пересечением id для иконок.
Окей, это решается именем иконки — нам же все равно компонент вызывать с уникальным именем. А чтобы названия не пересекались, можем класть иконки в одну папку.
Такое решение очень хорошо зайдет, особенно, если у вас single source of icons 😀.
Поэтому, если задаетесь подобным вопросом, то решение inline svg + use — рекомендую к рассмотрению :) Его просто внедрить и недорого поддерживать.
Но на большом сайте можно столкнуться с тем, что самих иконок большое количество. Есть иконки UIToolkit, иконки относящиеся к определенному сайту, специфические для определенных мест.
Если слить все эти иконки в одно место, то получится каша. Это не обязательно всегда плохо.
В итоге, получаем, что у нас есть потенциальное место для коллизий и если не сводить все иконки в одно место при этом подходе — риск увеличивается.
Остается вариант со спрайтами. Он дает чуть больший размер бандла по сравнению с inline + use и добавляет сложностей в анимации переходов (но потенциально они все равно возможны). В остальном есть и плюсы — цветные иконки делаются сильно проще, чем в других вариантах
Возможные состояния у нас генерируются на less.
Выглядит это так: миксину приходит набор состояний, например
.abstract-icon-kinds(default action primary secondary);Затем через рекурсию создаются модификаторы:
icon_action, icon_primary icon_secondary и модификаторы для hover, focus по типу icon_highlighted-actionСпецифические иконки для сайтов генерируются по аналогичному механизму. UIToolkit предоставляет миксин, который сгенерирует нужные классы.
Здесь вспоминается доклад Вадима: youtube.com/watch?v=CaDnbO…
Мораль этой истории?
У нас есть N подходов и ни одного идеального. И это просто вставить иконку на страницу.
Справедливости ради сказать, если у вас нет поддержки ie11 и прочего, то inline + use, filters или mask вам хорошо подойдут
Тред (@xnimorz)
Давайте сегодня поговорим о миграциях.
В случае в хх мы мигрируем с xslt + vanilla js + jquery на react стек.
Я подумал, что интереснее всего будет разобрать миграцию в формате вопрос-ответ, а потом пойти в специфические задачи.
Я, скорее всего, не открою ничего нового в самой миграции. Поэтому короткое резюме-спойлер:
Мы переводим код на реакт постранично. Отдельные элементы на страницах не переводим.
Всегда будет или легаси страница, или реакт страница. Обвязка (хидер и футер) у нас везде легаси >>>
Микрофронтенды мы не делаем. Вместо этого — четкая структура проекта. Выглядит вот так:
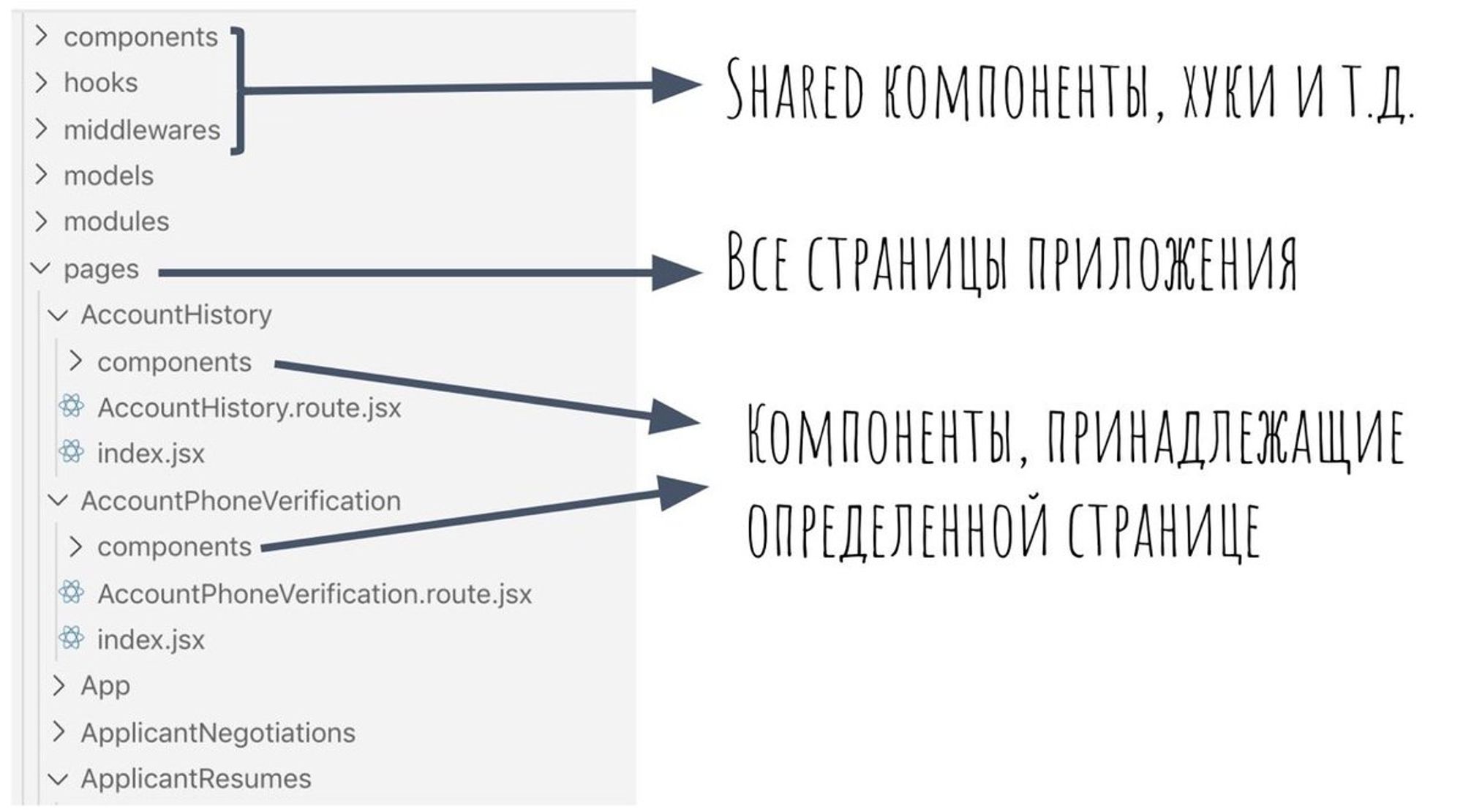
Каждая страницы — это отдельный chunk. На каждой странице, прямо внутри pages/PageName/component хранятся компоненты для каждой конкретной странице.
Если компонент используется больше, чем на 1 странице, то он переезжает в shared.
Chunk загружаем при запросе страницы. В отличие от микрофронтендов, у нас получается единый набор библиотек, что экономит размер бандла.
Так как при подобном переписывании кода получается много, он также выходит под фичей на часть пользователей. Если находятся ошибки, фичу отключают, ошибки правят и выкладывают снова.
Тред (@xnimorz)
Зачем вообще нужна миграция?
Скорость разработки — на новом стеке проще декомпозировать компоненты, люди находятся внутри одной технологии, четкое разграничение потоков данных.
Для хх это позволяет меньше тратить время на "а где этот кусок логики должен лежать" и "а откуда это событие прилетело".
Поддержка. Также вытекает из того, что поток данных четко направлен, все изменения проходят через единое место.
Поток данных проще контролировать => проще разбирать проблемы => разработчик не тратит время на распутывания клубка.
Порог входа. У меня есть стойкое ощущение, что сейчас людей, которые больше хотят писать на условном реакте, проще найти, чем хороших xslt специалистов :)
Хайп. Это момент, когда на рынке разработчики начинают крутить носом — у вас нет react, я к вам не пойду. Как бы это не странно бы звучало, но рынок разработчиков также диктует правила игры.
Тред (@xnimorz)
Главная проблема миграции — бизнес хочет выпускать бизнес задачи, разработчики должны балансировать между техническими и бизнесовыми задачами и еще дублирование коде во время переходного периода.
Какой алгоритм перевода страницы?
Вначале нужен фундамент. Это вся инфраструктра — роутинг, дата-слой, разделение по чанкам, какой-то ctrl+c, ctrl+v гайд, как сделать новую страницу.
>>>
На этом фундаменте можно строить страницу.
Обычно здесь все происходит по типовому сценарию: посмотрели какие компоненты используются на странице, декомпозировали, переводим. В процессе перевода осознаем, что ошиблись со сроками, дооцениваем.
Что при переходе важного?
Наиболее критическим моментом для нас является наличие SSR. Потому что это SEO, это хорошее FMP (о нем и о том, как мы контролируем клиентские метрики мы поговорим отдельно).
Тут мы подходим к важной теме SSR (server side rendering).
Здесь мои коллеги уже писали о SSR в хх habr.com/ru/company/hh/…
А также я косвенно упоминал это в моем выступлении в GetItConf: youtube.com/watch?v=bZfULA…
Из интересного: >>>
node.js не занимается походами на бекенды. Мы сделали SSR as a service. То есть есть питонячье приложение, которое ходит на бекенды, за сессией пользователя, и когда все данные готовы, оно формирует JSON и делает POST (PUT) запрос на Node.js сервер.
Урл у нас всегда один
/render. Информация о реальном урле и данных лежит в body запроса.
Схематично это выглядит вот так: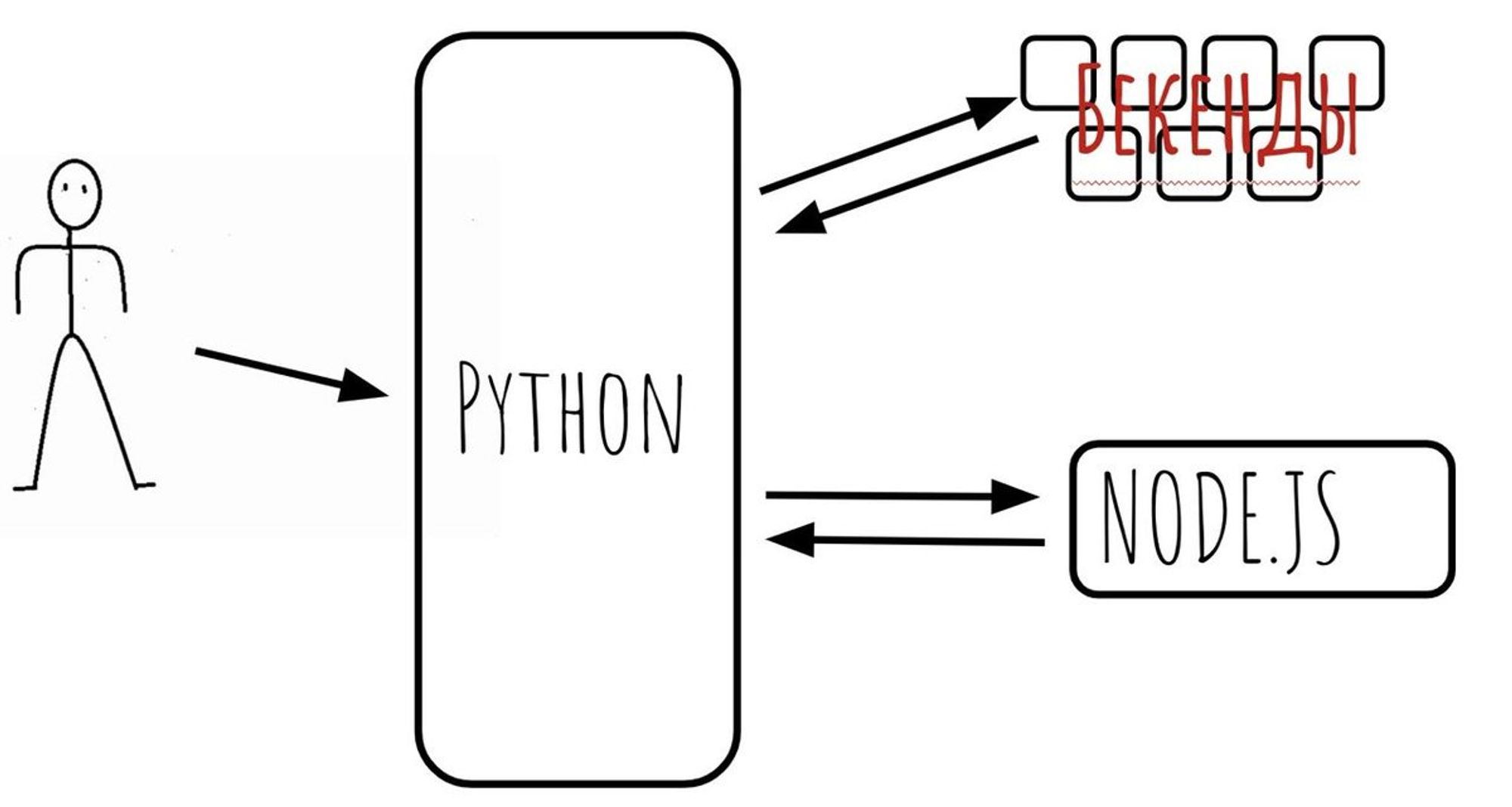
На сервере крутится Koa (выбирали между express, koa и hapi). express не взяли — были проблемы в секьюрности, hapi не взяли — больше экспертизы в Koa было.
Кроме того, api koa отдалено похож на api нашего питон-приложения, за счет чего разработчикам проще было бы освоиться в новом окружении.
Каждый инстанс ноды запускает внутри себя Clusters по количеству ядер выделенных контейнеру: nodejs.org/api/cluster.ht…. Количество ядер определяется и прокидывается конфигом. Сама нода живет в docker контейнере. Менеджится и раскатывается это все через ansible плейбуки.
Код вызова рендера очень простой умещается на десяток строк вместе с обработкой ошибок: gist.github.com/xnimorz/2a6283…
То есть, что мы сделали: весь клиентский js собрали обычным webpack и вызываем render, скармливая initialState приложения.
Это позволило нам сделать SSR не переделывая специальным образом клиентскую часть (а вызовы window.something и подобные штуки у нас в рендер функциях и других подобных местах запрещены).
Мониторим сервер через okmeter: okmeter.io
Контейнеров node.js много и тут появляется задача: как выпускать обратно несовместимые релизы? Когда в питоне с новым релизом мы начинаем по-другому формировать json, отправлять другие поля, или не отправляем часть полей.
С одной стороны можно сохранить обратно-совместимые релизы и на такие изменения делать 2-3 релиза паровозиком (друг за другом). Но это неудобно.
Хочется это все делать за 1 релиз.
Тут на помощь приходит "хитрый" метод: у питонячьего приложения и node.js рендер сервера единая версия. То есть после каждого релиза версия и node.js приложения и питонячьего сервиса будет условно 2.0. А до релиза была, например 1.1.
Делим группу Node.js серверов на 2 и вначале катим релиз на половину машин.
Когда релиз раскатился, катим релиз на питонячье приложение.
И только затем раскатываем на оставшуюся часть машин.
Выглядит это вот так:
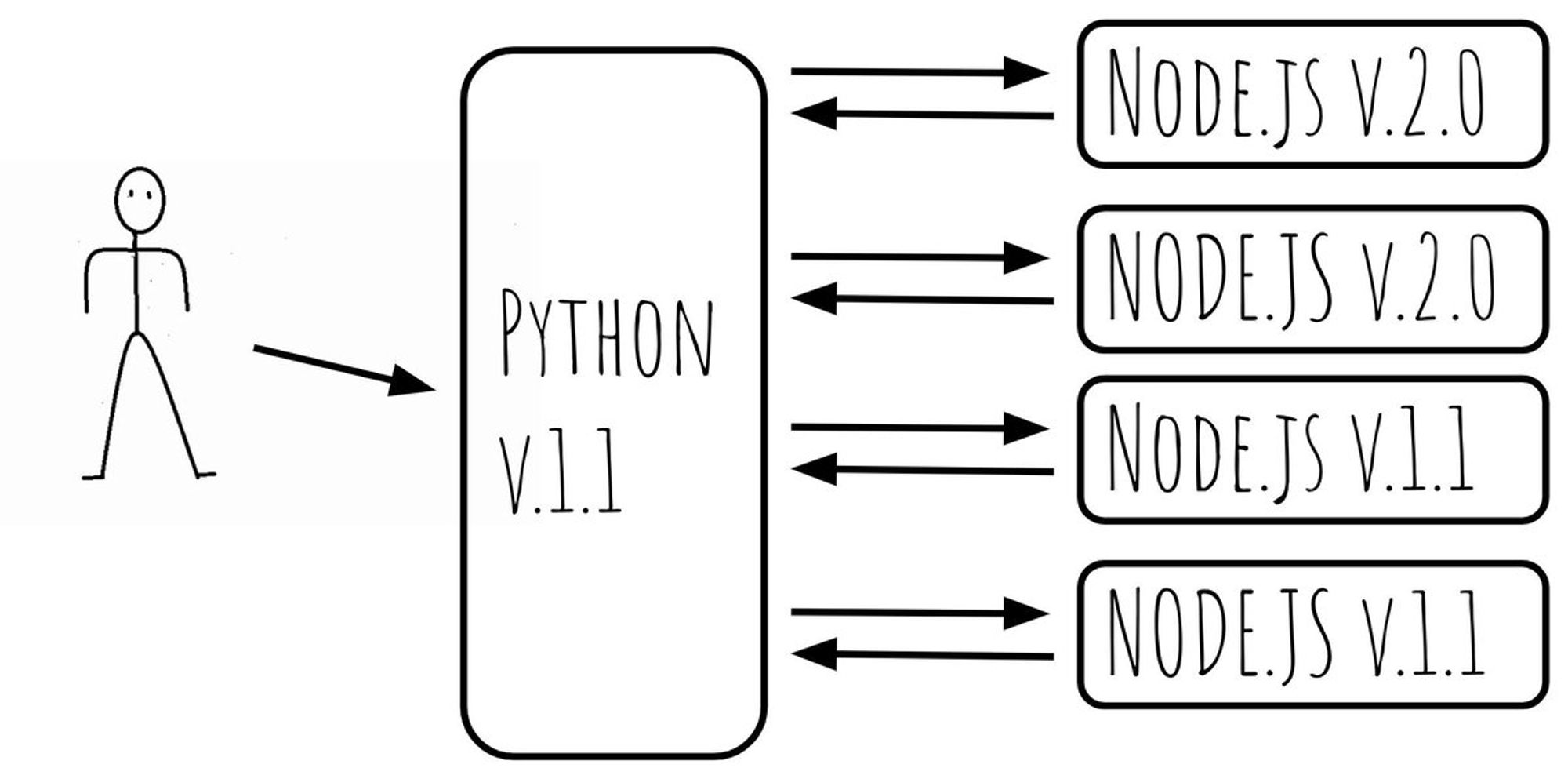
Остается посыпать решение инфраструктурой:
питон приложение идет в node.js с указанием версии. Node.js перед рендером сравнивает: а совпадает ли моя версия и версия питона? Если да, то просто рендерим и отдаем результат.
Если нет, отправляем 503. Питон получает 503 и пытается заретраить запрос на другой сервер. количество ретраев = количество инстансов / 2 + 1.
Можно пойти дальше и завести единое место с конфигом, которое будет балансировать и знать, где-какая версия раскачена, но мы пока до этого не дошли, это больше планы на будущее.
Тред (@xnimorz)
Если у вас есть еще вопросы про SSR или миграцию — пишите, с радостью отвечу на что смогу :)
@jsunderhood А делали какое-нибудь сравнение этого подхода с подходом «1 процесс (ядро) на 1 контейнер» (то есть, без кластера)?
Да, когда только внедряли проверяли, насколько будет рост, если использовать cluster и будет ли он.
При включении 2 кластеров (на контейнере, которому выделили 2 ядра) рост был практически в 2 раза (если быть точным, то 1.98) по сравнению с просто 1 процесс на 1 контейнер. twitter.com/FapSpirit/stat…
@jsunderhood Но это же ваще оценочное мнение, так ведь? Которое вообще ничего общего может не иметь с реальной жизнью.
Отчасти да, отчасти нет. Поясню, крайне сложно для суждения привести абсолютно идеальные данные. Никто не будет делать одинаковую фичу на двух стеках. И здесь обычно вступают суждения из разряда: датафлоу проще — наверное, быстрее напишем. Эти суждения субъективны. twitter.com/Marat_Galiev/s…
В то же время, мы измеряем lead time всего процесса разработки и lead time только разработки. Если выбрать задачи, которые делала команда на старом стеке на определенной странице до (их много) и после перехода и сравнить их lead time, то можно сделать некоторые выводы.
Это не на 100% идеальный способ, но чем больше задач делает команда на странице, тем более репрезентативна выборка. Если команде интересно, они легко могут построить графики и сравнить это.
И тут я сам же поломаю свой довод :) во время переписывания происходит ещё рефакторинг кода, что упрощает дальнейшую разработку. Поэтому однозначный ответ: нам помогла такая-то технология дать нельзя, это субъективизм.
Важный момент: мы измеряем lead time не для сравнений, а для рефлексии, чтобы понимать, какие вопросы и трудности у команды были.
Тред (@xnimorz)
@jsunderhood А что происходит с глобальными задачами из разряда - обновить какую-то либу на следующий мажор по всему порталу? Просто централизованно решается, что нужно сделать как top-down решение?
Все зависит от размера проблемы. Если задача достаточно большая, то работает +/- так:
Задача описывается в jira, ставится тег tax
>>> twitter.com/blvdmitry/stat…
Определяется приоритет задачи. Раньше мы пытались использовать для приоритетов RAF (Risk assessments framework) @pimenaus рассказывал про это: youtube.com/watch?v=JI4w57… Но в итоге, у нас не прижилось
Команды, если планируют взять тех. задачу видят все задачи и выбирают исходя из приоритета + времени, которое они готовы потратить (высокоуровневая оценка)
Если команда архитектуры понимает, что вряд ли кто-то возьмет эту задачу в ближайшем будущем, а профит от задачи есть: берет себе в беклог и делает.
Для синка у нас есть 2 типа встреч. Тимлидский статус-синк и синк фронтенд группы. (это помимо внутрикомандных стендапов и другой коммуникации).
Тред (@xnimorz)
@jsunderhood Я обычно использую <img src=my.svg> в доме, а затем динамически подгружаю и заменяю инлайновым <svg>
Еще один способ решения задачи :) twitter.com/shrpne/status/…
Четверг
@jsunderhood Ну а как вы на питоне вырезаете все фетч запросы что бы сходить на сервер за данными?
Расскажу как работает роутинг:
Для роутинга используем обычный react-router. Для SPA переходов между страницами есть middleware, которой на вход приходит информация о запрашиваемом урле. Она делает GET запрос за данными и запрос за chunk страницы параллельно. twitter.com/b2whats/status…
Выглядит это вот так: gist.github.com/xnimorz/5a2783…
preload для компонентов вытаскивается через React-loadable
За chunk с данными ходим, чтобы данные в стор записались в тот момент, когда chunk будет предзагружен и страница сразу рендерилась. То есть мы сделали, чтобы эти запросы шли в параллель, а не последовательно.
Чтобы серверная нода не слала запросы, мы в коде конфигурации стора проверяем наш environment и в случае сборки для сервера стор конфигурируется без этой middleware.
Тред (@xnimorz)
Какое бы вы решение выбрали?
Результаты голосования по иконкам. 60% за вариации inline иконок twitter.com/jsunderhood/st…
@jsunderhood Еще в защиту такого подхода - большинство проблем можно нивелизровать, загрузив иконку через iframe. Логика такая - грузим iframe с иконкой, а саму иконку потом достаем из iframe и инлайним.
Еще про иконки :)
Но мне такой вариант кажется усложнённым, по сравнению с ленивой загрузкой и использованием use на местах twitter.com/lionskape/stat…
Понадобилось отрендерить табличку 500х50 ячеек, клик на каждую ячейку тогглит её в инпут и обратно. React убивает браузер, Svelte навешивает эвенты 7 секунд. Нативный JS с event delegation просто божественно работает)
Я решал похожую задачу на реакте, и учитывая, что в реакте есть встроенное делегирование событий, проблема может быть в ререндерах компонентов. Здесь очень хорошо помогает правильная настройка PureComponents и кеширование колбеков/данных. Для свелте то же делегирование спасает twitter.com/rm_baad/status…
Ну, и в подобных историях наиболее правильный подход: это сделать замер через performance и посмотреть, на что действительно уходит процессорное время. Внезапно может оказаться, что это даже с layout проблемы.
Хм. My bad. Где-то накосячил и нагрешил на React. Он вполне себе отрендерил 25к ячеек и никто не умер @jsunderhood @andrey_sitnik
К прошлому треду про производительность либ: twitter.com/rm_baad/status…
Мы тут немного поговорили про оптимизацию, в дополнение расскажу 3 маленьких и очень простых, но интересных момента в реакте о setState в хуках, контексте и useLayoutEffect с примерами:
При вызове setState, который мы получаем из хука useState реакт проводит сравнение prev и next результата (==). Если они не равны, то только в этом случае компонент будет отправлен на ререндер
Это означает, что если вы сделаете что-то вроде const [a, setA] = useState(1); ... setA(1);, то компонент не будет перерендерен.
Но если ваш родитель ререндерится, то child также будет ререндериться, никаких сравнений props не будет, все полностью предсказуемо.
Это все при условии, что компонент не Pure, не обернут в memo.
Вот тут небольшой пример codesandbox.io/s/fervent-shad…
Я пару раз сталкивался с непониманием коллег, почему в стейте поведение одно, а в пропс другое. Дело в том, что одно происходит еще до того, как компонент будет помечен грязным, а второе — по сравнению условного shouldComponentUpdate, который без Pure, memo будет всегда true.
По этой причине, недостаточно просто обернуть все мемоизацией. Чтобы избежать вызова render функций, компонент должен быть pure или обернут в memo. В некоторых случаях можно иметь кастомную SCU функцию.
Для функциональных компонентов memo также принимает второй аргумент. Он нужен для кастомного компаратора, аналогично, если бы вы определили свой SCU в компоненте-классе.
Важный момент, о котором многие забывают: контексту плевать, обернут ли у вас компонент в memo или он pure. Если вы внутри компонента используете useContext или contextType, то как только Context.Provider сетит значение, компоненты будут обновлены.
Проверить и поэкспериментировать очень легко: codesandbox.io/s/agitated-wil…
Обратите внимание, что изменение контекста не просто обновляет компонент, но он получает еще и самый последний prop.
Все привыкли использовать useEffect для сайд-эффектов, каких-то DOM расчетов. Может появиться вопрос: а почему я вижу "моргание"? Оно происходит, потому что useEffect происходит после физической отрисовки. Т.е. у вас уже пройдет layout, paint, composite.
Если хочется рассчитать ДО того, как компонент отрисуется (как раньше с componentDidUpdate), то стоит использовать useLayoutEffect. В этом случае у вас произойдет только layout.
Разницу можно прочувствовать на простом примере: codesandbox.io/s/997j4
Hint, если в codesandbox хочется снять performance можно открыть урл, который они предоставляют: 997j4.csb.app и можно увидеть разницу при рендере.
useEffect:
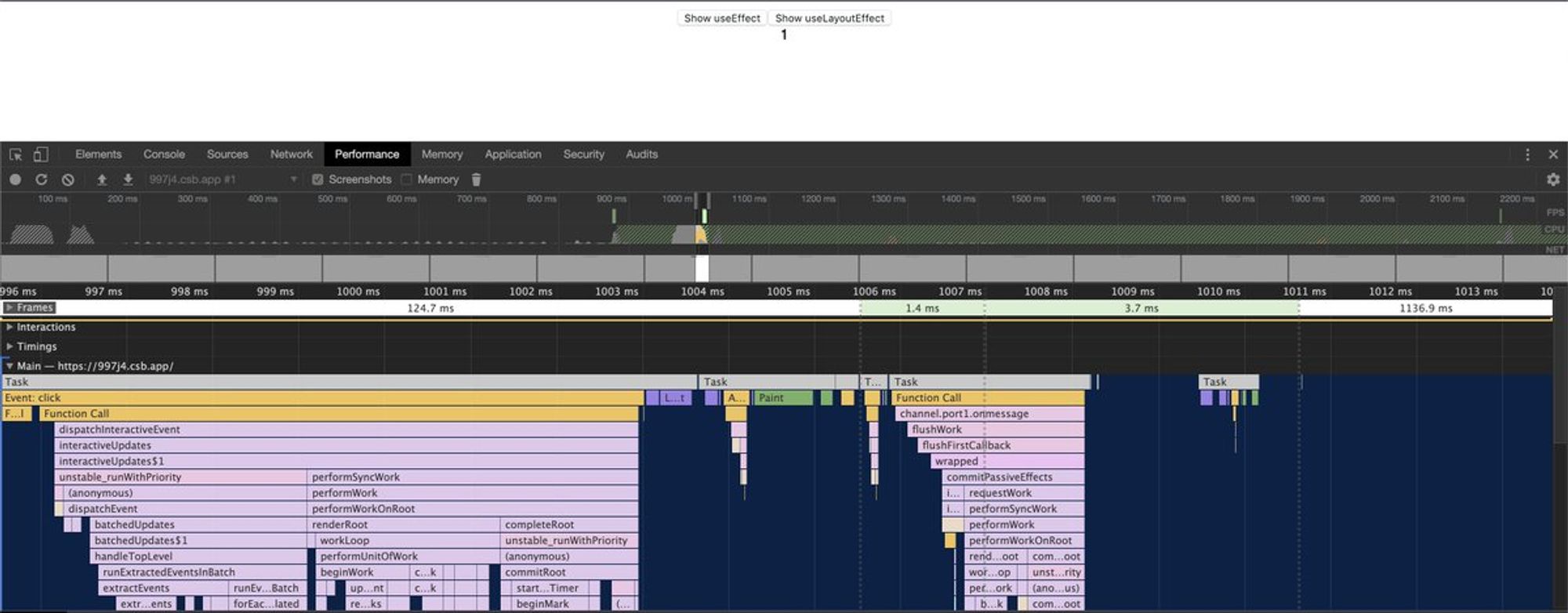
UseLayoutEffect:
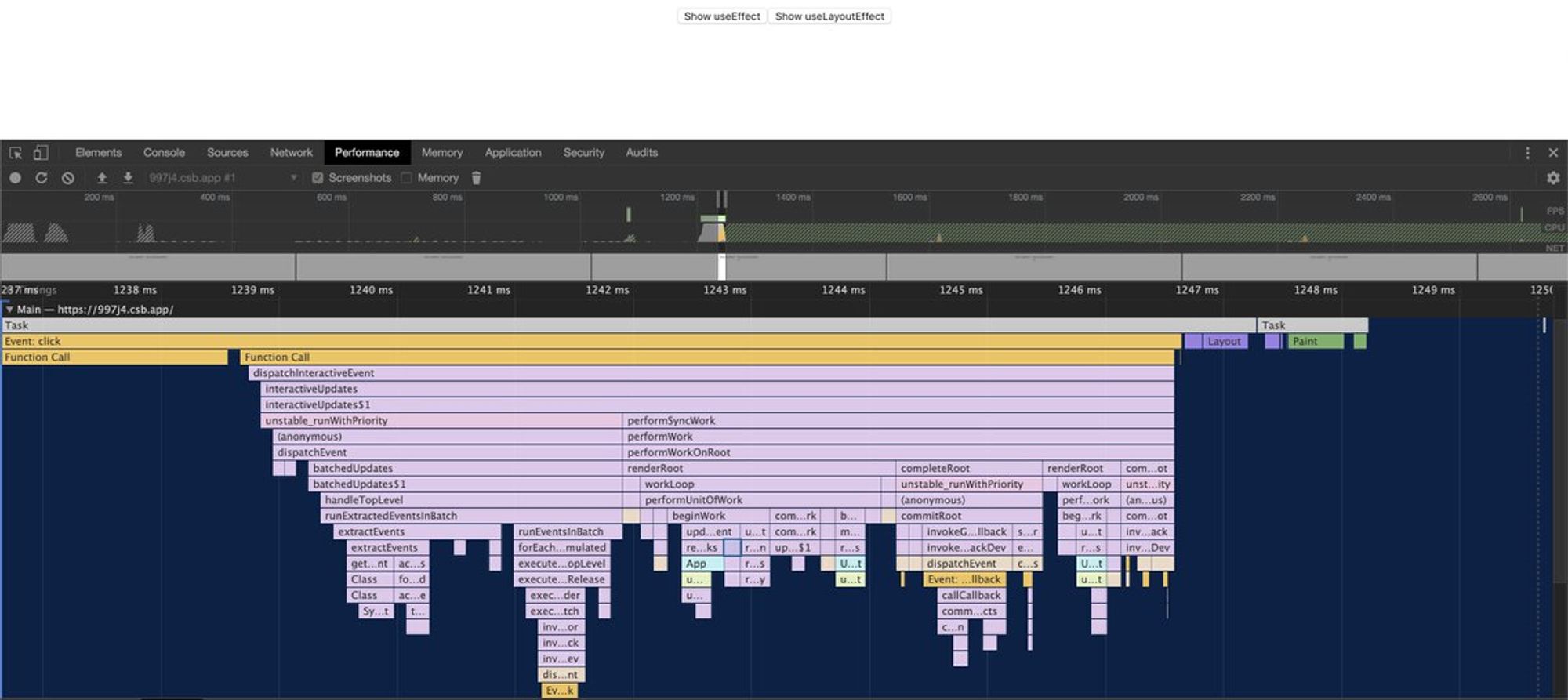
Обратите внимание на разницу в количествах и характере paint :)
Важный момент, о котором многие забывают: контексту плевать, обернут ли у вас компонент в memo или он pure. Если вы внутри компонента используете useContext или contextType, то как только Context.Provider сетит значение, компоненты будут обновлены.
Напутал с ссылками на примере. Правильная ссылка вот: codesandbox.io/s/fancy-feathe… twitter.com/jsunderhood/st…
Для истории с контекстом правильная ссылка codesandbox.io/s/fancy-feathe…
Тред (@xnimorz)
@jsunderhood Будет тред о том как стать хорошим специалистом? (не xslt 😁 спецом, а в общем)
Вчера был вопрос о развитии. У меня нет хорошего ответа на него. Поэтому дальше будет тред о том, как я представляю себе развитие.
Расскажите о своем опыте, я поретвичу :) twitter.com/Oleg75113370/s…
Для меня есть несколько больших мазков в градациях. Джун => Мидл => а вот тут все сложнее.
Сюда традиционно добавляют senior, что это человек, который может взять задачу, проанализировать, выбрать подходящий вариант в системе ограничений и привнести ценность, по дороге выполнив пару сайд-квестов.
Сделаю отдельные треды для развития начального и дальнейшего, сюда потом добавлю ссылки
Давайте с вопросом развития начнем с простого и дальше будем двигаться к сложному. Начнем об обучении джунов. В хх я пришел зеленым студентом больше 6-ти лет назад. Пришел я в школу разработчиков. И сейчас преподаю в ней. school.hh.ru.
Школа устроена следующим образом. На входе будущие студенты решают несколько задач онлайн, затем офлайн интервью. Это задачи на логику и довольно простые типовые задачи на алгоритмы. Писать код не обязательно, главное рассказать как бы вы решали такую задачу.
Как подготовиться к подобным интервью как раз писал предыдущий автор этого твиттера :)
Сама школа разделена на 2 части: лекции и работа над проектом. Лекции проходят 2-3 раза в неделю.
В прошлом году лекции записывали: youtube.com/watch?v=7tULJl…
Обучение идет по 2-м направлениям фронтенд и бекенд. Бекенд на java. Время одной лекции не определено четко, у каждого лектора свои лимиты, о которых он заранее сообщает студентам.
У лекций есть ДЗ. Я обычно стараюсь после выдачи ДЗ отвечать на вопросы, проводить ревью решения студента как можно быстрее. Это правило действует до дедлайна, который составляет 2-4 недели от момента ТЗ. Общение ведем в слаке, ревью решений на гитхабе.
Список моих лекций есть здесь: xnim.ru/projects/schoo…
У меня была пара веселых моментов. Провожу лекцию по базовому js, в конце даю домашку. Добираюсь до дома (мне ехать 1,5 часа) и ровно в момент, когда закрываю дверь, мне студент присылает решение. К слову это оказалось лучшим решением :) И нет, его он не списывал :)
Вторая история. Мои лекции часто расположены перед НГ. В таких случаях я даю дедлайн в новогодние каникулы плюс 2-3 дня. Решение пришло 31 декабря в 23:00. Ревью студент получил в течение 15-20 минут.
После блока лекций начинается практика. Студенты делятся на группы и занимаются школьными проектами. Я в свое время делал прототип фронта поиска в хх. Над проектом студенты работают 3 месяца, и обычно это не фул-тайм и даже не парт-тайм работа. В свободное время.
Эти проекты нужны, чтобы вчерашние студенты попробовали работу в команде, у них появились первые конфликты (возможно), первые совместные обсуждения.
В последних двух школах студенты делали проекты, которые потом нашли свое использование. В школе 2017-2018 года я был ментором проекта, а ребята, которых мы менторили работали на полноценной парт-тайм работе в офисе.
Также знаю, что есть стажировки у avito start.avito.ru/tech, школа интерфейсов яндекса yandex.ru/promo/academy/… Возможно еще что-то?
Не могу не упомянуть очень крутой кейс от @idelpivnitskiy youtube.com/watch?v=Kw1gQT…
Идель, привет :) Кстати, Идель также участвовал в школе хх.
Тред (@xnimorz)
С началом пути в разработке разобрались. Дальше от средних-крепких джунов в мидлы и развитие мидлов. Это тот момент, когда человек попал в разработку, занимается формошлепством, решает задачи и многое другое. И в какой-то момент у людей появляется вопрос: "А как мне развиваться?"
В части компаний есть менторы, где-то этим занимаются тимлиды, где-то делают основательный подход с составлением ИКР (индивидуальная карта развития). Где-то вообще ничего нет.
Мне сложно дать рецепт, у меня нет правильного ответа на вопрос. Только мои личные наблюдения. Мне кажется, что развитие можно получить, взяв ответственность. Я могу ошибаться, но кейсы, которые я встречал сильно указывают на это.
Хочешь прокачаться во фронтенд скиллах — возьми ответственность за часть проекта, стань мейнтейнером страниц или проекта. Почувствуешь ответственность, начнешь оценивать задачи, управлять техническим развитием проекта.
Другой способ прокачаться — брать сложные задачи. Но это тоже определенная ответственность.
Без ответственности это работает сильно хуже. Как то так:
— Привет. Я хочу развиваться давай обсудим?
— Хорошо, у нас есть возможность делать А, Б и участвовать в В.
— Ой, а я хочу только свои задачи пилить и развиться
— ))))
— )))
Тут также работает следующее: без желания людей насильно "развивать" их не будешь.
На мой взгляд тимлид — один из наиболее заинтересованных персонажей в развитии своих сотрудников.
Кроме этого, в некоторых компаниях практикуется "добровольное менторство" — когда часть более опытных сотрудников, имеет подаванов, с которыми работает, дает постоянную ОС и трекает развитие
Если свести все в пункты, то:
Я хочу развиваться:
Брать ответственность, принимать решения
Участвовать в обсуждения фронтенд-группы
Если в компании не видно точек роста, то смотреть на опен-сорс, сообщества в своем городе
Если на 3-й пункт нет времени или хочется больше во время работы чувствовать свой рост, то менять компанию — тоже может быть решением
Конечно же, эти советы будут работать, если у вас уже "набита рука" и вы без проблем делаете типовые задачи разной сложности.
Если "Я хочу помогать сотрудникам в развитии", то:
Ненавязчиво предлагать ответственность — ни в коем случае нельзя заниматься перекладыванием.
В обсуждениях намеренно (если возможно) давать сотрудникам первым высказать свое мнение, возможно сделать ошибку
Давать сотрудникам задания сложнее их текущего уровня.
Как я пришел к таким пунктам? Вот мой личный опыт:
В хх я пришел в команду поиска. Нас было 2 фронтендера. За полгода текущие задачи поиска были закрыты и я заскучал. В этот момент я начал разбирать тогдашний UIToolkit, который состоял из 3х компонентов-инвалидов и подключался через копипаст скрипта в проект.
Настроили его подключение через npm, отделили от проекта, сделали сборку на gulp вместо make файла. Развили саму библиотеку и в итоге я стал ее мейнтейнером. На текущий момент это больше 100 компонентов для разных стеков. Это был первый опыт ответственности.
Затем перешел в команду мобильного сайта, где взял ответственность на архитектуру резюмебилдера на клиенте. Очень благодарен моему "тогдашнему" тимлиду, который эту ответственность дал.
И затем перешел в проект talantix.ru, где был, по сути, создателем всей архитектуры проекта.
В конце пути, перешел в команду архитектуры hh.ru, и передал мейнтейнерство проекта другому коллеге.
С каждым разом в том числе изучал этот вопрос и приходил к мысли: "если бы не ответственность, то всегда можно было бы отстраниться при появлении сложностей и тогда это бы не дало нужного буста".
Так я и пришел к выводам из начала этого треда :)
Я не затронул тему развития софт-скиллов в своем рассказе, это отдельная и очень сложная тема. Ответственность в которой — тоже занимает не последнее место.
Тред (@xnimorz)
С началом пути в разработке разобрались. Дальше от средних-крепких джунов в мидлы и развитие мидлов. Это тот момент, когда человек попал в разработку, занимается формошлепством, решает задачи и многое другое. И в какой-то момент у людей появляется вопрос: "А как мне развиваться?"
Начало пути в разработку: twitter.com/jsunderhood/st…
О росте мидлов: twitter.com/jsunderhood/st…
Тред (@xnimorz)
Помогите мне определиться с темой на завтра: я думал о том, чтобы рассказать о performance и клиентских метриках или потравить пятничных баек о разработке, таких как дебаг утечек памяти в node.js, реклама, которая фризила сайт на 30 секунд:
🤔
38.8% Performance в пятницу!🤔
61.2% Давай байки в пятницу!Если что другая тема вполне может быть в субботу :) мне интересен порядок
@jsunderhood Но при этом смотришь на других и все равно видишь что много где отстаёшь от багажа знаний других людей.
Ощущение, что «все вокруг круче меня» складывается потому что Вова умеет лучше верстать, Маша сильнее в алгоритмах, Саша круче в знании React. У многих разработчиков появляется такая «роза» компетенций. И это нормально, что где-то кто-то лучше/хуже других. twitter.com/m0rg0t/status/…
Сейчас направлений и специфики везде очень много. Всё знать никогда не будешь.
Помогите мне определиться с темой на завтра: я думал о том, чтобы рассказать о performance и клиентских метриках или потравить пятничных баек о разработке, таких как дебаг утечек памяти в node.js, реклама, которая фризила сайт на 30 секунд:
В голосовалке победили пятничные байки :) Завтра будем говорить о разных смешных, интересных случаях из рабочей и не очень практики :)
Про performance, как и зачем мы собираем метрики с клиента и об экспериментах с улучшением \ ухудшением скорости загрузки поговорим в субботу. twitter.com/jsunderhood/st…
Пятница
Сегодня травим байки о разработке!
Начнем прямо со вчерашнего фейла. У кого не бывает фейлов, тот явно что-то недоговаривает :)
Обновляю картинки-иконки в статике. Релиз выходит, и вроде бы все хорошо.
Прилетает бага. На jobs.tut.by иконки не отображаются. Я в этом время еду в метро, с телефона понимаю, что что-то странное.
У нас единое приложение для hh.ru, jobs.tyt.by и других доменов. На основном домене hh.ru все хорошо.
Оказывается проблема с политиками кеширования, с nginx.org/ru/docs/http/n… На всех региональных сайтах политика жестче и ключ proxy_cache_key установлен на requst_uri. И nginx старательно все кеширует.
Все картинки у нас запрашиваются с GET запросом, если uri не поменялся, nginx отдаст старую картинку. Сравните:
i.jobs.tut.by/bloko/blocks/i… и i.jobs.tut.by/bloko/blocks/i… Через какое-то время кеш смоется по разным причинам, но это вопрос дней.
Причина: в большой инфраструктуре сложно держать в голове все условия и переменные :) Не забывайте про кеш.
Тред (@xnimorz)
@jsunderhood Ооо! А какие отличия между сайтами на разных доменах? А как организовано? С какими проблемами столкнулись, какие есть интересные решения вокруг этого?
Нет, про это не рассказывал. Попробую описать фактами: twitter.com/webholt/status…
Кодовая база одна, отличия между сайтами описываются явно в коде (даже до уровня if (domain === DOMAINS.KAZAHSTAN))
Есть необходимость учитывать страновую политику: сервера, определенные законы. Например, была история, когда в одной стране принимали закон и нужно было убрать автоматическую конвертацию валюты as soon as possible.
Лично для меня (я не девопс все же), это главная особенность: в странах отличаются законы, эти законы необходимо учитывать как при разработке задач, так и при рефакторинге
Обычно мониторим все законы в странах и заранее пишем код. В нужный момент просто переключаем рубильник
Страновые сайты отличаются не только логикой в определенных местах, но и, например, кешированием статики, так как статика идет по проксирующим серверам (js, css, интерфейсные картинки).
Домены разруливаются на nginx, почти любой бекенд при необходимости может узнать о том, на каком сайте был вызван (константы, не физический domain.name), но обычно это не нужно, достаточно только на прослойке иметь это знание
Каждому домену соответствует константа, констаны в том числе есть в конфигах yml, чтобы при сборке использовать в разных сервисах (могу ошибаться здесь)
Переводы хранятся в базе, каждый сервис подгружает переводы себе на старте. Используем marisa-trie структуру данных для хранения в сервисе. Раз в N единиц времени сервис идет за обновлениями переводов (если они были). Так поддерживаем актуальность переводов без релиза
Возможно для меня привычно, но это все особенности, на первый взгляд. Возможно есть какие-то определенные вопросы?)
Тред (@xnimorz)
Небольшая залипашка: matthewrayfield.com/goodies/inspec…
(нужна консоль разработчика)
Следующая занимательная история:
Теплое весеннее утро. Кто-то ползет к офису, кто-то, зевая, заваривает кофе. Прилетает ошибка от сапорта — "сайт не работает".
Разработчики бегут к ноутам, начинают разбирать проблему... Все работает, все хорошо. Жалобы продолжают поступать.
Сообщения все похожи: "Сайт открывается и тут же зависает секунд на 30. "
Начинаем проверять все возможные цепочки, какие запросы уходят, что происходит. Все равно все хорошо.
Потратив около 3 человеко-дня (3 разработчика на 1 день ушли в проблему), выяснилось, что им просто не повезло. Они не собачники 0_о
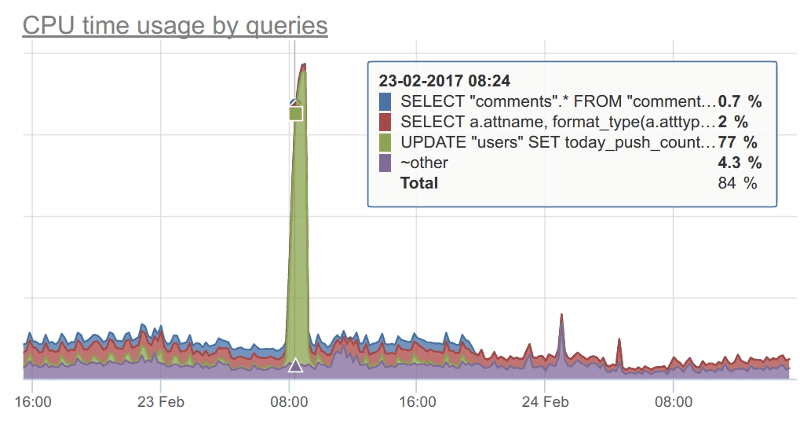
Все дело в том, что поставщик рекламы добавил новый баннер для пользователей, рекламирующий собачий корм. Этот баннер на 30 секунд уходил в цикл, где постоянно пересчитывался layout.
Так как записи performance у нас не было на тот момент от пользователя, проблему приходилось искать руками.
Тред (@xnimorz)
@jsunderhood А разве сейчас не принято пихать рекламные банеры в iframe? Типа безопасность, вот это вот всё
История давняя. Именно по результатам истории приняли два решения:
Реклама ломать нас не должна
Реклама должна грузиться по idleCallback twitter.com/unel86/status/…
Пришлось отвлечься, сейчас делаем одну интересную штуку: на получение страницы создаем общий action, который инкапсулируем в каждый редьюсер. И если в ответе присутствует поле, за которое ответственен редьюсер, то редьюсер запишет этот payload ответа.
Когда я говорил про layout, вспомнил одну штуку: вы пользуетесь performance вкладкой чтобы оценить время исполнения кода? При снятии performance клик на ссылку с кодом откроет код и время, которое он исполнялся. Вот вкладка перфоманса, когда 20 секунд исполнялся некий код:
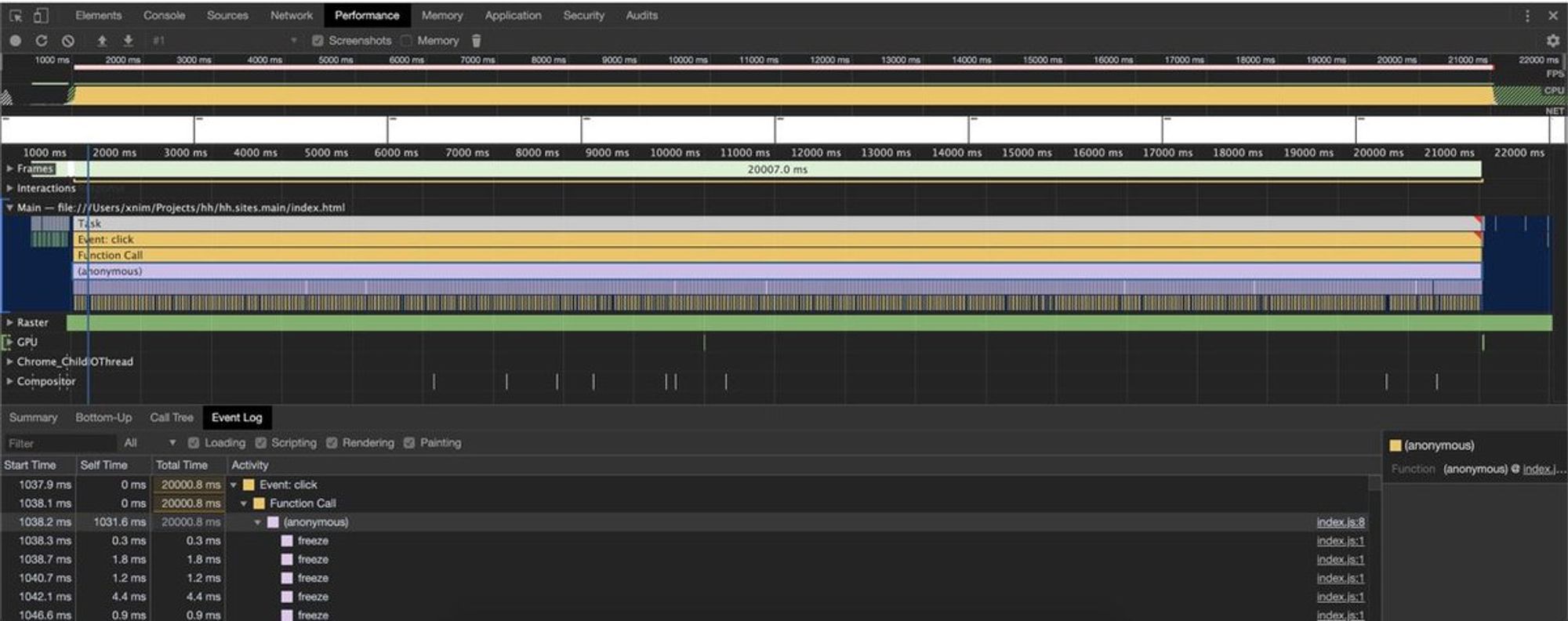
Кликаем на строку кода, получаем красоту:
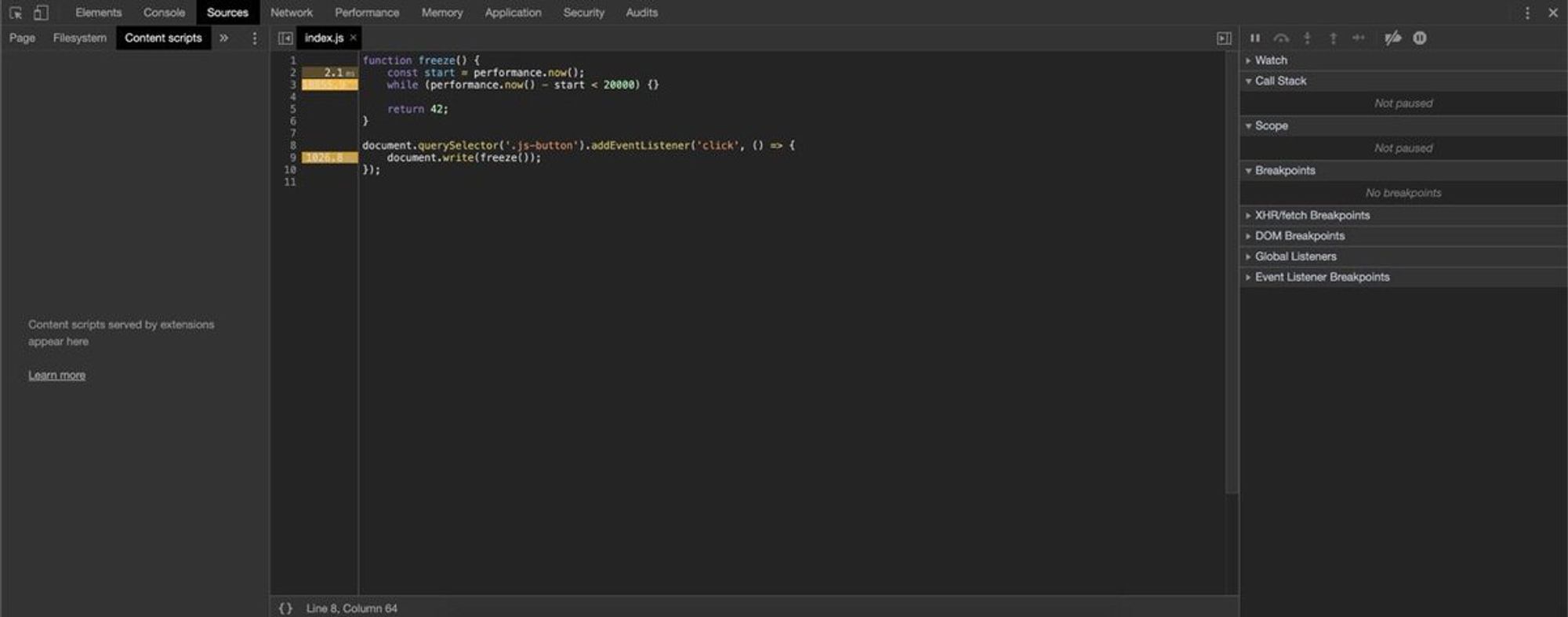
С сурсмапами у меня нормально не завелось :(
Детективная история. История вымышлена от начала до конца, любые совпадения абсолютно случаны. В главных ролях: компания А (А). Саппорт (С). Команда разработки (КР).
А: Сайт не работает.
С: Стандартное выяснение проблем, статусов ответа
А: Уточняют, что открывают страницу, страница грузится секунд 10, потом ничего не происходит.
А: Делают скриншот сайта и консоли
С: Передает данные КР.
КР: В консоли ничего нет.
КР: (Замечают часы в углу скриншота, грепают логи)
КР: За это время долгих запросов не было. За весь день самый долгий запрос выполнятся 1 секунду.
КР: Сделайте har файл с запросами
С: рассказывает как сделать har файл
А: вот
C: эй, КР, вот har файл
КР: так, что тут у нас... Так все ж хорошо?
С: сейчас узнаем
А: Да, мы чтобы записывать har файл файрвол отключали
КР: :facepalm:
В чем соль — файрвол резал запросы и они просто не доходили до нас.
Тред (@xnimorz)
Сейчас будет сложная история с техническими подробностями. История о сложностях работы с переводами на сайте.
История сложная по многим причинам:
Переводов больше десятка мегабайт
Не все переводы интерфейсные (интерфейсных только пара мегабайт), но тоже немало
Переводы хочется менять в рантайме из панели админа
В случае с SPA приложением хочется грузить переводы только для конкретной страницы.
Как решать такую проблему?
Мы пришли к такой модели:
В реакт-компонентах появляется поле static trls поле, которое является обычной Map<String, String>. В ней value — это ключ перевода.
В контексте храним информацию, какой язык перевода нужен (потому что может быть часть сайта на русском, а резюме — на английском).
При сборке кода babel плагин выдирает поле trls, собирает большую мапу "страница: список переводов". Этот файл подключается как конфиг и по нему для каждой страницы присылаются переводы.
На бекендах переводы подгружаются из базы при старте и затем время от времени получают обновления. В рантайме храним переводы в marisa-trie дереве.
Кстати, плагин, который выдирает статические поля вот: github.com/hhru/babel-plu…
Казалось бы, хорошее решение, легко использовать.
Все так, но в сентри начинают приходить баги, что перевода нет.
Добавляем логирование, начинаем трекать, в каких случаях происходит ошибка, что лежит в сторе, какие последние action происходили.
Делаем первый заход, понимаем, что страница например bla-bla, а данные в сторе от страницы foo-bar.
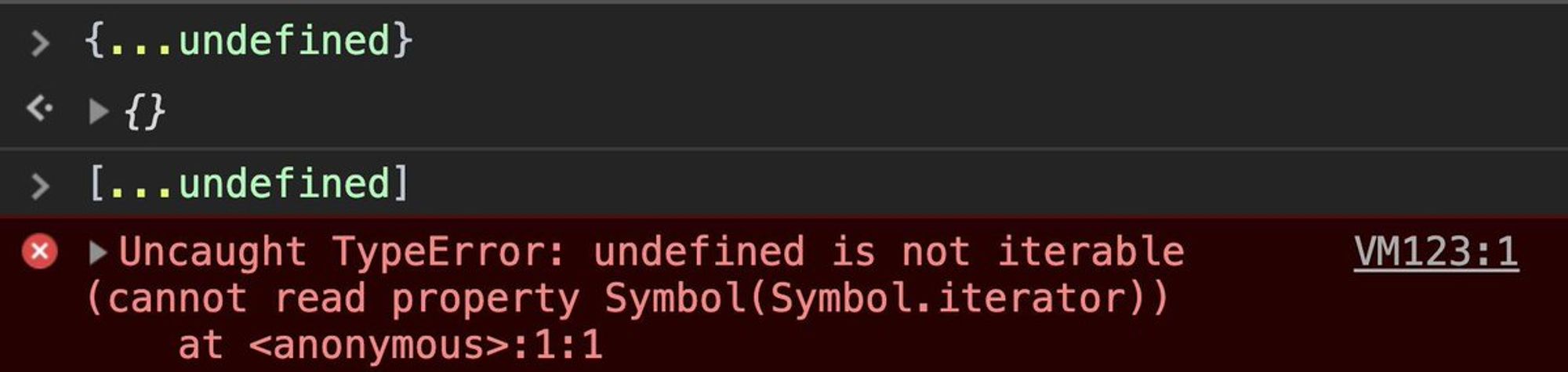
Разбираемся в проблеме, понимаем, что в некоторых редьюсерах данные применяются вот так: (state, action) => bla-bla return [...action.payload];
Quite a tricky thing in spread operator: you can spreadundefinedin object like{...undefined}, but you can't do it with arrays [...undefined]. It happens, as spread syntax can be applied only to iterable objects except for spread properties (e.g. for objects). pic.twitter.com/ItVvJRZyyj
В чем соль 1: Оператор ... очень хитрый оператор. Я писал об этом здесь: twitter.com/xnimorz/status… И поэтому он может падать. если action.payload будет undefined
В чем соль 2: мы используем batch actions и делаем батчевый редьюсер. Если падает применение данных в одно из полей в сторе, стор не применяется, остается старое значение.
Переводы хранятся в сторе. И по стечению обстоятельств — переводы первыми вызываются на странице. Вот они и падают.
Окей, почему мы не получали правильную ошибку? Оказалось, потому что случайно поставили на promise, который обрабатывал данные от асинхронного запроса reject ветку без репорта ошибки :facepalm:
Вот так один неверный reject привел к долгой истории и правкам редьюсеров.
Но на этом все не закончилось! Ошибка всплывает опять. Начинаем разбираться, находим проблему в фетчере и асинхронной записи данных (рассказывать подробно не буду, слишком много специфики). Правим, проходит время — ошибка снова всплывает.
Пять подобных итераций и полгода спустя мы из-за этой ошибки отрефакторили кучу мест, каждый раз получалось ее воспроизвести и пофиксить, но ошибка все еще с нами. Мы думаем о том, чтобы дать ей почетное звание помощника в поиске инфраструктурно-архитектурных недостатков.
Тред (@xnimorz)
Немного расскажу о концепции батчевых экшенов и батчевом редьюсере в Redux
В редьюсерах у нас много полей. Я не считал, не удивлюсь, если пара сотен.
TL;DR Сразу решение: gist.github.com/xnimorz/352a6c…
В коде привел объяснение подхода. Дальше в треде будет история: какую проблему решали, почему так сделали, какие профиты это нам принесло
Мы сделали систему, где при SPA переходе вызывается middleware, она делает GET запрос самостоятельно на нужный урл.
Прослойка на питоне собирает все данные от бекендов и отдает один большой JSON ответ.
У нас нет списка "вызови такие-то экшены при открытии такого-то урла", вместо этого, мы проходим по полям JSON и собираем набор "базовых" экшенов для того, чтобы на них вызвать dispatch.
Базовый экшен — у каждого редьюсера у нас есть экшен, который занимается тем, что передает данные as is в редьюсер (которые ему пришли). Выглядит так: gist.github.com/xnimorz/3cd1ce… и здесь базовый экшен передается третьим аргументом в createReducer.
Мы сейчас идем к тому, чтобы такие редьюсеры описывались еще проще: в конфиге стора была запись currency: typicalReducer();
Таких экшенов на большой JSON получается много. Они все записываются в массив actions и затем мы делаем dispatch(actions).
Мы диспатчим сразу массив экшенов, который на уровне рутового редьюсера итерируется и применяется вот так (ссылка с начала обсуждения) gist.github.com/xnimorz/352a6c…
Какие преимущества подхода:
Мы не завязаны на порядок применения. Либо все редьюсеры разово применились, либо нет. Нужно задиспатчить что-то, диспатчим разом
Автоматизировали процесс страничных переходов
Тред (@xnimorz)
@jsunderhood Добрый вечер! Расскажите, пожалуйста, подробнее о том, как удается при таком серьезном продукте и большом количестве команд сохранять то самое "общее владение кодом"?
У каждой команды свой продакт (1 продакт может быть заказчиком у нескольких команд). И у каждой команды свой беклог.
Если сделать полностью "раздельную ответственность", то команде А, чтобы добавить новый параметр в поиск придется ждать команду Поиск. twitter.com/a_ganichev/sta…
У команды Поиск свой беклог, и когда она сможет взять задачу команды А — непонятно. Это бы сделало выход фичей непрогнозируемым.
Вместо этого у нас единый набор технологий на большей части проектов. Где-то есть специфика (например поисковой движок).
Общее владение кодом реализуется вот так: команде А нужно внедрить новый параметр в поиск. Она сама пишет код и дает на ревью ребятам из поиска.
Тестирует задачу, пишет автотесты (иногда автотесты делаем после выхода задачи) Во время и после выхода релиза у нас очень много систем мониторинга. Большинство проблем мы отлавливаем даже до того момента, как релиз полностью выйдет. Это позволяет добиться определенной надежности
Большое количество фичей выходит под настройкой (переключателем). Если что-то идет не так, то команде достаточно переключить триггер. Все триггеры умеют раскатываться на часть пользователей. Если есть опасения можно выпустить задачу на 5% пользователей и понаблюдать за динамикой.
Если все же баг случился через некоторое время после выхода задачи, то по blame видим, какая команда и назначаем на нее ошибку. Если код старый, то у каждой команды закреплена "зона ответственности" — это набор фичей, страниц.
И если проблема произошла на странице поиск — баг летит в команду поиск. Они, в свою очередь, могут определить чей это баг или поправить сами.
Тред (@xnimorz)
Суббота
Пока вел @jsunderhood, мне сказали что бек на nodejs - это "поделка из желудей", а тут dartup.ru проводят 23 ноября (участие бесплатно) и придётся идти без вариантов. Отсюда вопрос: %username%, что ты выбираешь для бэка?
Я за желуди ¯_(ツ)_/¯ twitter.com/ovrweb/status/…
Доброе утро! Сегодня будем говорить о performance, клиентских метриках и все, что с этим связано.
Я выступал на РИТ++ youtube.com/watch?v=4joeMk…, рассказывал о сборе метрик и частично затрагивал эксперименты с производительностью.
Материалы по докладу: github.com/xnimorz/Fronte…
Сегодня подробнее поговорим про это.
Ссылка уже была, но она крайне хорошо коррелирует с историями, о которых поговорим сегодня.
Желание трекать метрики и реагировать на них зародилось у нас очень давно. Вначале это был обычный набор метрик, навроде — domContentLoad, load events и т.д. из performance.timings.
Затем мы сделали более серьезный заход на эту задачу и организовали подсчет таких метрик как FMP (first meaningful paint), tti (time to interactive), FIT (framework init time) FID (first input delay) + добавили свой framework render time (только рендер тайм).
Дальше будут треды с подсчетом метрик.
FMP — от него хотим следующего: понимание нашего critical path, количества времени которое уходит на него. Дальше будет очень большой тред с большим количеством графиков и сравнений:
TL;DR: мы пришли к такому решению: gist.github.com/xnimorz/8ec4fc…
Это позволяет нам трекать critical path, понимать, когда render tree "доходит" до нужного места. Это не самый "честный" FMP, но это наиболее репрезентативный вариант до которого мы смогли дойти.

Дальше история того, как мы к этому шли и графики, графики!)
С одной стороны, FMP говорит о том, что нужно трекать, когда контент отобразился. И тогда код будет что-то вроде такого:
gist.github.com/xnimorz/6b939a… Этот код приходится вставлять inline или блокирующим вызовом (чтобы cache работал).

Offtop, но если вы сделаете блокирующий вызов для того, чтобы кеш сработал, я вас удивлю: кеш может не сработать так, как вы ожидаете! Почему так расскажу чуть позже сегодня
Если затрекать такое время от gist.github.com/xnimorz/6b939a… и выводить на график, получим вот такую чушь:
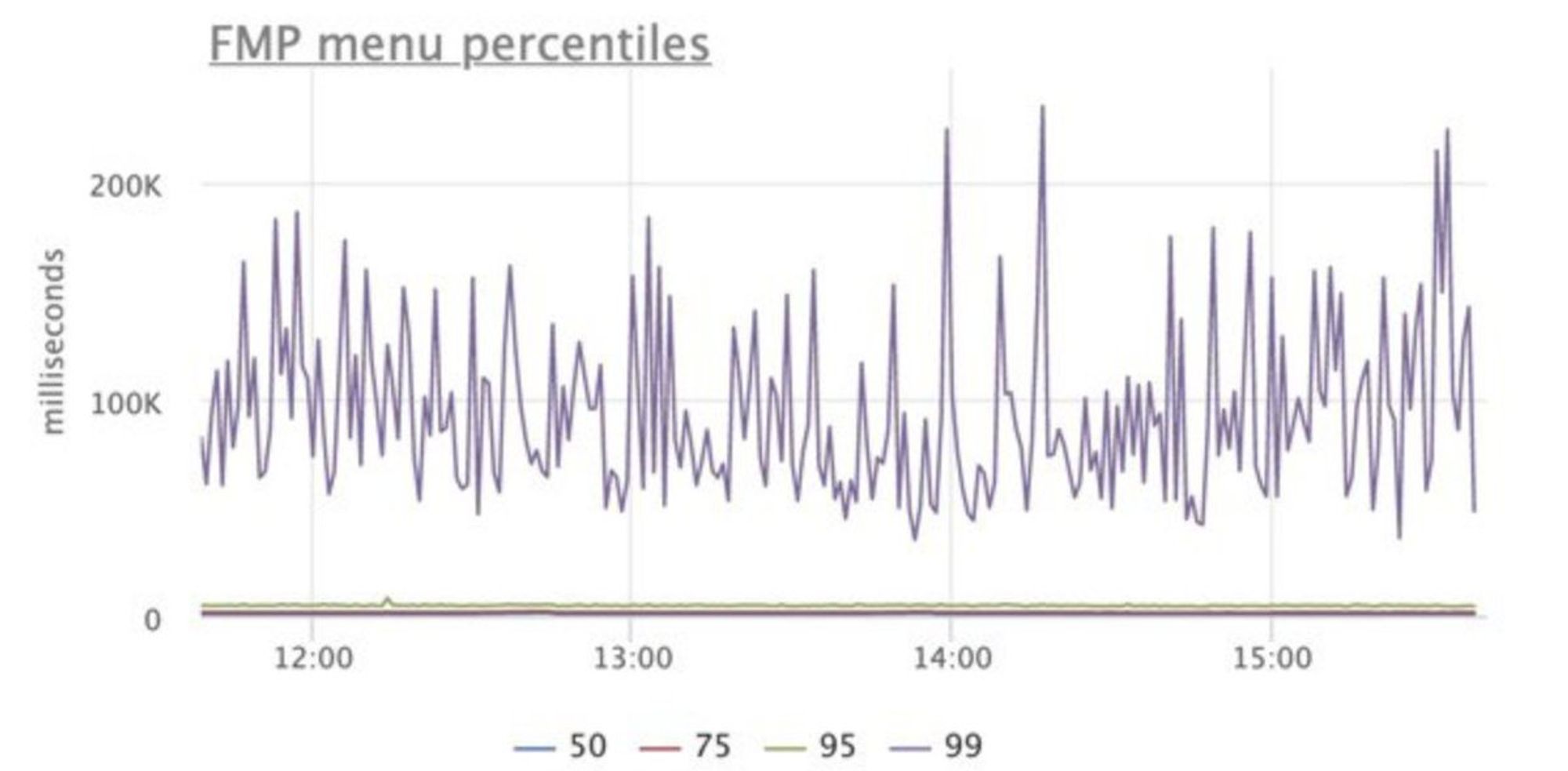
Почему чушь?
99 перцентиль составляет больше 100 секунд. Представьте людей, которые настолько терпеливы? :)
Если копать на меньшие перцентили (95, 75) там значения будут около 20-30 секунд.
Вспоминаем вчерашнюю историю про "сайт грузится и не работает 30 секунд". Понимаем, что если пользователям приходилось бы столько ждать, то обращения в сапорт были бы.
Почему так происходит? Если пользователь переключит вкладку, то raf не будет исполняться, пока вкладка не станет активной. Вот наглядное видео: youtu.be/jmvzULtV7Q8
Какое может быть решение? Трекать активность страницы!
В коде это будет так: gist.github.com/xnimorz/917a57… здесь скрипт, который трекает видимость страницы должен располагаться до fmp.
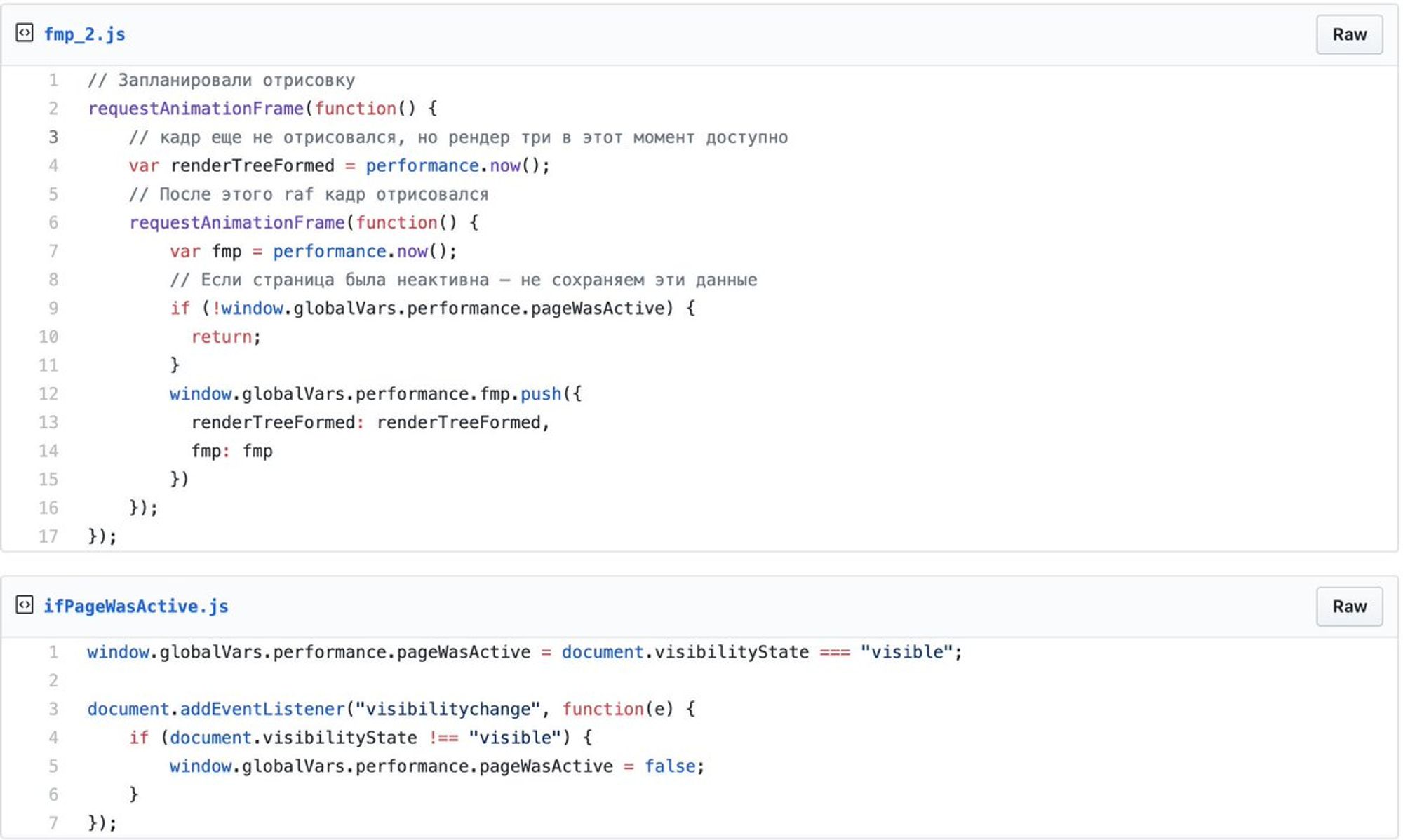
Насколько отличается первый и второй вариант? Вот графики:
Первый вариант 95-я перцентиль (без трека visibility page api).
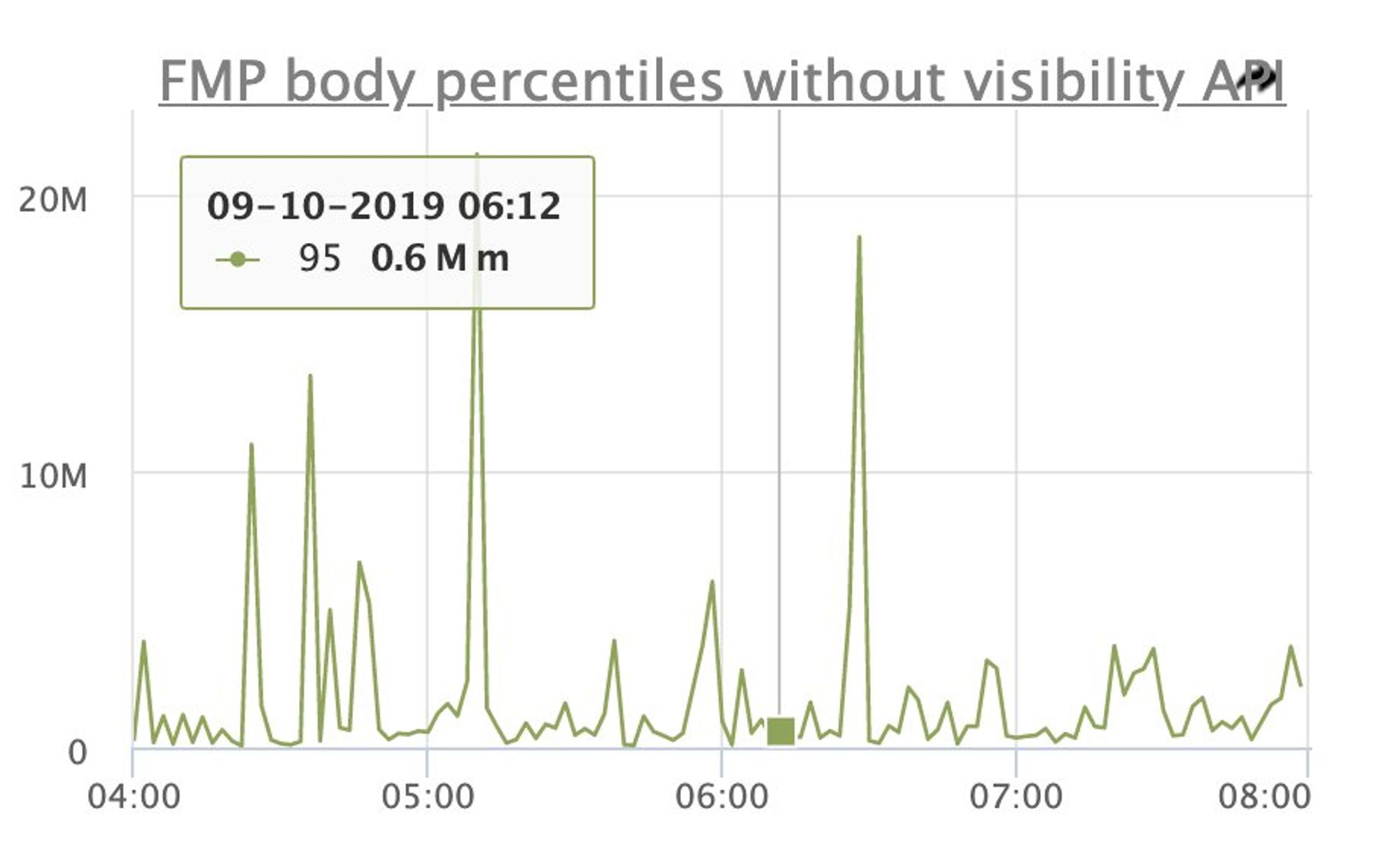
Вот вариант, когда убираем значения, если пользователь уходил со страницы, или открывал фоновую вкладку:
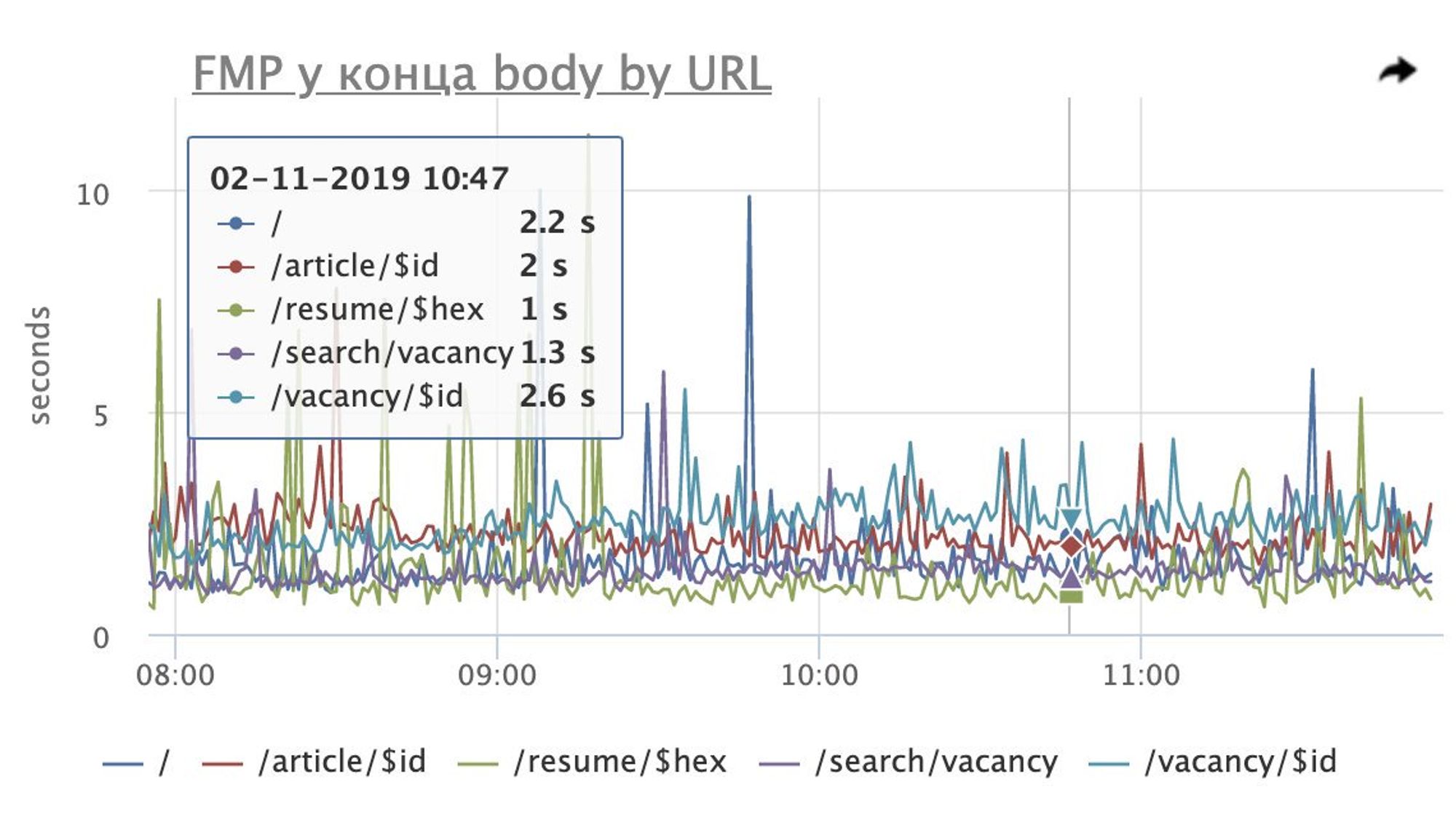
Здесь уже видим, что значения похожи на правду: 1 секунда загрузка резюме, самая тяжелая страница: 2.6 секунды.
У второго варианта есть проблема. Он не трекает многих пользователей, так как один из популярных паттернов у пользователей хх: открыть вакансии в новых вкладках и потом идти по ним.
Здесь может прийти идея трекать новые DOM метрики, которые уже есть в браузерах, но они также плохо учитывают неактивные страницы и мы получим те же проблемы, о которых говорили вначале.
Как научиться трекать остальных пользователей? Исполнять скрипт, который не зависит от raf 🙂
Это можем сделать, просто снимая timestamp, при исполнении инлайн скрипта.
Это позволяет нам делать аналитику, потому что у нас уже есть renderTree.
Делаем это вот так: gist.github.com/xnimorz/8ec4fc…

Если сравнить со вторым вариантом, разница оказывается не такой большой, как можно было предположить 100-300мс. А охват пользователей полноценный. По эксперименту в неделю, поняли, что разница между вариантами незначительна и остановились на вариантом с полным покрытием кода.
На график выводим 95-ю перцентиль. Т.е. у 95% пользователей страница отображается не дольше, чем за это время на графике и только у 5% пользователей — хуже.
95" график важного контента (+/- первый экран):
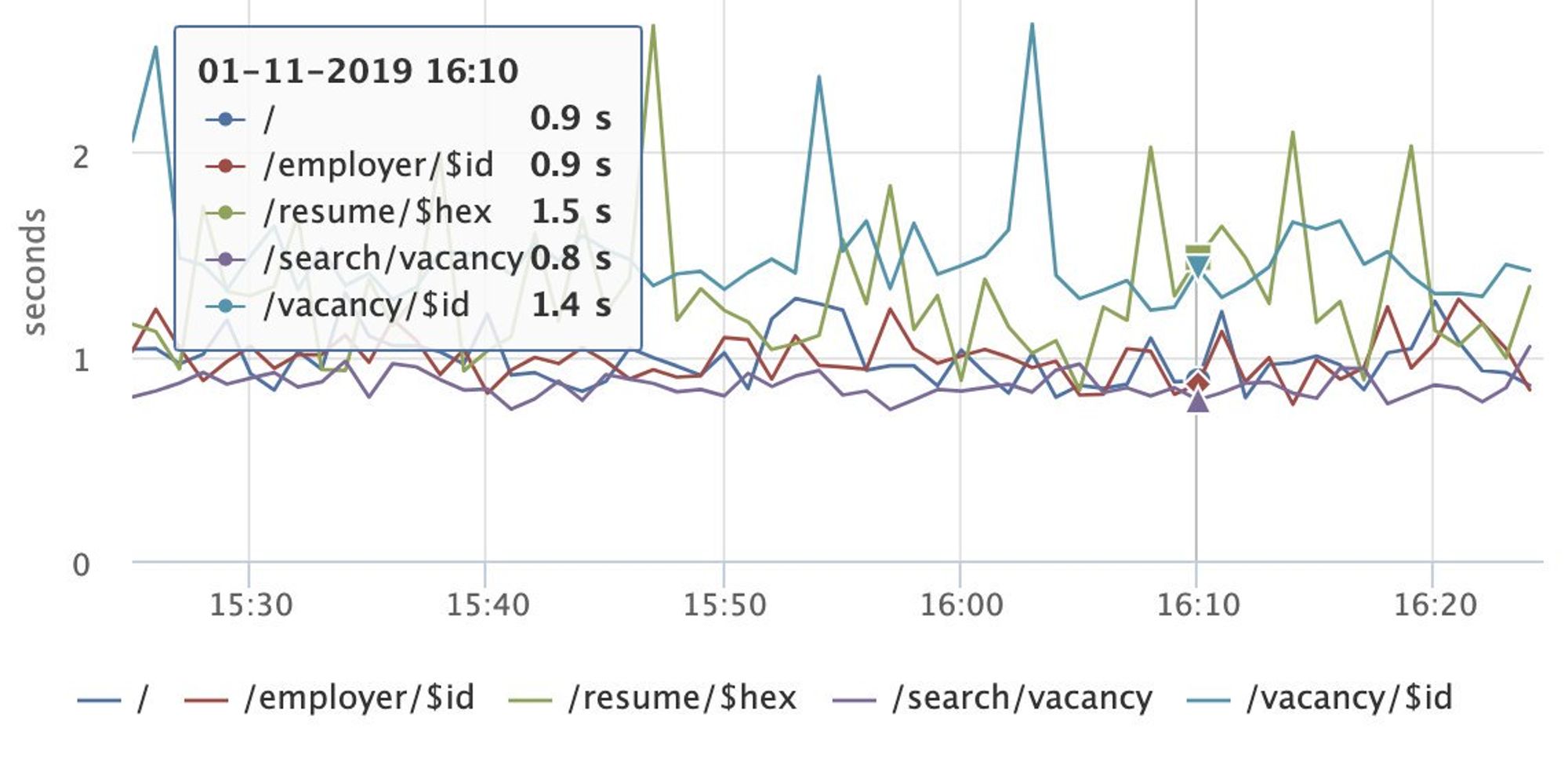
95" то же время, но с засечкой body:
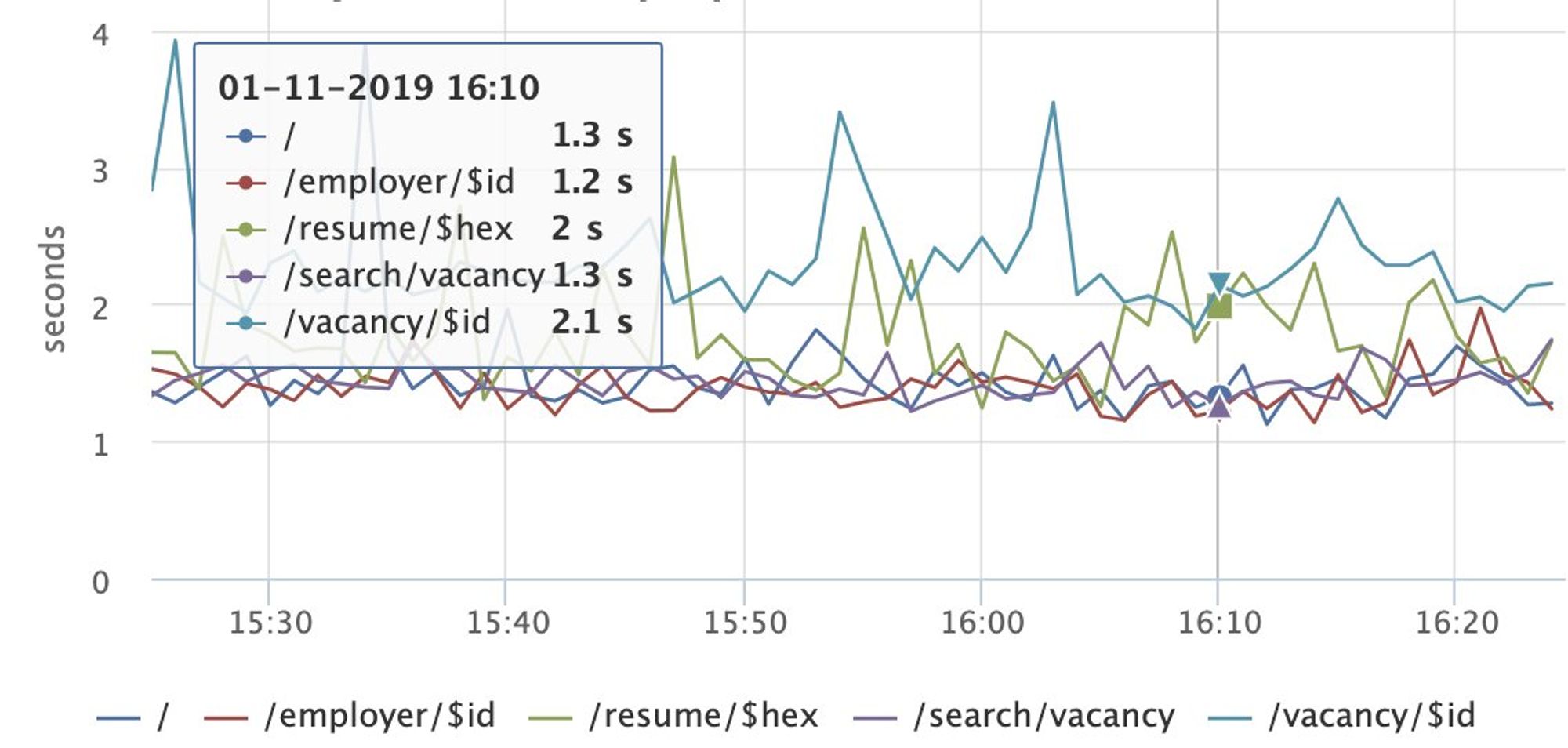
Для сравнения вот 50 перцентиль за тоже время у body:
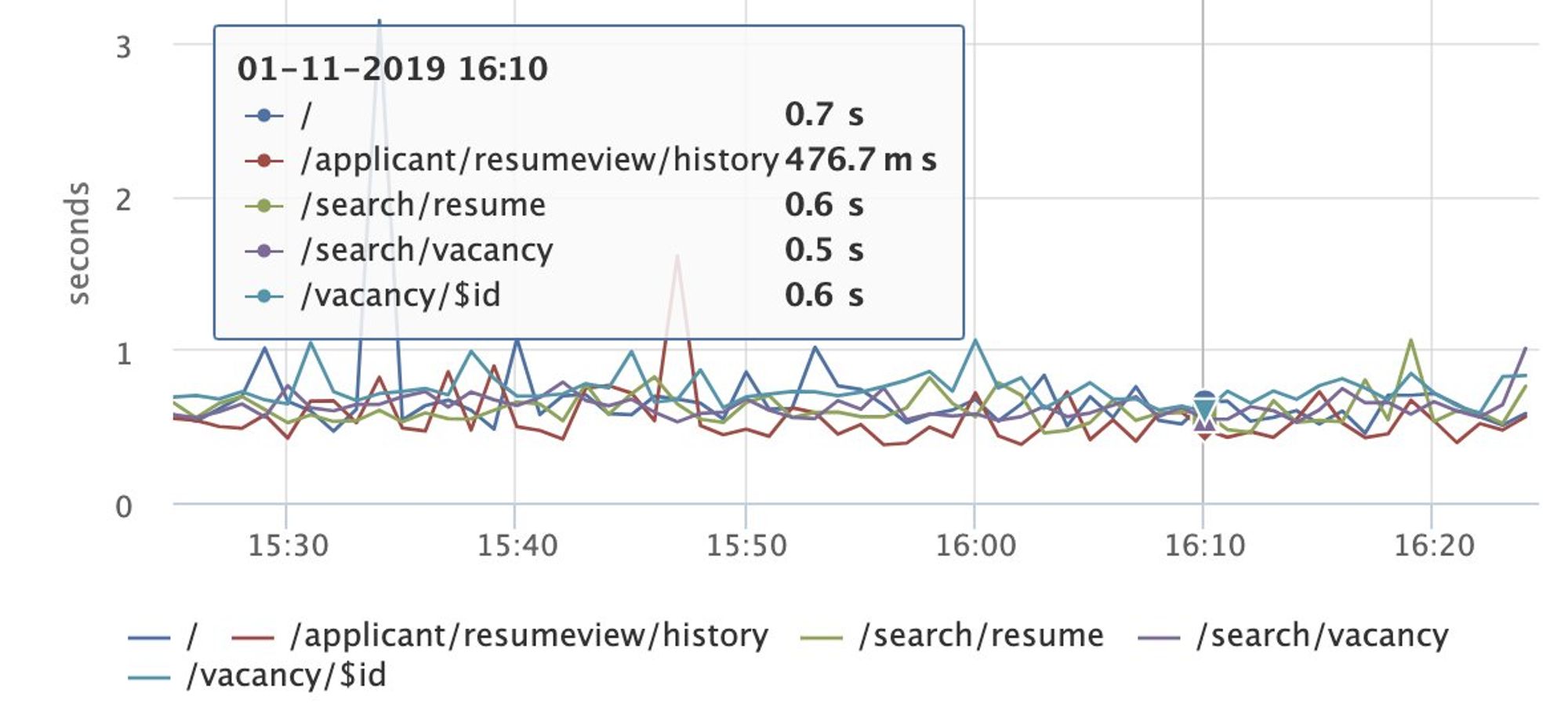
Эти графики не отображают мобилка \ десктоп. Но если это сделать, будет очень необычно.
Вот мобилки:
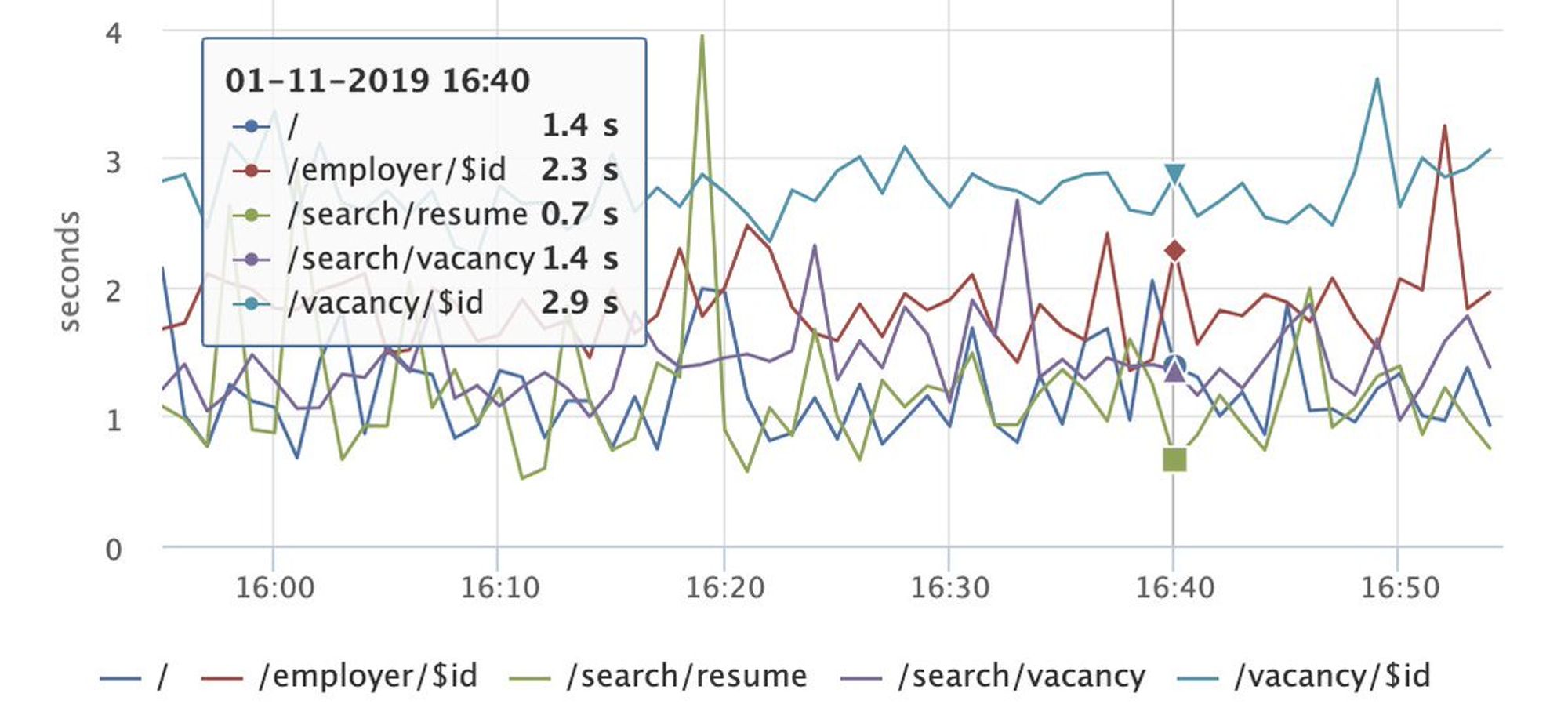
Десктоп:
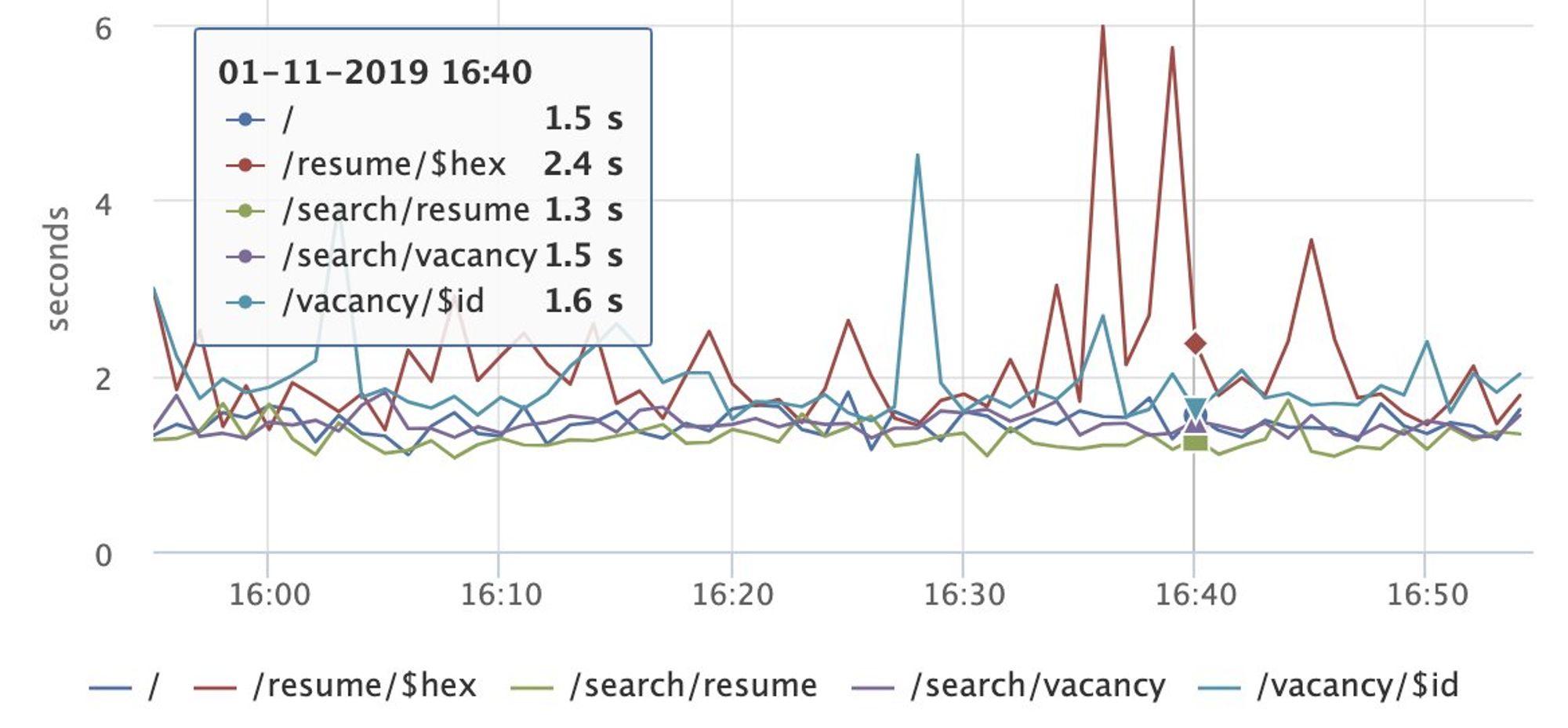
Тред (@xnimorz)
@jsunderhood Померил посчитали, ок. Какие выводы это позволяет сделать?
Чуть дальше я расскажу, что мы делали с графиками.
А сейчас немного о том, зачем мы все затеяли. twitter.com/denisx/status/…
Почему это важно: перед задачей исследовательского характера, у тебя обычно есть гипотезы. Они могут быть подтверждены или нет.
У нас было желание понять, насколько улучшение или ухудшение производительности сайта влияет на бизнес метрики.
То есть, чтобы мы могли прийти к бизнесу и сказать: если мы потратим месяц разработки на улучшение загрузки вот этой страницы, это дополнительно приведёт нас 100500 регистраций.
Это наша идеальная цель. Но на пути как обычно, появилась куча уточнений.
И проводить эксперименты без правильно настроенных метрик бесполезно, у нас не будет определенных зависимостей. Поэтому с метрик и начали.
Тред (@xnimorz)
Дальше TTI: TL;DR: gist.github.com/xnimorz/0b6080… Мы трекаем лонгтаски, ресурсы и не отправляем TTI, если пользователь уходил со страницы (страница была не активна). Дальше тред и графики.
Изначально делали мы без visibility page API, но получили те же проблемы, что и с FMP. В коде нет raf, но есть setTimeout. SetTimeout на неактивной вкладке выполняются сильно реже.
Поэтому добавляем API и графики также стабилизируются:
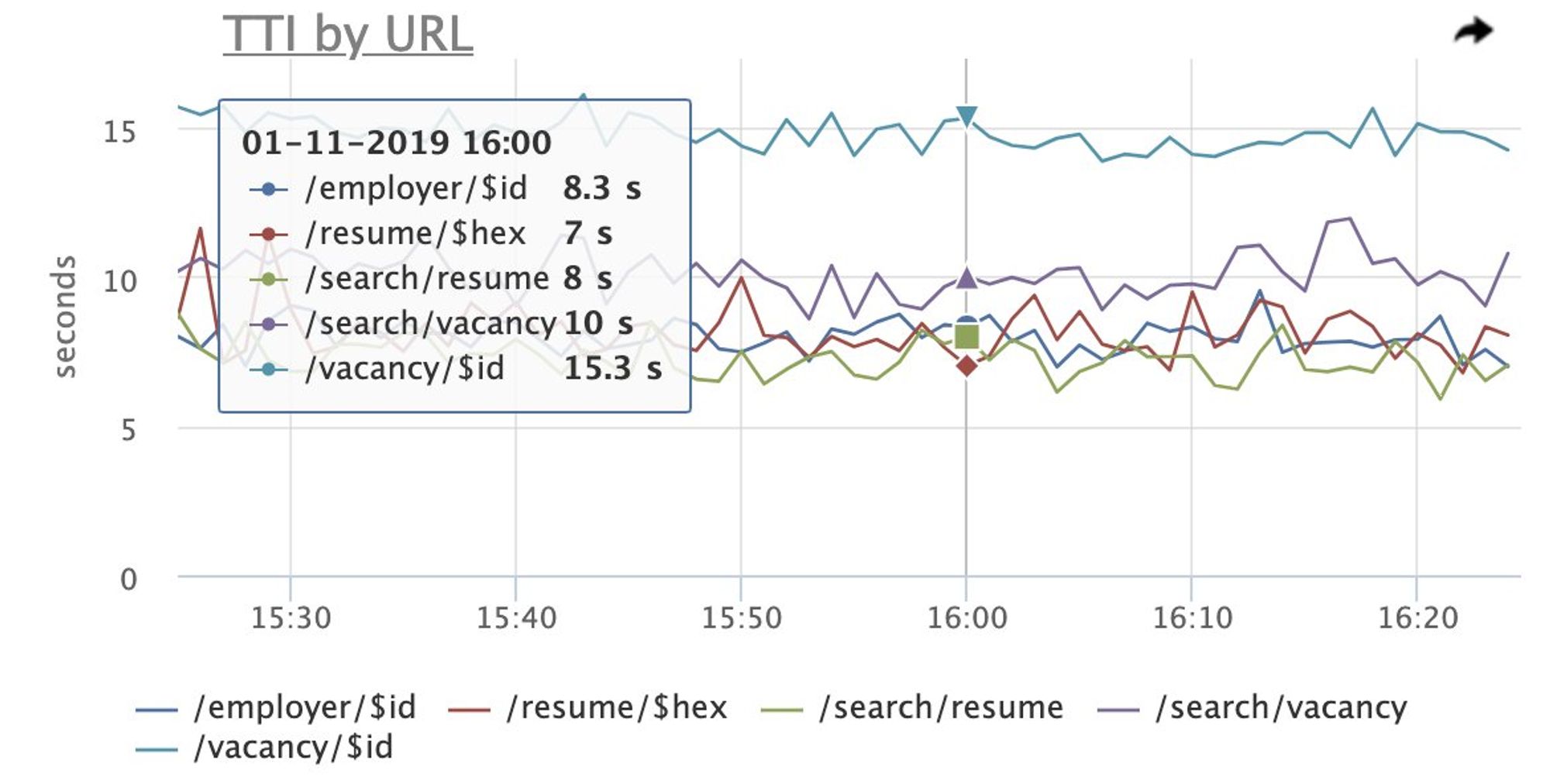
Чем крут этот график? у нас есть явный фаворит, оптимизацией которого нужно заниматься в первую очередь — страница вакансии.
То, что эта страница будет явным аутсайдером — у нас были догадки. Замер и график позволили гипотезу подтвердить.
Чтобы не писать свой код для TTI, можно использовать готовое решение от google: github.com/GoogleChromeLa…
Тред (@xnimorz)
Для FID мы используем также готовое решение: github.com/GoogleChromeLa…
Для framework render \ init \ hydrate time делаем просто:
ReactDOM.hydrate(root, reactRootNode, () => performance.mark('hydrate'));
На графике 95 перцентиль:
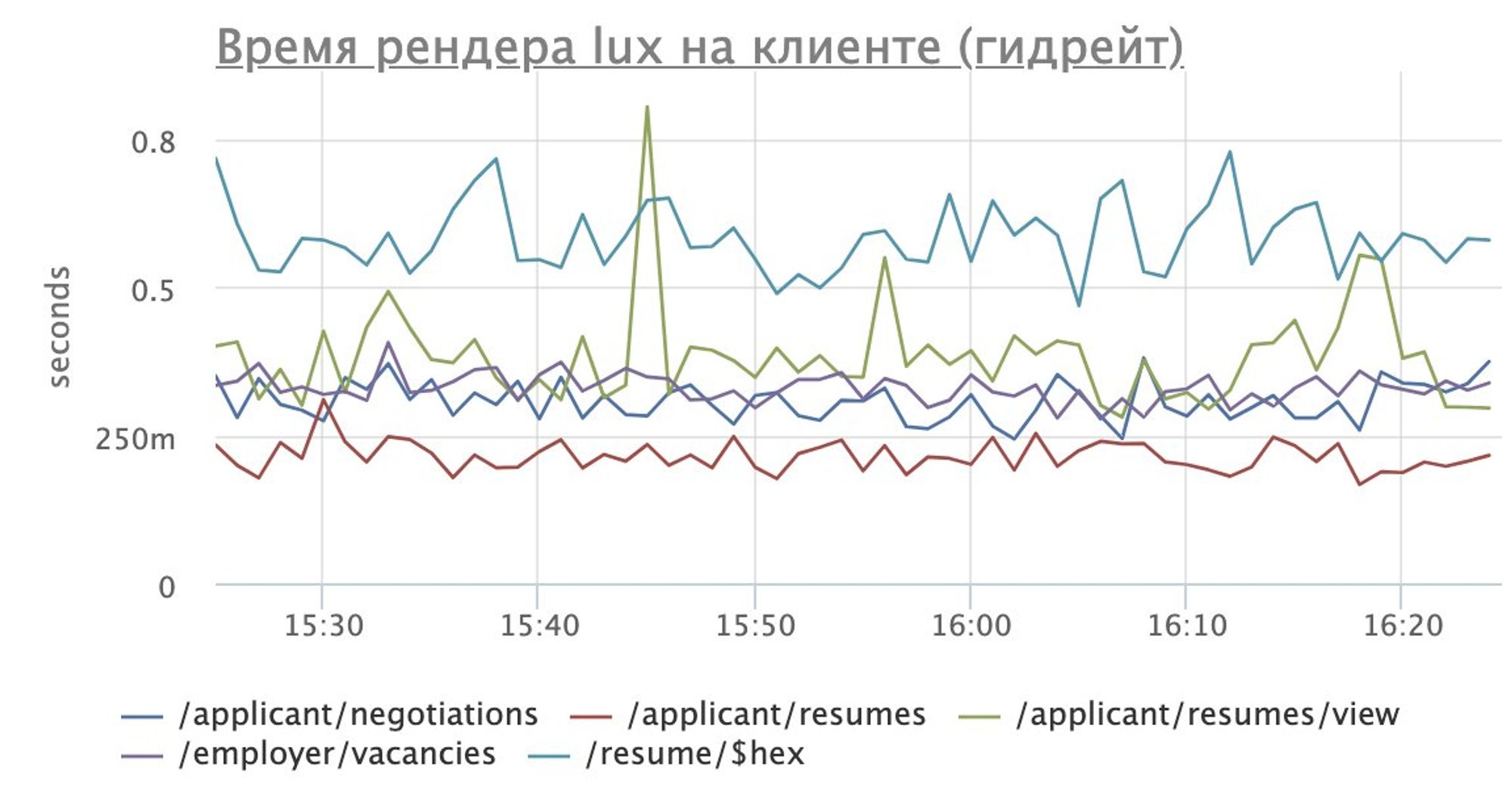
Важное уточнение, мы считаем разницу, между началом рендера и этим колбеком.
Это нужно, чтобы каждый этап был отделен друг от друга и на графиках было понятно, в чем проблема.
Мы используем SSR, поэтому пользователь видит страницу еще до того, как пройдет гидрейт.
Как мы собираем метрики? Для сохранения данных мы делаем запрос на наш служебный урл
/stat, в котором описываем наши метрики.Затем эти данные парсятся и отправляются в хадуп. Кроме хадупа отображаем данные в okmeter.io. Собственно, все графики оттуда.
Пример такого запроса:
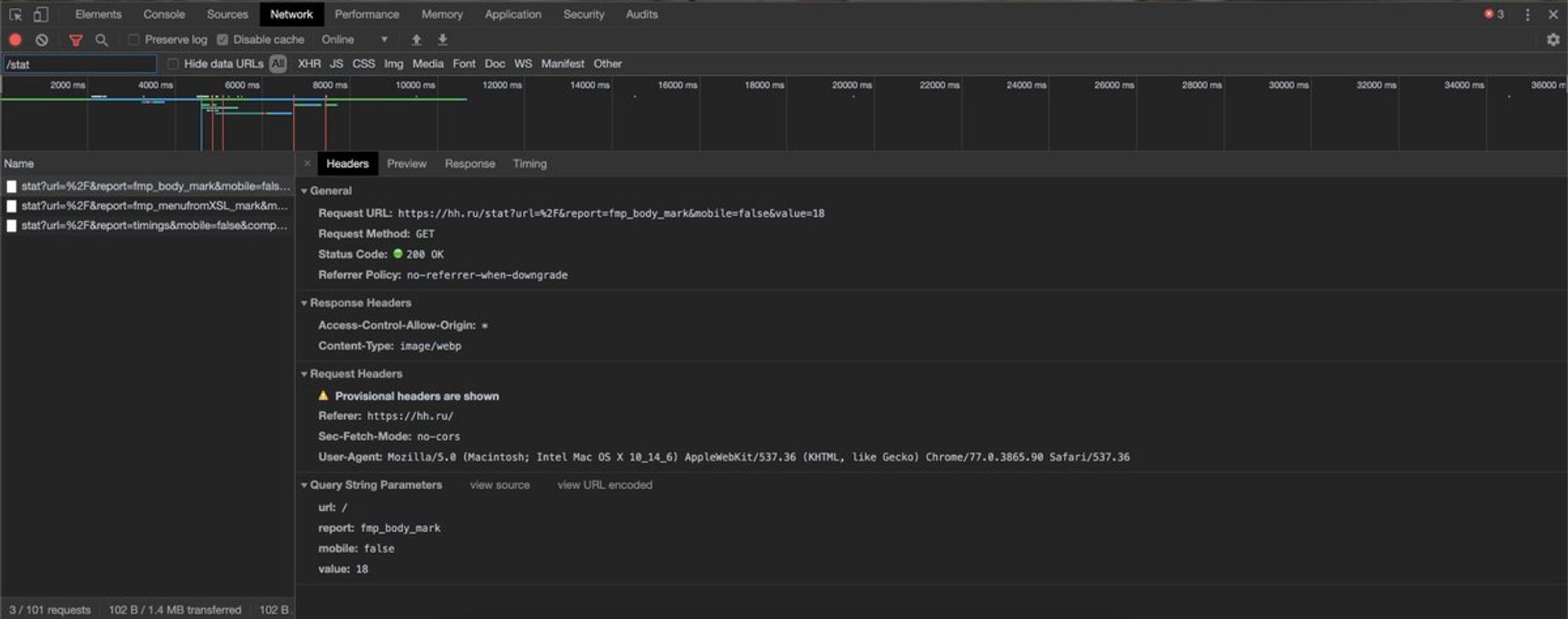
okmeter платный, но всегда можно поднять Prometheus с grafana: prometheus.io grafana.com
Тред (@xnimorz)
Зачем вообще метрики на клиенте? Зачем так заморачиваться, если есть lighthouse? web page test?
Страницы динамические, на них меняется контент, есть код подрядчиков
У клиентов разные устройства. Мы получаем не репорт в вакууме, а реальные данные
Данные собираются постоянно (все обезличено), это открывает много возможностей для аналитики
Мы можем реагировать максимально быстро на деградации, как во время релиза, так и после
Тред (@xnimorz)
@jsunderhood Одно не могу понят, почему при проверке сайта, всегда разные показатели получаются. По паджу все ок а лайтхауз хрень показывает)
Много процессов еще в системе запущено? Возможно, кто-то тянет одело процессорного времени на себя.
И опять же: у сайта может быть разная нагрузка, сервер разное время отвечает и т.д. Причин тысячи :) поэтому удобно снимать данные с реальных клиентов. twitter.com/airklimat/stat…
Эксперименты с производительностью. В начале года мы запустили 4 эксперимента.
два на улучшение производительности сайта и два на ухудшение. Эксперименты запускались на небольшую часть пользователей
Эксперименты на улучшение производительности
Используем brotli вместо gzip. Это влияет на всю статику. Точные цифры экономии в Kб не вспомню, но это >100 Кб.
Используем кеширование через Service worker
На технических измерениях во время разработки, профит был заметен. Когда раскатили на клиенты большой производительности не было заметно. Бизнес метрики, к сожалению, не изменились.
Мы сделали два вывода:
Нужно будет повторить эксперименты с более сильной оптимизацией
На небольшие оптимизации клиенты нечувствительны
Затем мы запустили 2 эксперимента на деградацию. Эксперименты на деградацию нужно запускать очень осторожно, потому что изначально непонятно, насколько деградация влияет на деньги.
Мы замедляли инициализацию наших компонентов (TTI)
Увеличили размер загружаемого css (FMP)
Про инициализацию компонентов. Мы сделали небесконечный цикл, который тормозил инит каждого компонента на небольшое количество времени, в сумме увеличивая время TTI на полсекунды.
Какое же было удивление, что бизнес-метрики ничего не почувствовали. Мы запускали эксперимент несколько раз (на разных группах пользователей, чтобы получать репрезентативные результаты), постепенно увеличивая время инита.
Этот эксперимент позволил нам сделать вывод: пользователям главная ценность нашего сайта — это возможность читать контент. Текст вакансии, резюме, поисковую выдачу и т.д.
Так как текстового контента много, они не замечают, что сами компоненты становятся интерактивными через некоторое время.
Подтвердил нашу гипотезу эксперимент с увеличением загружаемого css. Это напрямую влияло на FMP. В бизнес-метриках появились незначительные деградации по итогам эксперимента.
Результаты экспериментов получились такие:
Наиболее важный параметр, на котором нам нужно сосредотачиваться FMP.
Очень важно не допускать деградации по нему.
К прямой зависимости (некоторой формуле) денег от производительности мы, к сожалению, не пришли. Нашли только характер зависимости. Поэтому мы донастроили графики, чтобы реагировать на проблемы.
И включили оповещение при деградациях.
Тред (@xnimorz)
Что дают нам графики и подсчет метрик
Триггеры: если мы достигаем пика в 5/10 секунд (в зависимости от метрики), то к нам в чат прилетает сообщение о проблеме, с описанием страницы. Разработчик грепает и разбирается в проблеме.
Динамика релиза: Как только выходит релиз мы видим на графике все деградации и оптимизации. Если деградация большая (графики улетели на 2 секунды скажем вверх), релиз откатывается
Также мы трекаем данные с клиента для аналитики: мы можем посчитать и сравнить метрики для части пользователей (например, если запускаем эксперимент) или за определенный период времени.
Тред (@xnimorz)
Может появиться вопрос, а почему SSR за оптимизацию производительности не считаете?
Почему с ним не проводили экспериментов?
>>>
Я склоняюсь к тому, что SSR крайне важен, чтобы на сайте, который доступен неавторизованному пользователю его отключать или вообще допускать, что его может не быть.
Я писал, что можно не получить профитов от кеширования:
Вот статья первая статья, для меня оказалась крайне полезной: v8.dev/blog/cost-of-j…
В чем же соль?
TL;DR: Используйте Cache API для статики в Service Worker. Этим вы экономите время исполнения кода, улучшаете TTI.
Дело в том, что не все браузеры кешируют файлы меньше 1Кб. За счет этого мы можем не получить профита от того, что выносим js из inline кода в блокирующий ресурс.
Как устроено кеширование в хроме? Здесь на эту тему хорошо написано: v8.dev/blog/code-cach…
Вся информация дальше — это компиляция из этих статей. Эдакий TL;DR. Справедливо для chromium браузеров
У нас есть 3 способа "запуска" кода. Cold run, warm run и hot run:
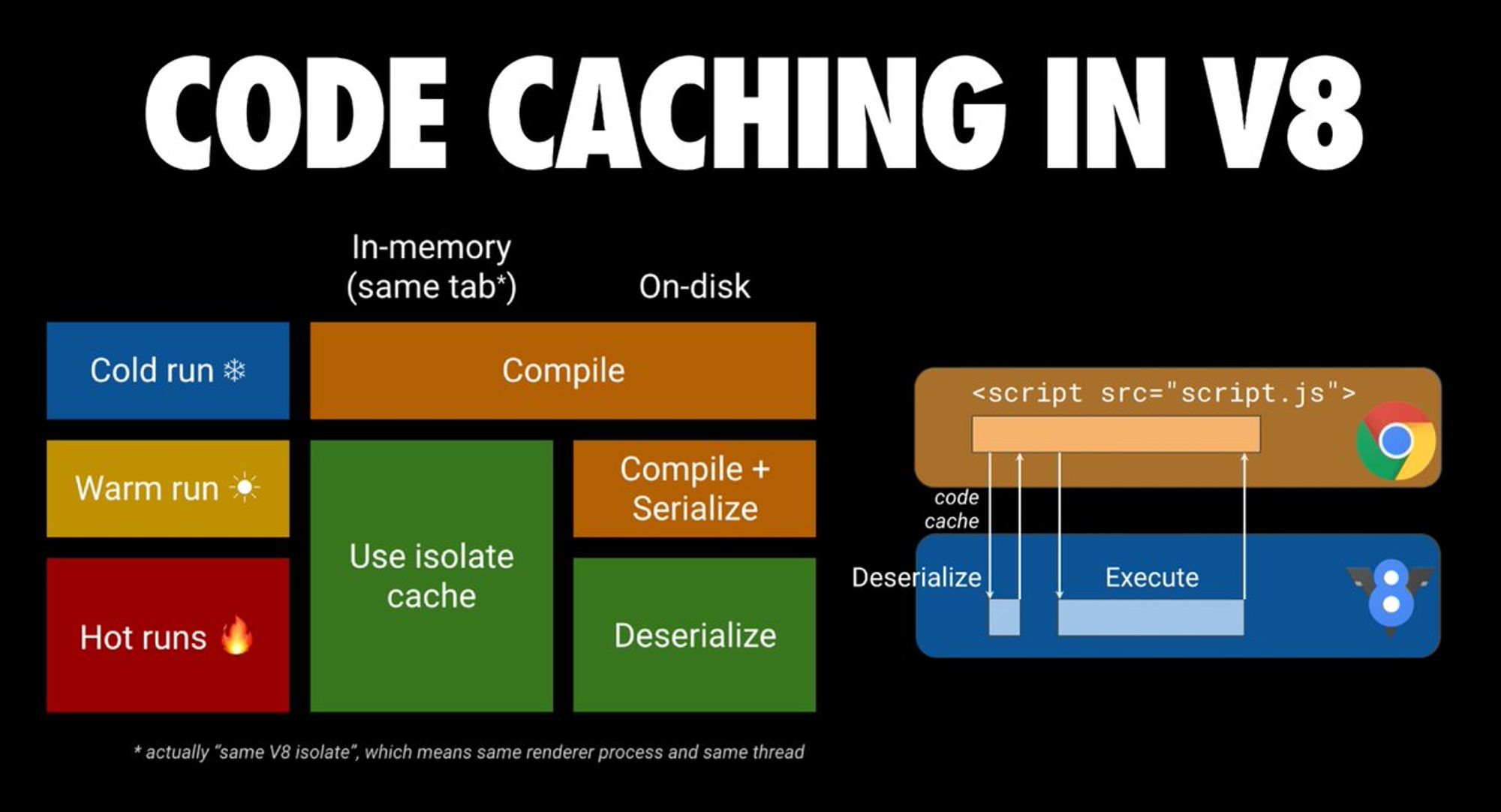
Cold run — пользователь пришел впервые. Браузер скачал файл, скормил его компилятору (транспилятору)
Warm run — пользователь пришел повторно. Браузер взял код из кеша, скормил его компилятору.
Hot run — пользователь пришел в 3-й раз за последние 72 часа.
Браузер взял код и метаданные из кеша. Метаданные десериализуются и исполняются. Компилировать не нужно.
Всем хочется исполняться на в hot run версии. Очевидно, что она экономит время.
Первый способ экономить время — не пишите код ¯_(ツ)_/¯
Кроме того, не забывайте про etag и заголовки для кеширования кода.
Есть интересный хак, чтобы забустить hot run. Используйте Cache API от Service worker
"Магия" здесь в том, что файл, кешированный сервис воркером не будет парситься повторно, метаданные будут присутствовать.
Вот так сейчас выглядит загрузка hh.ru:
Тред (@xnimorz)
Еще одна ссылка: youtube.com/watch?v=bZfULA…
Здесь рассказываю о способах увеличения производительности и затрагиваю тему кеширования.
Еще приведу доклад @iamakulov о performance: youtube.com/watch?v=iEv1rF…
Тред (@xnimorz)
FMP — от него хотим следующего: понимание нашего critical path, количества времени которое уходит на него. Дальше будет очень большой тред с большим количеством графиков и сравнений:
(1/2) Ссылки на темы за сегодня:
Кеширование в chrome: twitter.com/jsunderhood/st…
Профит от графиков: twitter.com/jsunderhood/st…
Эксперименты по performance: twitter.com/jsunderhood/st…
FMP (рекомендую почитать, так как здесь много информации, не только о FMP): twitter.com/jsunderhood/st…
Я выступал на РИТ++ youtube.com/watch?v=4joeMk…, рассказывал о сборе метрик и частично затрагивал эксперименты с производительностью.
(2/2) Зачем собирать метрики: twitter.com/jsunderhood/st…
Зачем мы все затеяли: twitter.com/jsunderhood/st…
TTI twitter.com/jsunderhood/st…
Framework init time: twitter.com/jsunderhood/st…
FID: twitter.com/jsunderhood/st…
SSR: twitter.com/jsunderhood/st…
Доклады: twitter.com/jsunderhood/st…
Пара причин для этого:
SEO — поисковым ботам нужно что-то индексировать
отсутствие SSR заметно оттягивает время FMP. По сути, он станет очень близок к TTI. Если на сайте много скриптов, как у нас, это деградация в 2-2.5 раза!
@jsunderhood какой есть хороший ssr для реакта кроме некста?
Я не могу взять и сказать: используйте next.js, gatsby или react-static. Зависит от решаемой задачи. twitter.com/sexymuhamedik/…
Готовые решения имеют свои ограничения. Мы сделали свое простое решение без излишеств twitter.com/i/web/status/1…
gatsby и next.js дают вам очень удобный и простой старт. gatsby может быть "не только 100% статикой" из коробки работает с graphQL API
react-static никогда не пробовал, говорят удобен для статических сайтов. Но
Статический сайт можно сделать на том же gatsby
Если вы хотите использовать реакт для статического сайта — появляется вопрос, нужен ли реакт.
@jsunderhood Ну Некст используется на проекте главным образом для seo оптимизации реакт приложения А вот csr сделать сео френдли вообще достижимо? Или лучше сср все таки для этой цели?
Классный вопрос. На самом деле "все очень плохо".
Мои коллеги смотрели, какие деградации для SEO будут, если использовать только клиентский рендеринг.
Есть доклад на google I/O на эту тему: youtube.com/watch?v=PFwUbg…
Картинка не самая честная, полагаться на нее полностью не стоит: twitter.com/sexymuhamedik/…
И пара статей:
Для гугла: developers.google.com/search/docs/gu…
Для яндекса: yandex.ru/support/webmas…
Коротко: что-то работает, но что получится — на ваш страх и риск.
Воскресенье
@jsunderhood @andrey_sitnik Для статического сайта, если не реакт, то другой шаблонизатор. Соль в том что (п)реакт даже в таких условиях удобнее каких-нибудь Mustache или Jade.
Здесь есть несколько особенностей:
Полностью статический сайт всегда можно прекомпилировать и получить на выходе готовые html файлы без шаблонизации во время запроса. Это можно сделать на любой технологии в том числе на (п)реакте. Gatsby, react-static так делают очень легко. twitter.com/snejink/status…
Иногда сайт нельзя полностью прекомпилировать. Например, будут небольшие кусочки типа "комментарий пользователя" и тогда шаблонизировать будем в момент запроса (+ можно настроить кеширование в условном memcache или даже nginx)
Главная же проблема в реакте для такой задачи — что на клиент обычно поставляют весь бандл кода, который большую часть времени тратит на то, чтобы загрузиться, проинициализироваться, сделать гидрейт.
А полезного кода, который отправит и красиво добавит комментарий без перезагрузки страницы — это от силы останется 5% от общего бандла.
Мы получаем проблему, что выбрали действительно хороший и мощный инструмент, но его используем не самым эффективным образом...
Если делается такой сайт, а условный (п)реакт, вью хочется, я бы рассматривал такой вариант:
Сделайте 2 точки входа. Одна будет рендерить приложение на сервере, другая будет инитить рут-ноду только на блоке "комментарии пользователя" и именно она отправляется на клиент
Это позволяет вам не делать лишние телодвижения на клиенте. Код, который ничего не делает, на клиент не попадет.
Код не будет значительно переусложнен, потому что это можно разрулить по месту через process.env и на этапе создания бандла убрать оставшийся dead code
Единственное, еще и сама библиотека имеет свой размер. Например, вот реакт-дом: bundlephobia.com/result?p=react…
Тред (@xnimorz)
@jsunderhood В скраме дедлайн раз в две недели, а при канбане в умелых руках аврал и дедлайн каждый день, какое уж тут спокойствие разработчиков ?
Любой инструмент можно превратить в кошмар исполнителей. При удобном инструменте, который понимают, принимают и не эксплуатируют в корыстных целях все участники процесса, всей команде и менеджерам можно жить дружно и улучшать процессы. >>> twitter.com/damarkov/statu…
Поэтому Я бы сказал, что это другая проблема. Проблема "эффективных" менеджеров. Такие "друзья" могут встречаться часто. И они из любого подхода могут сделать аврал, горящие сроки и не только сроки.
Если у вас скрам, то не будем закладывать баги и мелкие задачи, вместо мелкой задачи возьмите пару фич. А потом на конце спринта "где таски на продакшене, Карл?". Они еще любят "оптимизировать" стори поинты команды во время спринтов.
Если у вас waterflow, то дедлайн будет идти только от такого менеджера.
Если канбан, то менеджер не будет делить задачи по классам поставки — "ха, зачем? вы вот эту задачку закончили за 3 дня и остальные задачки также давайте."
В канбане такой "эффективный" менеджер не хочет разбираться, что у команды есть, например 3 класса поставки (сроки для 85 перцентили):
баги, где они тратят 3 дня
типовые user story, на которые уходит 14 дней
исследовательские user story, на которые уходят по 30 дней.
Если вы хотите попробовать канбан, но боитесь такого подхода со стороны менеджеров: оставьте оценку задач и проговаривайте ориентировочные сроки с момента, когда возьмете задачу из беклога.
Тред (@xnimorz)
Мы успели обсудить много тем за неделю.
Браузерные плагины, процессы, kanban, визуализация, иконки, миграция стеков, развитие разработчиков, производительность и клиенсткие метрики. Но о многом можно еще говорить и говорить.
Сегодня не будет много твитов. Предлагаю поговорить на ваши темы. Если вам интересно какое-то направление, какая-то техническая тема или что-то в софт-скиллах, задавайте вопрос, постараюсь ответить :)
@jsunderhood Берём приложения на React, и делаем что хотим, а всякие там комментарии и другие отчуждаемые элементы вставляем через SSI. Готов поспорить что все эти евангелисты микро фроентендов это него и не слышали. nginx.org/en/docs/http/n…
Еще один вариант через server side includes :) twitter.com/theKashey/stat…
@jsunderhood Спасибо за продуктивную неделю! Вопрос: какой подход на собеседовании для кандидатов вы считаете наиболее эффективным и можете ли поделиться самым успешным и провальным вашим опытом на собеседовании? Заранее спасибо за ответ 😉
Я занимаюсь собеседованиями в HH уже 3 года без одного месяца :) Сейчас наше техническое интервью — это часть вопросов на рассуждение и часть на технические знания. >>> twitter.com/maRx_flowers/s…
За это время мы несколько раз переделывали наш подход к собеседованиям, потому что всегда "что-то не то". Был этап, где было техническое интервью со знанием кучи вещей в js. Был момент, когда кандидатам давали ноутбук с задачей, но от этого подхода мы ушли быстро.
Каждый раз, когда меняли собеседование мы в том числе пытались оценить: насколько подход удобный? Насколько собеседование делает нас уверенными в решении "мы сработаемся"?
Сейчас наше собеседование состоит из 3 частей. Разговор о прошлом опыте и об удобных процессах в компании для кандидата, техническое интервью и уже наш подробный рассказ о компании.
В техническом интервью мы всегда хотели понять: умеет ли рассуждать и решать проблемы кандидат?
Нас очень вдохновила вот эта статья от @vas3k: vas3k.ru/inside/46/
В последней итерации мы сделали переходы между разговором о прошлом опыте и техническом интервью в виде небольшого small talk, большинство вопросов заменили на задачки из своей практики без нашей специфики, чтобы просто получить рассуждения.
Но не все так хорошо как на бумаге. Например, мы периодически скатываемся только в технические вопросы. Есть немало вопросов с однозначным ответом.
Есть кейсы успешных собеседований. И я прям рад во время таких интервью: мы разговариваем с кандидатом о его опыте. Он рассказывает о сложных \ интересных задачах, которые решал.
Например, кандидат делал обработку табличных данных, как в гугл доках.
Мы разговариваем об этой специфики. Затрагиваем темы того же event loop, доступности и много-много другого.
Когда наступает в нашем воркфлоу этап технического интервью мы просто говорим о паре вещей важных для нас (например безопасности на клиенте) и пожимаем друг другу руки.
Мне кажется, у большинства нас есть примеры задач, который нас драйвили. Рассказывайте об этом на собеседованиях. Интервьювер обязательно заинтересуется.
Также у меня есть пара провальных опытов, но уже в качестве собеседуемого. Самая главная боль — когда собеседующему вообще не интересен ни твой опыт ничего. Зачем собеседовать, если тебе все равно?
И второй: когда собеседующий считает, что ответ должен быть не просто однозначным, но еще и слова должны быть точь-в-точь. Это тоже огромная боль.
Тред (@xnimorz)
@maRx_flowers @jsunderhood Ещё веселее когда: - вам задание, запилить вот эту вот специфическую фигню за 40минут - пилит - вы не уложились и вообще говнокод, дасвиданья - а ваши разработчики это пилят постоянно? - да нет, мы библиотеку используем, ей три года и 2к коммитов. :)
Я с таким, благо, не сталкивался 🙂 twitter.com/YouSysAdmin/st…
@maRx_flowers @jsunderhood а в чём поинт пробного дня? ты вряд ли сможешь сделать какую-то задачу (в сам проект ещё неделю минимум вкатываться будешь). единственное на что можно посмотреть, не открывает ли кандидат дверь с ноги и не обращается ли ко всем на "эй ты"
Тут должен процесс у работодателя быть настроенным. Чтобы человек познакомился с командой и поковырялся в небольшой задачке, которую можно сделать за день. Команда и тимлид видит, как работает сотрудник. Сотрудник может наблюдать за командой. Но процесс очень затратный, да twitter.com/almost_bergman…
@7rulnik @jsunderhood @YouSysAdmin @maRx_flowers Как и везде, кандидат мучается - а мы издеваемся ;)
Не могу не ретвитнуть 😀 twitter.com/mr_mig_by/stat…
@7rulnik @jsunderhood @YouSysAdmin @maRx_flowers А если на серьезных щах, то кандидат драйвит, а интервьюер помогает принимать решения и задаёт уточняющие вопросы на ходу. У нас обычно есть несколько параметров, под которые мы оптимизируем решение. Они озвучиваться и задача интервьюера за ними следить.
Хороший тред о собеседовании-задаче 🙂 twitter.com/mr_mig_by/stat…
@jsunderhood 1. Зачем разработчику математика? (Ответ «не нужна» не принимается) Какие софт-скиллы она тренирует? Адаптивность это софт-скилл? Как ее тренировать? Роль HR отдела в тренинге софт скиллов Влияют ли софт скиллы на тех скиллы?
Зачем разработчику математика? (Ответ «не нужна» не принимается)
Какие софт-скиллы она тренирует?
Я для себя принял такое: математика хорошо прокачивает пару вещей: аналитические скиллы и алгоритмы в более объемном понимании. twitter.com/mr_mig_by/stat…
Расскажу одну историю: когда я учился в 11 классе, я брал уроки репетиторства у вузовского преподавателя высшей математики.
В это время я участвовал в олимпиаде по программированию, и в ней не смог решить одну задачу.
В самой олимпиаде занял первое место, но как подойти к задаче не осознал.
На уроке разговорились с преподавателем и я ему рассказал задачу.
Он ушел думать.
К концу занятия (1.5) человек, у которого не было бекраунда в разработке дал четкий алгоритм, который решал задачу оптимальным способом.
Математика — это не только про найти интеграл.
Это навык решать задачи, оценивать их и оптимизировать. А иксы ли у вас с производными или элементы массива \ графы \ деревья или компоненты — не важно.
В той же высшей математике исходя из входных данных можно не знать \ забыть алгоритм нахождения интеграла — но его можно вывести.
Аналогично и в разработке.
И да — это нормально считать иначе :)
Тред (@xnimorz)
@jsunderhood 1. Зачем разработчику математика? (Ответ «не нужна» не принимается) Какие софт-скиллы она тренирует? Адаптивность это софт-скилл? Как ее тренировать? Роль HR отдела в тренинге софт скиллов Влияют ли софт скиллы на тех скиллы?
Адаптивность это софт-скилл? Как ее тренировать?
Влияют ли софт скиллы на тех скиллы?
Возможно мне подскажут. Мне сложно проводить однозначную черту между софт и хард скиллами. twitter.com/mr_mig_by/stat…
Пересечение и взаимное влияние я наблюдал во время своей работы.
Категоризовать: "ты однозначно софт скилл, ты — хард скилл" — мне сложно.
Например: обучаемость? она тоже бывает очень разная. Это может быть идеальная память на механические вещи. А может быть человек не просто наблюдает, но еще осознает, пропускает через себя.
Но сказать — первый плохой, второй хороший — нельзя. У этих людей обучаемость прокачена по разным "веткам развития".
И к тому же это все зависит от контекста.
Если предположить, что обучаемость — софт скилл, то да, мы посмотрели пример, что он влияет на технический скилл.
Тред (@xnimorz)
@jsunderhood 1. Зачем разработчику математика? (Ответ «не нужна» не принимается) Какие софт-скиллы она тренирует? Адаптивность это софт-скилл? Как ее тренировать? Роль HR отдела в тренинге софт скиллов Влияют ли софт скиллы на тех скиллы?
Роль HR отдела в тренинге софт скиллов
Тут скажу 2 вещи:
Роль хороших HR менеджеров — будет высока.
Роль плохих HR менеджеров — будет такая, что "лучше бы не лезли в софт скиллы"
Понятное дело, что поделить на черное и белое не получится. twitter.com/mr_mig_by/stat…
Мне удалось поработать с разными HR менеджерами. Некоторым было "глубоко все равно", что происходит в процессах компании.
Другим — было важно идти в направлении обучения и развития разработчиков.
Такие хорошие hr менеджеры, могут выступать не просто консультантом \ источником бюджета, но и драйвером в прокачивании людей.
Они могут помочь тимлиду создать прозрачную систему работы с командой, определить сильные и слабые стороны разработчиков (в том числе и софт скилов)
Затем выработать рекомендации, помочь с поиском подходящих курсов.
В общем, да, роль HR отдела может сильно варьироваться в компании.
Тред (@xnimorz)
Спасибо, что были со мной эту неделю 🙂
С вами был @xnimorz . В своем твиттере я пишу редко и обычно связанное с разработкой. Мой русскоязычный акк: @nikmostovoy
Приходите на мой доклад на HolyJs 9 ноября: holyjs-moscow.ru/2019/msk/talks…
Будет круто и интересно :)
И большое спасибо @DmitryMakhnev и @rage_monk вы очень прокачали мой доклад и сделали его круче :)