Архив недели @pgurtovaya
Понедельник
Всем привет. На этой неделе с вами будет @pgurtovaya . Я занимаюсь фронтом примерно пять лет, несколько из них в Злых марсианах.
Иногда я выступаю на конференциях и пишу статьи в марсианском блоге. Я рассказываю об очевидных вещах и на этой неделе планирую делать то же самое :)
Немножко расскажу о себе:
Долгое время программирование было моим хобби и мне даже не приходило в голову заниматься этим профессионально.
В какой-то момент мне стало скучно разрабатывать всякие железяки и захотелось поработать в области, где можно решать почти любые задачи и где физика не работает против тебя. Так я и стала фронтендом :)
Давайте сегодня поговорим про полезные для фронтенда (и не только) скиллы. Сразу хочу предупредить, что мое мнение на этот счет немного специфическое и далеко не все с ним согласятся. Но так только интереснее :)
Когда я только начинала заниматься разработкой я считала, что для того чтобы расти и развиваться мне нужно изучить как можно больше технологий. Для начинающих разработчиков это, пожалуй, хорошая стратегия. Но набор и сложность технологий это не главный определяющий фактор
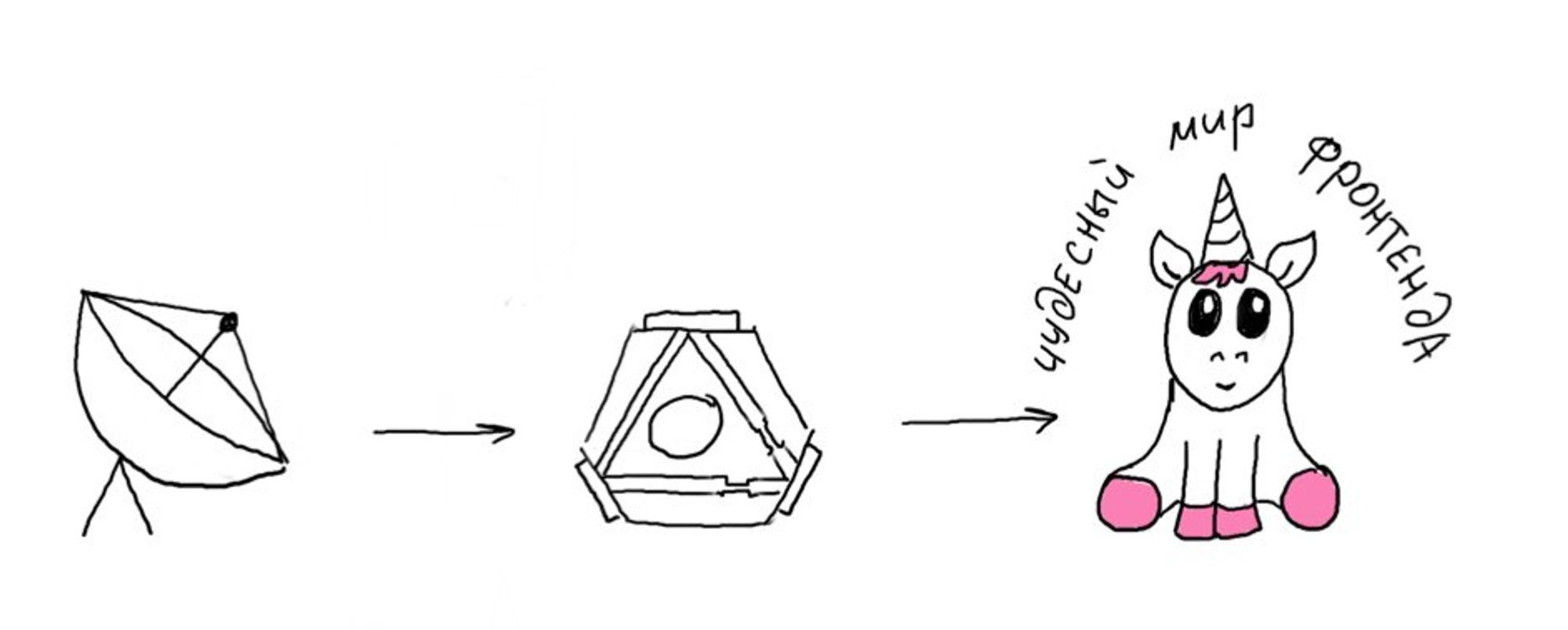
Полезный скилл номер раз – умение правильно и быстро понимать свою задачу. Круто переходить от вопроса "Что мне нужно сделать?" к вопросу "Зачем я это делаю?".
Распространенный пример: "Нам нужна сотка на Lighthouse!111". Мой первый вопрос – "зачем?". Часто оказывается, что нужно совсем другое. Например, приложение работает недостаточно быстро и нужно подправить несколько узких мест или пофиксить косяки связанные с SEO.
Lighthouse отличный инструмент (об этом мы поговорим чуть позже), но это всего лишь инструмент.
Иногда, чтобы понять причину того что вы делаете приходится провести небольшое расследование и задавать вопросы.
Чтобы лучше понять свою задачу неплохо разобраться для кого мы разрабатываем наше приложение. Посмотреть как ведут себя пользователи, какие устройства они используют и какие кнопочки тыкают.
Многие считают что аналитика нужна чтобы снижать производительность вашего приложения при загрузке :)Но она бывает полезна, чтобы составить представление о том, что делают ваши пользователи.
Попросить доступ в аналитику почти всегда хорошая идея.
Заодно можно найти там страшных монстров, типа layout recalculate на mousemove без тротлинга, заботливо скопипасченый кем-то из аналитиков :)
Тред (Полина Гуртовая)
Отдельно надо сказать еще об одной очевидной штуке – метриках вашего приложения.
Есть технические метрики (например Time to Interactive), есть более "бизнесовые" (например конверсия для какого-нибудь действия).
Все эти метрики связаны между собой. Как правило у вашего приложения есть небольшой набор целевых метрик. Эти метрики нужно хорошо
понимать и уметь их использовать.
С первого взгляда может казаться, что фронтендам вся эта бизнесовая история совсем не нужна. Это почти всегда не так :)
Если у вас есть метрика, у вас есть количественное понимание вашей цели. Если у вас есть метрика, вы можете использовать её для экспериментов.
Если вам хочется запилить новую фичу, то хорошее объяснение будет звучать примерно так:
"Давайте выкинем эту ужасную JS-анимация на 1к строчек кода. Я предполагаю, что это никак не изменит метрику X".
Дальше вы проводите эксперимент, и у вас есть циферки, которые вы можете сравнить. Циферки это всегда хорошо :)
Тред (Полина Гуртовая)
Полезный скилл номер два (и на мой взгляд самый-самый важный): чувство прекрасного.
Большинству фронтов приходится в своей работе создавать интерфейсы. Чем лучше у вас прокачено чувство прекрасного – тем лучше получится.
Чаще всего вам предстоит создавать новый интерфейс вместе с дизайнерами. Редко дизайнер может продумать все за вас. Вместе вы сможете учесть больше намного больше деталей.
Например, разрабатывая приложения для видеоконференций нужно примерно понимать как работает видео в браузере. Какие кодеки возможны, какие могут быть (а могут и не быть :) соотношения сторон и режимы.
Приходится учитывать, что перед тем как включить камеру нужно попросить у пользователя разрешение, а так же то, что пользователь эти разрешения может отозвать.
Мой опыт показывает, что если вы предварительно побрейнштормите над задачей вместе с дизайнером у вас получится намного лучше, чем если вы получите уже готовую задачу.
Тред (Полина Гуртовая)
Как можно прокачать чувство прекрасного?
Для меня самый лучший способ – поучиться у людей которые в этом разбираются. В марсианах я часто прихожу в дизайн-чатик и задаю вопросы о сочетаниях цветов, о шрифтах и о том как в интерфейсе решить какую-нибудь хитрую задачу.
Полезно посмотреть какие-нибудь курсы или почитать книжки (типа The Design of Everyday Things)
Можно сделать пет-проект основной задачей которого будет создание удобного интерфейса.
Можно посмотреть на что-нибудь красивое. Вот список телеграм-каналов с красивыми картинками от наших дизайнеров
t.me/ayuev
t.me/newsrgb
t.me/loveandlayouts
t.me/typolinks
t.me/zwetz
Просмотр красивых картинок не поможет решать серьезные UI проблемы, зато может научить замечать некоторые косяки верстки (например, неправильные отступы)
Тред (Полина Гуртовая)
Полезный скилл номер три – конвертация мысли => текст. Наверное, вы уже заметили, что у меня с этим не очень хорошо, но я стараюсь исправиться :)
В марсианах быстро превратить свою мысль в сообщение особенно важно – ведь вся наша рабочая коммуникация происходит в слаке.
Кроме сообщений в чатах я пишу комментарии к своему коду, комментарии к чужому коду (code review), технические доки, статьи, письма etc.
Написание всего этого кушает много рабочего времени а от качества написанного иногда зависит судьба новой фичи.
Поэтому прочитать несколько книг по теме кажется мне неплохой идеей. Больше всего мне понравилось "On Writing Well: The Classic Guide to Writing Nonfiction". Если хочется чего-то на русском, то можно попробовать почитать "Пиши, сокращай".
Если читать не хочется, то вот несколько простых правил:
Перечитать написанное и выкинуть половину.
Перечитать то что получилось вслух и выкинуть еще половину.
Короткие слова лучше длинных.
Длинные предложения лучше разбить на короткие.
Для текстов на английском лучше использовать Grammarly.
Не будьте как я и ставьте правильные кавычки :)
Тред (Полина Гуртовая)
Вторник
Сегодня плавно переходим к техническим вопросам и заодно продолжаем разговор о полезных навыках.
Давайте обсудим полезность "академического бекграунда". Как вы считаете что и в каком объеме нужно знать фронтендам? Data-Science, простая математика, графы, ML, DL, ТФКП?)
🤔
12.9% Ничего не нужно🤔
23.5% Школьная математика🤔
17.1% Базовый курс Data-Science🤔
46.5% Побольше про архитектуруИнтересно что вариант "Ничего не нужно" набрал так мало голосов :)
Я считаю, что академический бекграунд очень полезен.
Однако отсутствие подобного бекграунда ни в коем случае не является проблемой. В любой задаче легко разобраться учитывая тонны качественного обучающего контента. Пригодиться может все что угодно. В тредике будут примеры
Узнаете картиночку?)
^ кривые Безье это не только easing для анимаций.
Ими еще можно рисовать стрелочки. Я нарисовала очень много стрелочек за свою не очень долгую карьеру :)
Как-то раз мне пришлось верстать страничку с текстом в рамочках.
Рамочки должны были выглядеть как будто кто-то в спешке обвел текст маркером. Вместо того чтобы вставлять каждую рамочку унылой картинкой, я написала скрипт который генерирует рамочки (несколько кривых Безье)

Школьная физика тоже очень помогает. Например если вам нужно запилить взрывающиеся конфети... или вертолеты :)
@jsunderhood Мне однажды теория графов пригодилась. Я делал что-то типо редактора разветвленных диалогов для игры в вебе, и самое простое оказалось это представлять диалоги как граф и применять к нему соответствующие алгоритмы.
Теория графов это отдельная, очень интересная история. Есть куча задач где она может быть полезна. Так что посмотреть что-нибудь по теории графов однозначно стоит. Есть крутые курсы от MIT и от МФТИ twitter.com/eatmeplzzz/sta…
Для рисования часиков и pie-chart пригодится тригонометрия.
Старая, но очень полезная статья на MDN в которой есть все что нужно про кривые developer.mozilla.org/en-US/docs/Web…
Тред (Полина Гуртовая)
Линейная алгебра/аналитическая геометрия (матрицы и векторы) очень полезный для фронтенда склилл. Особенно если вы хотите что-то анимировать или просто передвигать на странице. Если вы делаете что-то связанное с 3D... ну тогда вы и так все знаете :)

Всегда можно посмотреть что-то по теме от MIT
ocw.mit.edu/courses/mathem…
И последняя тема на сегодня – зачем же фронтендам Data Science?
Сразу предупреждаю – я не настоящий сварщик :)
Первая причина – ML/DL это жутко весело. Просто попробуйте и вы поймете о чем я говорю.
Есть множетсво способов начать экспериментирвать, например можно почитать статью (хотя довольно старенькую) в марсиансом блоге:
evilmartians.com/chronicles/lea…
А вот очень классный курс atcold.github.io/pytorch-Deep-L… (но он немножко академический)
Используя ML/DL можно решать множество разнообразных задач.
Мне, например, как-то пришлось детектить лица прямо в браузере :)
Используя нейросеточки можно улучшать наши инструменты, например есть очень популярная история про DL-based autocomplete marketplace.visualstudio.com/items?itemName….
Можно улучшать/подбирать качество изображений и распознавать речь прямо в браузере.
Я очень хочу поэксперименировать с миксом PyTorch и Wasm, хотя понятия не имею что из этого получится.
Но я обязательно расскажу :)
А пока можно посмотреть на прикольные примерчики TensorFlow tensorflow.org/js
Самый простой случай - это уже обученая моделька которую вы затаскиваете в браузер и натравливаете на ваши данные. Детектировать котиков можно примерно в 5 строчек JS и одну большую XMLку :)
Тред (Полина Гуртовая)
Среда
Давайте поговорим о пет-проектах.
Заниматься своими основными задачами иногда бывает скучно.
Чтобы работа не превратилась в ужасную рутину, которая видится как "верстка по макету на React" стоит иногда отвлекаться и развлекаться.
При этом можно поэкспериментировать с новой технологией, а заодно прокачать математику и физику. Один из моих любимых способов это сделать – generative art aiartists.org/generative-art….
Меня завораживает то, какие прикольные штуки можно создавать используя CSS/JS и немного рандома. Получившиеся асеты можно сохранить как картинку или даже распечатать на 3D принтере.
В процессе могут возникнуть интересные performance – челенджи (ведь приходится генерить кучу элементов а потом их анимировать)
Не стоит экспериментировать на TODO-листах, лучше что-нибудь нарисовать :)
Тред (Полина Гуртовая)
Теперь про архитектуру (кстати она победила в опросе про академический бекграунд :)
Разумеется, думать об архитектуре, понимать общие паттерны, использовать современные практики – важно. Но меня не оставляет ощущение что в нашей сфере сейчас очень сильный перекос
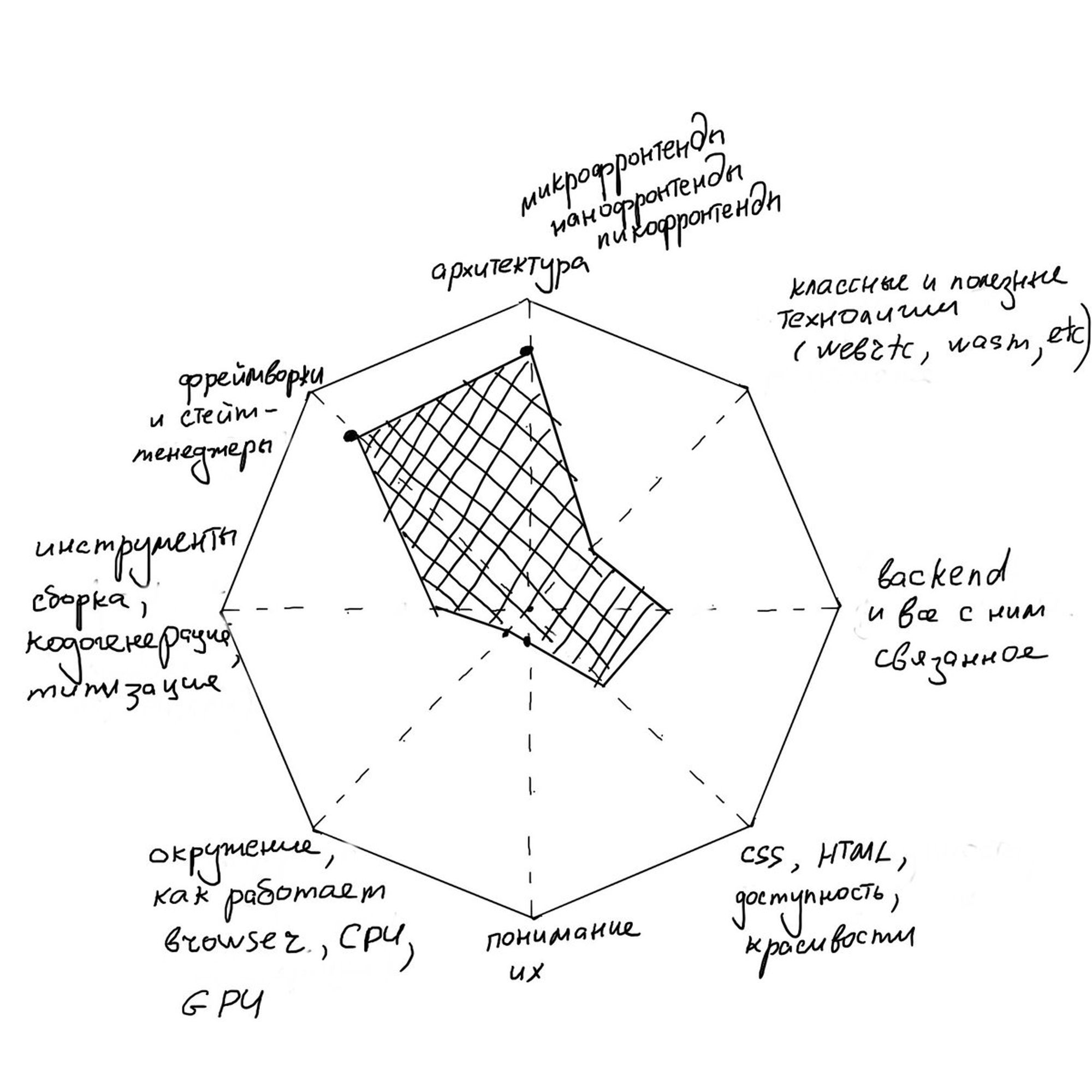
А вот и State of JS. 2020.stateofjs.com/en-US/
Стало чуть больше Wasm ❤️. Количество знающих и юзающих WebRTC подросло, но как-то не слишком сильно. PWA тоже побольше (ну а как иначе :)
Все любят TypeScript и Svelte. Graphql и Apollo все популярнее. Грустно видеть moment.
Gatsby слегка теряет популярность (и мне кажется это неплохо, ибо он слишком сложен под крышкой)
Testing Library прекрасная штука
Snowpack ❄️
Четверг
Сегодня поговорим про коммуникацию между людьми и сервисами.
Начнем с того что посложнее – общения с людьми и code review в частности.
Мне кажется, участвуя в code review, очень-очень важно быть вежливым. Давайте посмотрим как это лучше делать.
Каждый раз когда я делаю git commit, я предполагаю что его будут ревьюить и поэтому стараюсь упростить жизнь людям, которые будут этим заниматься.
Например, я не в состоянии качественно отревьюить PR больше чем на 500 строк. Поэтому стараюсь таких не создавать.
При ревью я первым делом смотрю на историю коммитов, поэтому, отдавая свой код на ревью я стараюсь чтобы это действительно была история, а не 'temp, fix, add component'
Хорошо бы сделать так, чтобы переключившись на любой коммит из вашего PR ничего не ломалось и было явно видно какой атомарный кусочек новой фичи или фикса в нем пилился
В процессе разработки (особенно если пилится что-то большое или мы делаем какой-то сложный рефакторинг) история и содержимое коммитов могут получаться немного хаотичными. Хаос ревьюить очень сложно
Я считаю хорошей практикой готовить свой код для ревью. И для этого нужна всего одна простая команда -
git rebaseЯ часто слышу что rebase и последующий forcepush это опасно и ужасно. На самом деле все ровно наоборот. Ребейзить и форспушить очень полезно. Просто нужно понимать как это работает.
🚨 Онлайн-митап по фронтенд-перформансу докладами от @xufocoder и @mlfrg уже через неделю! Нажми "Я иду", подпишись на канал youtube.com/c/TverIO, чтобы не пропустить начало трансляции. meetup.com/tverio/events/… pic.twitter.com/M7vxNqObLI
Мне очень нравятся митапы @_tverio . В них прикольно участвовать как в качестве докладчика так и в качестве слушателя. Следующий будет на тему performance. twitter.com/_tverio/status…
Я почти всегда делаю rebase c флагом --onto. Просто потому что не помню как работают другие варианты синтаксиса :)
Перед тем как сделать PR я делаю интерактивный rebase. При этом я переименовываю часть коммитов, разбиваю на части слишком большие, меняю их порядок. После этого можно форспушнуть все что получилось. Форспушить в свою ветку всегда безопасно.
Форспушить в общую с коллегой ветку тоже можно, но тут нужно быть аккуратнее и использовать флаг --force-with-lease (У нас в блоге есть об этом статья, которую я здесь не привожу ибо она портит нам статистику своей популярностью :)
Есть удобный трюк с флагом --fixup. Вы делаете коммит (когда угодно в вашей ветке) примерно так:
git commit --fixup [ссылка на коммит к которому относятся ваши правки]
Дальше при rebase используете флаг --autosquash и вуаля. Ваши правки помержились в нужный вам коммит.Тред (Полина Гуртовая)
В отдельном тредике обсудим что делать, если фича которую предстоит отдать на ревью очень большая.
Если такое произошло, то скорее всего что-то пошло не так изначально.
Когда я начинаю работать над новой задачей, то первое что я пытаюсь сделать – разбить ее на мелкие, но логичные итерации.
Эти итерации можно отдавать на ревью постепенно. При этом злые баги поймаются раньше и не придется долго ждать результатов ревью.
Ревью предыдущих итераций не блокер для дальнейшей разработки, ведь не обязательно открывать PR прямо в основную ветку.
Если фича состоит, скажем, из двух итераций: 'Компонент Вертолет' и 'Взрывающийся Вертолет', то можно открывать PR вот так:
dev <- 'Компонент Вертолет'
'Компонент Вертолет' <- 'Взрывающийся Вертолет'
То же самое можно делать если уже есть 10к строк готового кода. Разбиваем его на кусочки, запихиваем каждый кусочек в свою ветку и отдаем каждую на ревью. Минус такого подхода в том, что при правках придется ребейзить ветки.
Примерно так же удобно работать если в новой фиче есть и бекенд и фронтенд и вы живете в одном репозитории. Тогда выбирается главная ветка, например бекенд, и на нее постоянно ребейзится фронтенд
Иногда бывает удобно создать PR из основной ветки в пустой или какой-то специальный коммит. Эта ветка никогда никуда не помержится, но там можно вести долгие беседы о прекрасном :)
Тред (Полина Гуртовая)
Вот еще несколько полезностей для code review
Настроить автоматический деплой всех веток. Обычно я провожу ревью в 2 этапа. На первом просто смотрю код, а на втором проверяю что он работает. Мне всегда ужасно лень переключаться на новые ветки и запускать всякое. Лучше когда есть ссылочка "Что получилось смотреть вот тут"
Не использовать человеческие ресурсы для проверок с которыми могут справиться наши линтеры или другие полезные инструменты
Настроить хуки и держать в страшной тайне флаг --no-verify.
В марсианах мы так любим хуки, что даже запилили специальный инструмент для работы с ними evilmartians.com/chronicles/lef….
Самое простое повесить все проверки на pre-commit, но это не всегда оказывается удобным. Я люблю делать мелкие коммиты и меня раздражает если проверки гоняются слишком долго. Поэтому, я иногда перевешиваю слишком долгие проверки на pre-push
Тред (Полина Гуртовая)
Переходим к коммуникации с внешними источниками данных. Для начала общий опрос-вопрос: как бы вы описали бекенд(ы) вашего текущего проекта?)
🤔
38.0% надежный источник данных🤔
28.0% причина сложности клиента🤔
14.7% моя любимая часть поекта🤔
19.3% мой ночной кошмарПятница
Переходим к коммуникации с внешними источниками данных. Для начала общий опрос-вопрос: как бы вы описали бекенд(ы) вашего текущего проекта?)
Круто что для многих бекенд это надежный источник данных! К сожалению это не всегда это так. twitter.com/jsunderhood/st…
Есть проекты, где интеграция с бекендом заставляет значительно переусложнять клиентский код или добавлять прямо-таки удивительные проверки, типа "если вам пришел список элементов, сделайте еще пару запросов чтобы убедиться что он правильный".
Мне самой часто приходилось писать сложные маперы, чтобы превратить внешние данные во что-то подходящее для клиента. Поэтому сегодня мы говорим об интеграции с бекендом

В тредике появился патерн BFF, который потенциально должен побеждать сложные интеграции. Во многих случаях это отличное решение, но давайте сделаем шаг назад.
Перед тем как утверждать "нам нужно архитектурное решение X" неплохо еще раз посмотреть на свою задачу, на доступные ресурсы, на клиентов использующих ваше API и самое главное на команды которые этим занимаются :)
Сложные архитектурные решения могут появляться из-за того что несколько людей и/или команд просто не смогли договориться.
Мне кажется, что перед тем как распиливать все на микрофронтенды, внедрять BFF и прочие прослойки можно попробовать сформулировать:
- Что нужно клиенту
- Что может текущий/будущий бекенд
- Можно ли сделать наш интерфейс удобным для пользователя не переусложняя интеграции
Я всегда за максимально простую архитектуру и итеративное ее усложнение. Главное не пропустить момент когда действительно нужно усложнять :)
Тред (Полина Гуртовая)
Работать на проекте с надежным и понятным backend-API очень здорово. Список того, что нужно фронту от бекенда не очень-то и большой
Где-то есть асет, описывающий все что может прислать мне бекенд
Бекенд никогда не пришлет мне того, чего нет в описании. И мне никогда не придется искать null, спрятанный в мегабайтах JSONа
У фронта и бека есть контракт. Он распространяется на все их взаимодействия .
Множество сущностей, присылаемых с бекенда, строго ограничено потребностями моего интерфейса и у этих сущностей есть понятная мне связь.
Одна из технологий, которая выполняет все эти хотелки - GraphQL.
Когда я говорю о GraphQL я подразумеваю 2 вещи: формат запросов + execution engine который выдает ответы на мои запросы.
GraphQL не единственная технология, которая предоставляет строгий контракт. Так может делать RESTful апишка с OpenAPI (swagger) описанием.
Грубо говоря, RESTful + OpenAPI это некое обещание от вашего бекенда, а GraphQL – гарантия.
Ладно, я немного преувеличиваю и при желании сломать можно все что угодно :) Но, как показывает мой опыт, использую GraphQL очень сложно выстрелить себе в ногу.
GraphQL уже очень давно с нами, широко используется, но почему-то заблуждения насчет GraphQL все еще остаются.
Например, многие считают что GraphQL это что-то сверхгибкое, где можно попросить от бекенда все что угодно. Все ровно наоборот. GraphQL это строгая спецификация и ограничения.
Самая крутая фишка GraphQL – автоматически генерируемая документация. Для генерации доков не надо делать вообще ничего.
Полученные доки это замечательный референс, который позволяет экономить кучу времени при обсуждении формы вашего API.
Когда мне надо предложить какое-нибудь новое изменение в GraphQL API я просто кидаю расширение схемы в чатик
И мне не надо спрашивать бекендов "Как мне получить вот эту сущность?". Я просто тыкаю нужную ссылочу. При этом я точно знаю, что я получу ровно то что мне надо а не null или котика.
GraphQL может использовать любой транспорт. Пересылать данные можно почтовыми голубями. Однако чаще это делается по HTTP или веб-сокетам.
В GraphQL есть Subscription, который описывает стрим событий от сервера. Чудесный строго-типизированный стрим :)
Валидация запросов зашита в GraphQL engine. Если вы прислали невалидный запрос, GraphQL engine заботливо подскажет вам где вы ошиблись.
Конечно 500тку получить все же можно, если неаккуратно написать серверный код :)
Про схему и прикольные штуки которые можно с ней проделывать расскажу чуть попозже в отдельном тредике
Тред (Полина Гуртовая)
Тред о том что прикольного можно сделать с GraphQL схемой. Схема это строготипизированное описание всего-всего что умеет ваш бекенд.
Во-первых давайте покажу (ну вдруг кто-то не знает) как она выглядит.
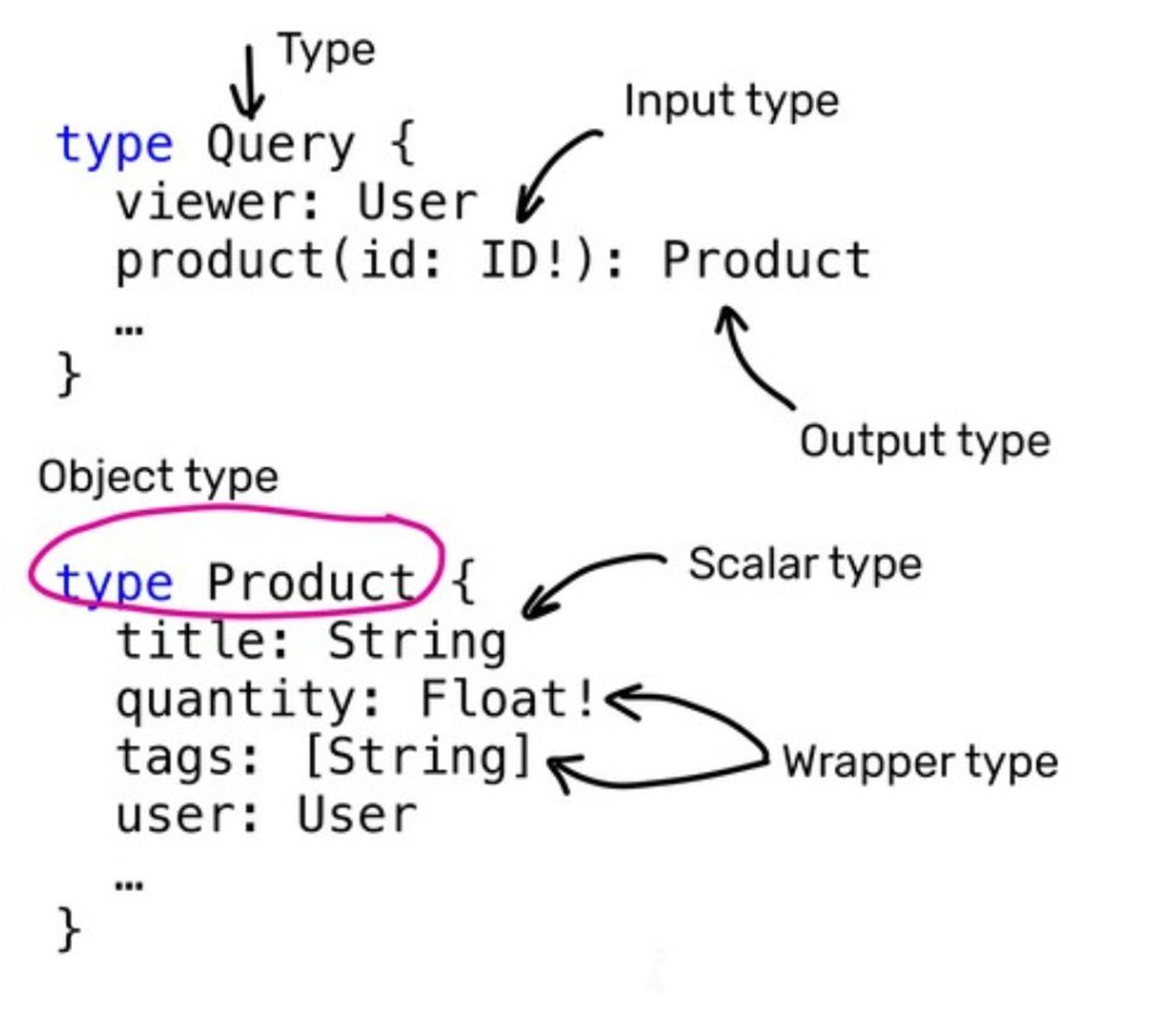
Схему можно куда-нибудь загрузить и использовать загруженное как референс. Можно использовать несколько разных версий схемы
Можно трекать историю изменений схемы (Apollo, например, предоставляет для этого удобный сервис)
Утащив схему на клиент, можно провалидировать по ней все клиентские запросы. Мне нравится вешать подобные валидации на гит-хуки или гонять на CI. Это дает гарантию того, что в репозитории всегда будут валидные запросы.
Как я уже упоминала сегодня, на основе схемы генерируется очень удобная документация. Меньше вопросов к бекендам
Схему можно визуализировать, чтобы увидеть связи между вашими сущностями. Или просто повесить на стенку и любоваться. Это можно сделать например при помощи github.com/APIs-guru/grap…
Из схемы можно генерировать код. Причем очень разнообразный код. Самый лучший инструмент для этого graphql-code-generator.com
Можно генерировать статические типы (TS), хуки, типы для резолверов, тесты, интроспекцию
Можно взять схему и сгенерировать из нее сервер-заглушку. Вся генерация занимает примерно 10 строчек кода
Совсем не обязательно использовать одну огромную схему. Ее можно разделить между вашими сервисами.
А потом собрать все вместе при помощи специального гейтвея. Вот тут подробности apollographql.com/docs/federatio…
Этот подход настолько прикольный что, возможно, вдохновил создателей webpack сделать свои федерации :) webpack.js.org/concepts/modul…
Тред (Полина Гуртовая)
Суббота
Суббота – самое время поговорить я красивостях, а именно о картиночках.
Картиночки это огромная часть трафика на просторах интеренета. httparchive.org/reports/state-…. Тут, возможно, пропущен прекрасный формат – avif, о котором мы поговорим чуть попозже. Но это легко исправить.
Дело в том, что данные для httpArchive берутся из большого публичного дата-сета. Вот тут можно глянуть статью о том, как с ним работать github.com/HTTPArchive/ht…. Нужную инфу легко вытащить, использовав BigQuery. Вот так выглядит статистика по avif
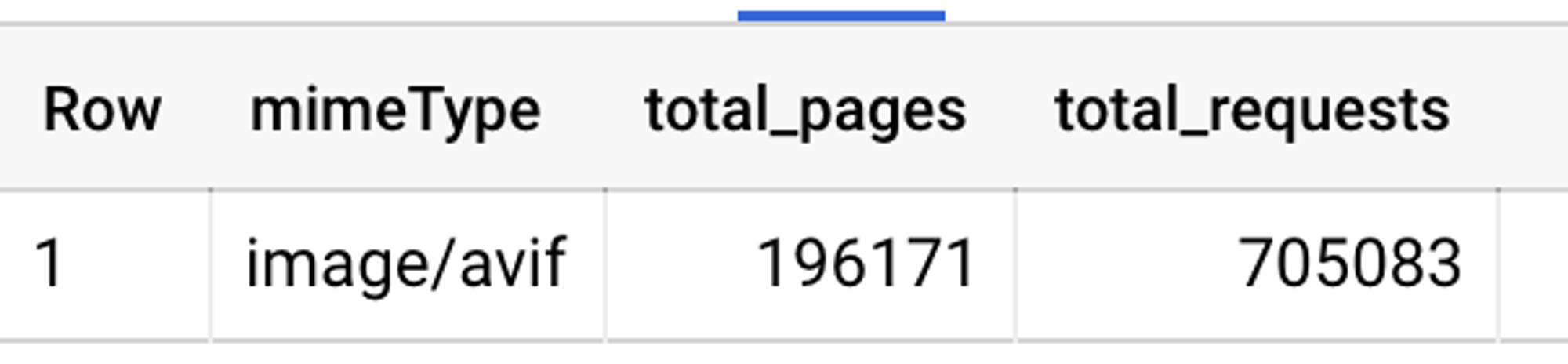
Гайдов, докладов и выступлений о том как правильно готовить картиночки огромное количество. (Я тоже делала несколько :) Но, не смотря на огромное количество доступной информации, я очень часто встречаюсь с мегабайтными монстрокартинками 😿
Самые распространенные причины огромных изображений:
пожать картинки просто забыли
изображения добавляются через какую-нибудь админку и добавляющие не понимают что нужна предварительная обработка.
Побеждать тяжелые изображения можно несколькими способами, которые лучше использовать в комплексе:
Быть внимательнее к своим асетам. Запускать lighthouse. Он найдет тяжелые картинки и поругается.
Добавить автоматическое сжатие при сборке
Сжимать картинки на лету
Решать проблему с размером изображений, которые мы не контролируем (те, что грузятся из админки) легче всего сжатием на лету.
В марсианах мы используем для этого свой инструмент – imgproxy imgproxy.net
Тред (Полина Гуртовая)
Продолжаем тему про изображения. В этом тредике суперкоротко о losseless форматах.
Loseless - сжатие без потерь. У такого сжатия есть определенный предел, меньше которого картинку сжать просто невозможно. Этот предел зависит от пикселей на картинке.
Форматы, которые умеют сжиматься без потерь - gif, png, webp и всякая экзотика типа JPEG 2000. На всякий случай: jpeg 100% quality сжимается с потерями :)
gif самый древний формат. Ему аж 33 года. В основе gif лежит алгоритм LZW, который сжимает 256-цветовую палитру. Каждый пиксель это индекс какого-нибудь цвета в палитре. При этом эта палитра индивидуальна для каждой гифки и может быть заасайнена на кусочек изображения
Прикольно то, что иногда относительно древний LZW алгоритм дает лучшие результаты чем тот что используется в PNG
PNG умеет в палитру, как и гифки, но может сжимать индивидуально каждый пискель (можно работать с разными типами пикселей, rgb/rgba/монохром). Можно задавать количество бит, которыми кодируется один пиксель или индекс в палитре
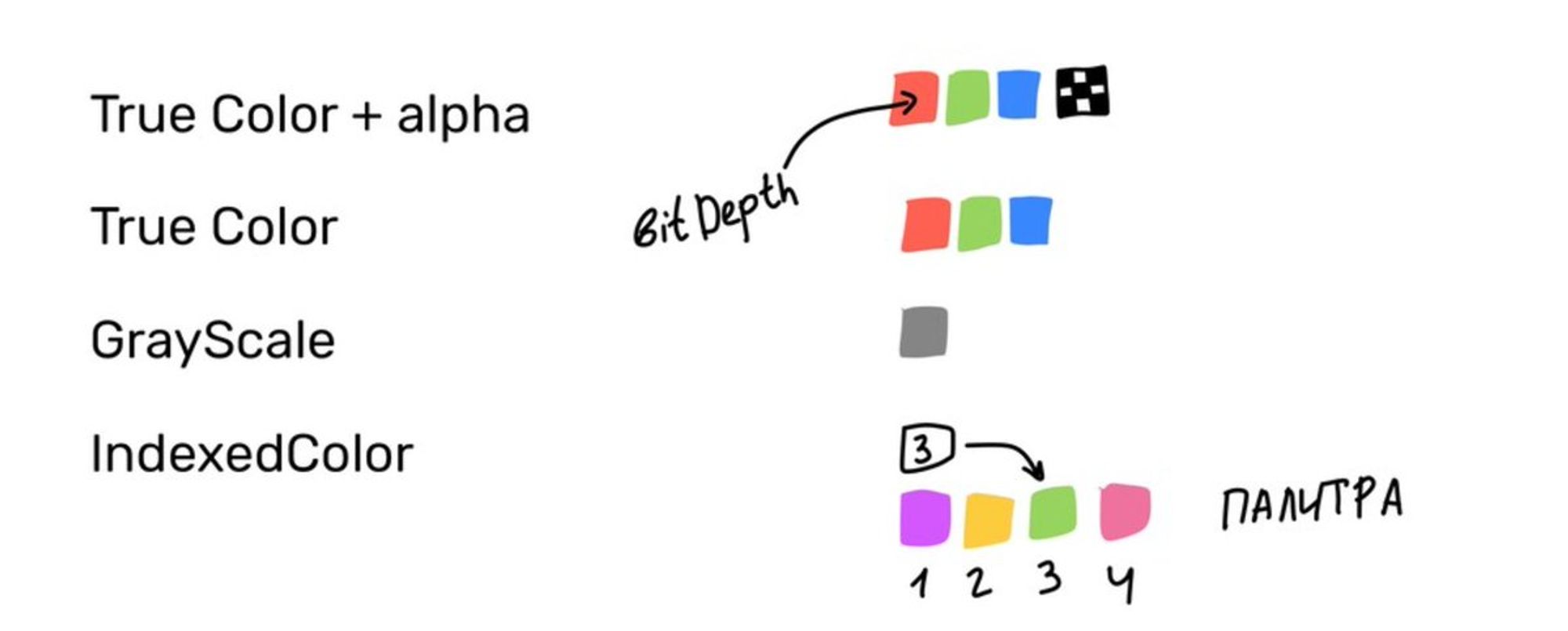
Еще PNG умеет добавлять фильтры к каждой строчке пикселей в изображении (predictive coding). Если правильно угадать фильтр, картинку можно сжать эффективнее. Для сжатия используется deflate
webp это на самом деле 2 формата. Эти форматы просто пакуются в одинаковые RIFF контейнеры. В этих контейнерах есть кусочек, называемый "chunk header". Для lossless webp это VP8L.
lossless webp активно использует predictive coding, умеет учитывать корреляцию между разными цветовыми каналами и хранить повторяющиеся кусочки изображений в виде ссылок. В большинстве случаев он дает несколько лучшее качество сжатия по сравнению с png.
Тред (Полина Гуртовая)
В статьях часто встречаются утверждения типа: "формат изображений X лучше Y" или "X сжимает изображения на 23% лучше". Я отношусь к таким утверждениям с недоверием.
Во-первых не существует объективной метрики, способной оценить качество изображения. Обычно для сравнения используется structure similarity/dissimilarity index. Этот параметр можно посчитать разными способами en.wikipedia.org/wiki/Structura…
Есть методы оценки визуального качества изображений на основе нейросеточек. Вот от Netflix например github.com/Netflix/vmaf
Во-вторых разные алгоритмы дают разное качество для разных типов изображений. Например, если к картинке добавить случайный шум, то она, скорее всего лучше будет сжиматься jpeg-ом а не lossy webp
Тред (Полина Гуртовая)
Воскресенье
А это тредик про сжатие картинок с потерями. Тут все намного интереснее и разнообразнее. У сжатия с потерями нет никакого физического предела зато можно задавать разные параметры, влияющие на качество конечного результата.
С потерями умеют сжиматься jpeg, webp и avif. Стоит также отметить, что все форматы без потерь тоже можно сжимать с потерями. Например, можно сконвертировать png-шку из режима true color в режим индексированной палитры и порезать количество цветов, скажем, до восьми.
Не буду вдаваться в подробности сжатия для каждого формата, но попробую показать "на пальцах" как могут вноситься потери для сжатия.
Для начала каждый канал изображения разбивается на кусочки. На какие – зависит от кодека (от формата). Получается что каждый кусочек это просто массив целых циферок.
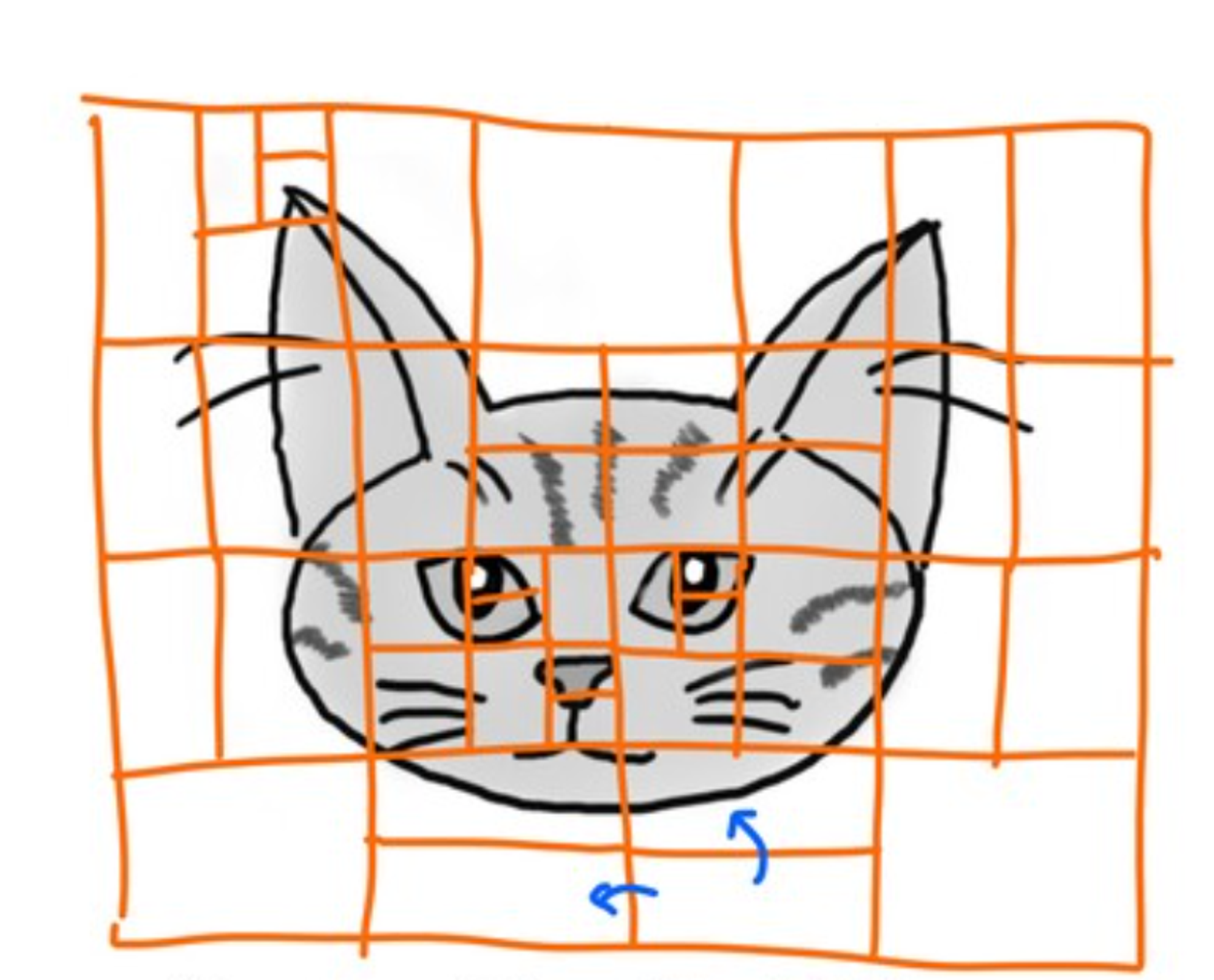
Каждый кусочек (вернее циферки его представляющие) преобразуются специальной математикой. Преобразований может быть несколько, но конечным как правило является разложение на частотные составляющие (DCT). Сейчас расскажу что это
Представим себе что у нас есть несколько картинок – базис. Накладывая базисные картинки друг на друга (допустим с разными прозрачностями) мы можем получить произвольный блок. Прозрачность – коэффициент нашего разложения. А каждая картинка это "частота".
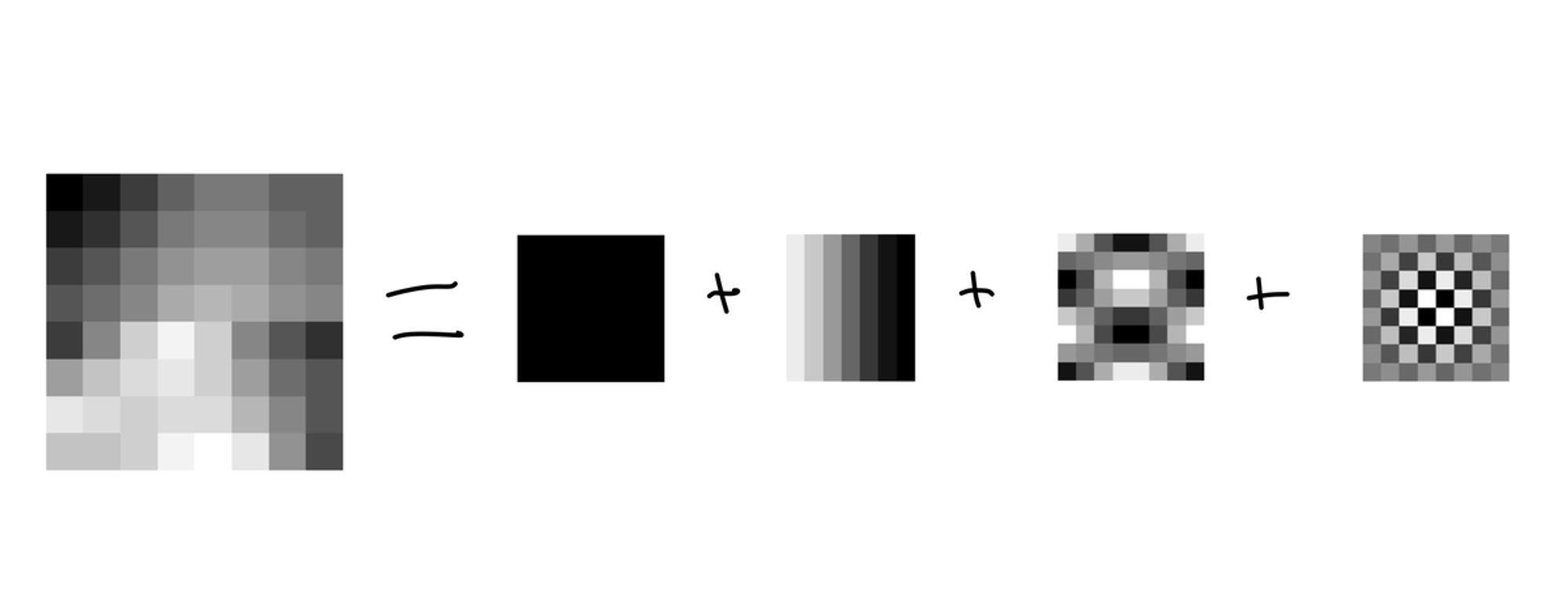
Потери это просто зануление коэффициентов для определенных частот.
Древние форматы (jpeg) пилились индивидуально. Более новые – lossy webp и avif это побочное следствие того как круто развились видеокодеки.
avif и lossy webp это просто фреймы видео, пережатого для avif - AV1 кодеком, а для webp - VP8 кодеком, уложенные в специальные контейнеры вместе с метаданными.
Все сказанное выше про частотное разложение актуально для avif и lossy webp. А в качестве промежуточной трансформации блока выступают предсказания.
Перед тем как раскладывать блок по частотам, мы заменяем его содержимое разностью между реальными значениями для пикселей и предсказанными. Предсказания делаются на основе соседних блоков.
Например, в качестве предсказания можно заполнить весь блок усредненным значением всех соседних с блоком пикселей.
Способы разбиения на блоки и набор режимов предсказаний отличаются для avif и webp. avif более фичастый. Например, он умеет эффективно хранить повторяющиеся кусочки изображений.
avif использует универсальный контейнер – HEIF. Это универсальный формат для хранения изображений. В нем, например, хранятся фоточки на айфонах, пережатые H.265 кодеком
На низких качествах остальные форматы начинают распадаться на блоки, а avif выглядит очень круто.

Правда, как показывает практика, на нормальных качествах AVIF особого выигрыша не дает.
Тред (Полина Гуртовая)
Воскресенье. Астрологи объявили день рандомного контента :) А пока я его придумываю, вот ссылочка на марсианский телеграм-канал, где мы делимся интересными на наш взгляд новостями и технологиями t.me/evilmartians
Тред про шеринг знаний внутри компании и вообще везде :)
Знания и навыки становятся намного полезнее если ими поделиться с другими. Это в первую очередь полезно для нас, ибо перед тем как поделиться нужно все систематизировать подробно изучить.
Мое мнение насчет "ой, ну это очевидная штука, зачем о ней говорить" – лучше говорить чем не говорить. То что пригодилось мне может пригодиться кому-то еще.
Как мы делимся знаниями внутри компании:
- У нас множество тематических каналов. Есть общие, типа frontend, backend, design есть посвященные определенной технологии: rust, docker, graphql. Я просто добавляю все что мне интересно в избранное.
Еще у нас есть канал где мы обсуждаем интересные события с участием или без участия марсиан.
- Мы пишем чекины где рассказываем об интересных технологиях/книжках/курсах или просто описываем хорошие решения, которые применили на наших проектах.
- У нас есть специальный временной слот где можно рассказать о чем-нибудь интересном, не обязательно техническом. В рамках этого слота мы обсуждали иммунитет, атомную энергетику, японский язык, как летают самолеты, книги, мастеркласс по переговорам и еще много всего.
В специальном канале можно написать что было бы интересно послушать и, возможно, кто-то из коллег, обладающих нужным знанием организует рассказ на интересующую тему.
- Есть еще один слот где можно пообщаться или просто включить зум и послушать разговоры фоном. Это мой самый любимый формат, откуда я утащила много полезного. Дебаг фигма-плагинов, советы по 3D печати, генетические алгоритмы для DL, блокчейн – это все там :)
- Есть еще два тематических слота. У дизайнеров – дизайн-час, у фронтов фронтенд-час. Мы предварительно собираем список тем и обсуждаем новую на каждом часе.
- Мы часто экспериментируем с форматами. Сейчас, например, появилась идея складывать куда-нибудь идеи небольших проектов чтобы поэкспериментировать с технологиями которые кажутся нам интересными. Возможно это будет работать лучше чем создание собственных пет проектов :)
В общем – получив прикольное знание лучше выпустить его на волю :) Форматов огромное количество: короткое сообщение, публичный gist, пост в блоге (dev.to, например)
Тред (Полина Гуртовая)
И последний тредик – рандомные оклофронтовые штуки :)
Используя WebGL, мы повстречаемся с програмками-шейдерами. Один из типов шейдеров - fragment shader. Это програмка которая выполняется для каждой! точки которую мы рисуем. И это окей, наши видеокарты ровно для этого и предназначены
Чтобы лениво грузить картинку ставим ей атрибут loading=lazy. В хроме это гарантирует только то, что картинка на расстоянии X от вьюпорта будет грузиться лениво (т.е то что за экраном тоже загрузится). Это расстояние зависит от типа текущего интернет-соединения (4G/3G/2G)
JS-парсер V8 очень ленивый. Он не будет парсить тело функции если вы ее не вызываете.
Советы по улучшению продуктивности:
Добавить единорогов в консоль
Поставить себе какой-нибудь трекер (типа wakatime)
Поставить в трекере цель "писать код меньше чем X часов". X выбирается индивидуально. У меня X=7
Когда пишешь плагинчик для webpack, есть возможность запустить еще один webpack внутри webpack 👻 и передать ему весь родительский контекст. Это бывает удобно если надо динамически собрать какой-нибудь дополнительный асет.
webpack.js.org/api/compilatio…
Внутрь SVG можно закинуть JS-строку и она будет выполняться
Multistage билды в докере очень удобная штука. Можно на первом шаге установить все собирающее, собрать, а на втором просто скопировать результат в новый образ
WebAssembly или Wasm. Не WASM
Поражаюсь что изучая Rust можно найти gitbook на каждый топик. Вот, например, про rust-компилятор
rustc-dev-guide.rust-lang.org/overview.html
В macOS есть программка - Color Sync Utility. Там можно посмотреть на 3D визуализации цветовых пространств
Тред (Полина Гуртовая)
Осталось еще много всего, чем хочется поделиться, но нужно себя останавливать :)
Спасибо всем большое-прибольшое 🤗
Было очень здорово вести jsunderhood на этой неделе.Если у вас есть какие-нибудь вопросы или фидбек (хороший или негативный) то делитесь, не стесняйтесь :)
Меня можно найти вот здесь @pgurtovaya или в телеграмчике t.me/polina_gurtova…