Архив недели @ovrweb
Понедельник
Доброго времени суток, с вами @ovrweb!
Я еще тот любитель твиттера, но постараюсь быть активным и поделиться знаниями ;)
Поговорим про:
- React-Native
- Идеальный backend, идеальные языки
- Почему я перестал доверять микросервисам
- Ошибки менеджмента
- JavaScript
Начнем мы неделю с крутых советов по поводу CI, потому что больше всего люблю заниматься автоматизацией.
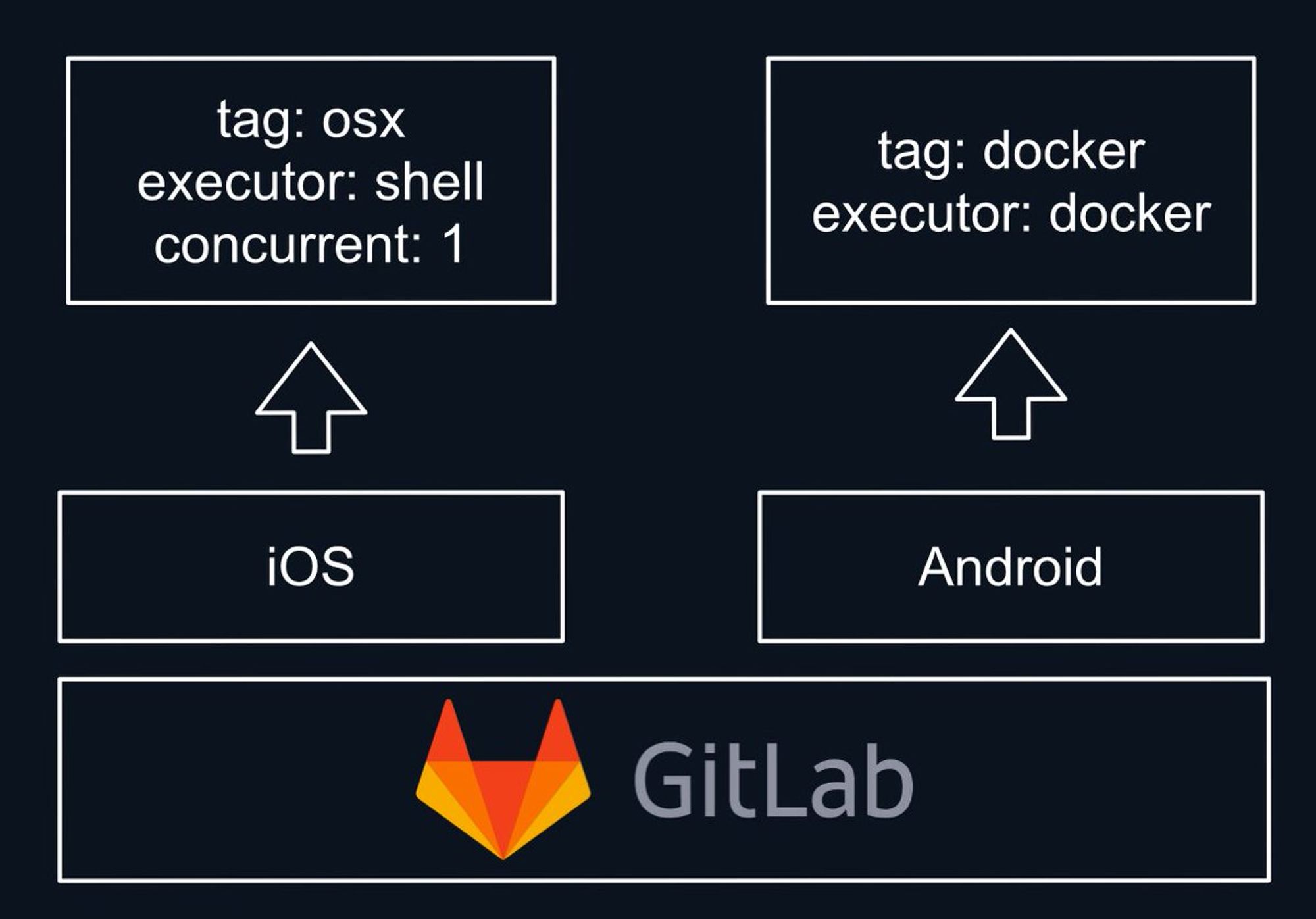
Будем рассматривать все на примере @gitlab CI.
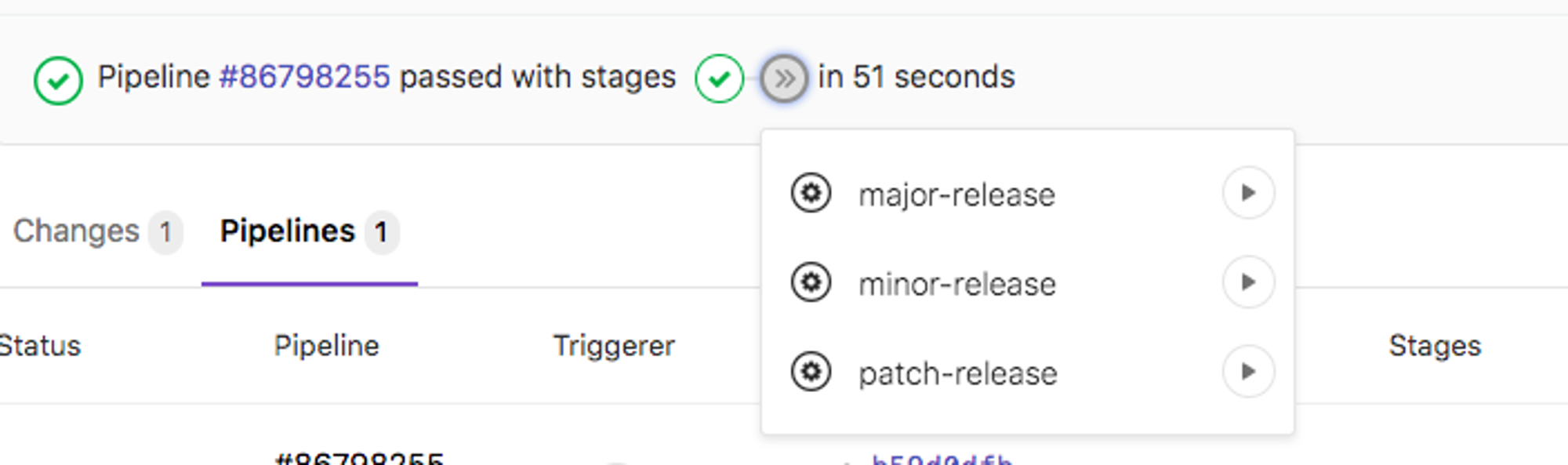
В своих проектах я использую такой трюк, как авто релиз новых версий используя CI.
@jsunderhood @gitlab Ещё можно использовать тэг в качестве версии: билд триггерится тэгом, тэг проставляется в package.json во время билда, сам тэг вместе с release notes генетически автоматически на основе коммитов утилитой типа github.com/go-semantic-re…
Мне больше нравиться "стандартный" flow:
- Ветка в master (можно сделать релиз кнопочкой)
- CI делает push с изменением в package.json (отдельный коммит) и пушит новый тэг
- По тэгу уже идет pipeline, где я уже делаю релиз куда нужно :) twitter.com/MeFCorvi/statu…
@jsunderhood @ovrweb Даёшь неделю PHP в @jsunderhood!
До PHP дойдем в пятницу, что бы не было желание дик пики запостись. twitter.com/5minphp/status…
Используйте YAML anchors
docs.gitlab.com/ee/ci/yaml/#an…
Это не только сокращает конфиг, но и делает его более читабельным.
Тут все крайне просто ;)
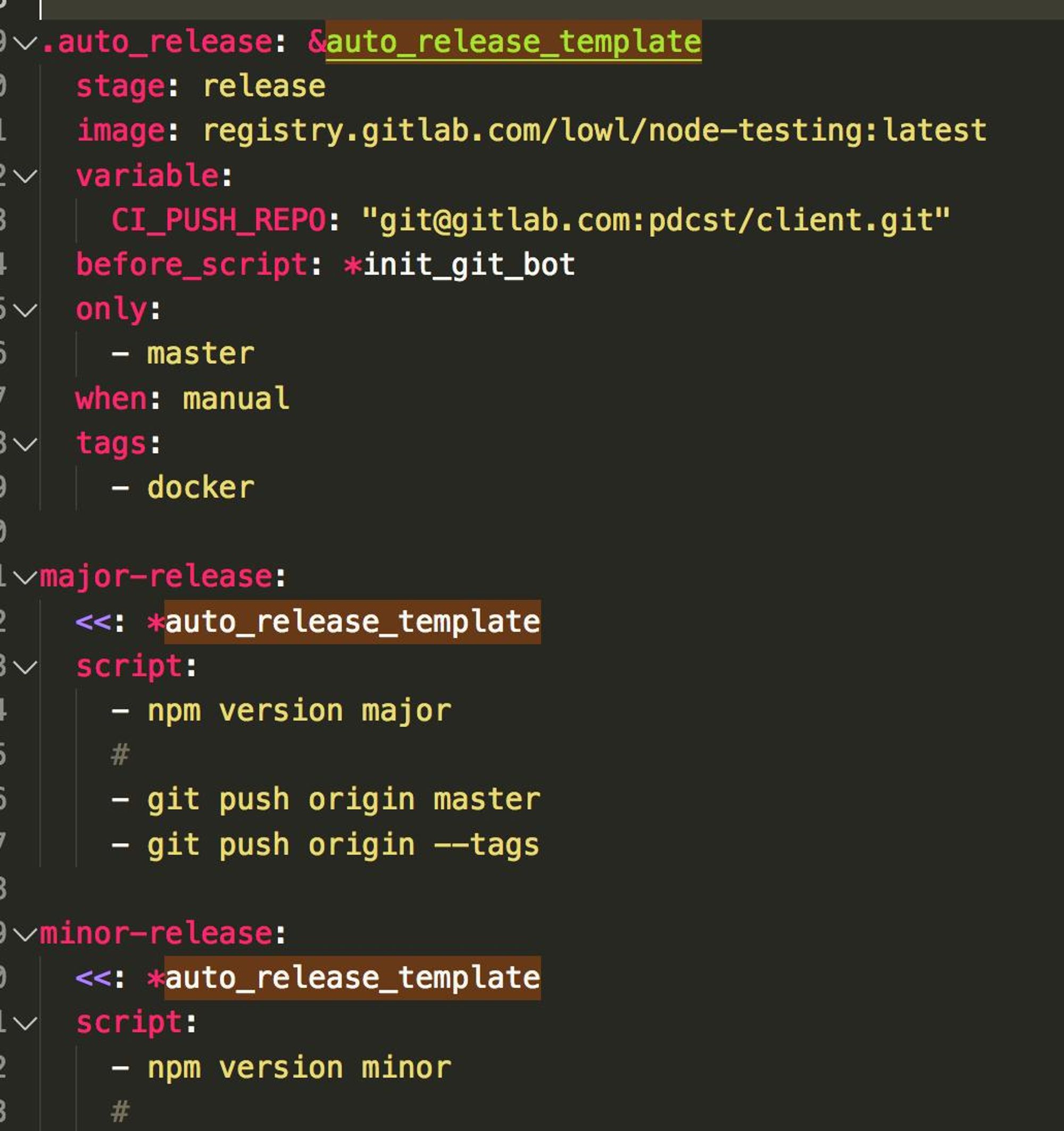
Includes
docs.gitlab.com/ee/ci/yaml/#in…
Если у вас много проектов, необходимо использовать шаблоны.
К примеру на 25 микросервисов, где каждый сервис это отдельный репозиторий, без шаблонов не обойтись!
Создайте отдельный репозиторий внутри организации и положите туда шаблоны.
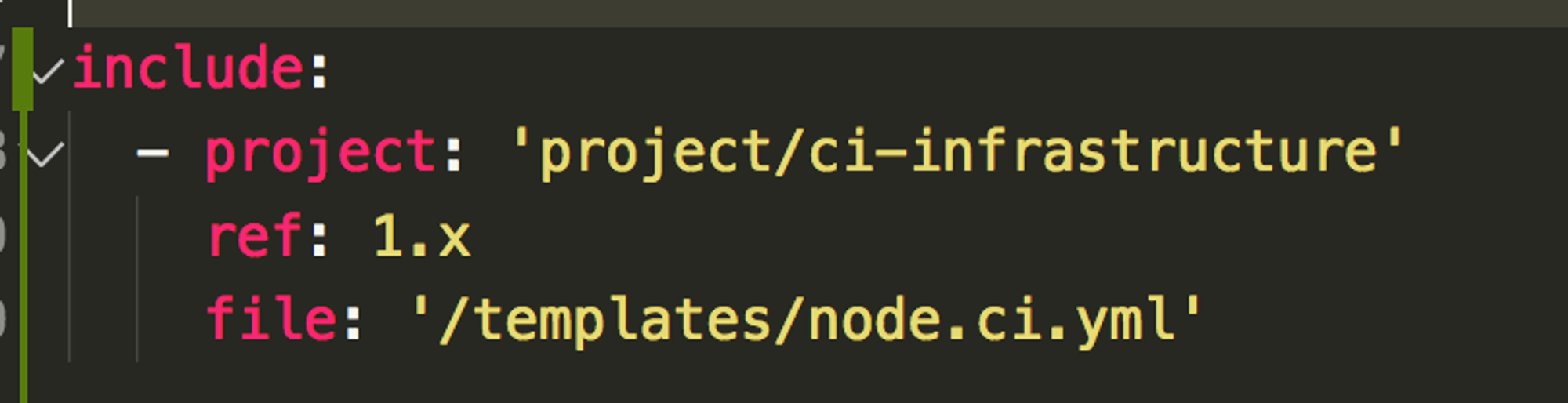
Но не забывайте, что шаблоны нужно как-то версионировать.
К примеру, создайте ветку 1.x, куда положите устоявшиеся шаблоны, которые будете только исправлять, а не менять кардинально.
Это нужно, чтобы мажорная правка не сломала все репозитории, которые зависят от шаблона.
@jsunderhood Блин блин. А может кто-то хочет поменторить классического "войтивайти" (фронт, js, react, vue)? Курсы от широко известных в узких кругах ninja - в процессе. Задачки на hackerrank решаю. )
Есть кто?) twitter.com/stepan25626128…
Не бойтесь готовить свои docker images для тестирования/разработки.
К примеру вам нужно ocaml libelf-dev для стат анализатора flow.
Не нужно делать apt-get install внутри секции scripts, просто укажите тестовый image для этого pipeline.
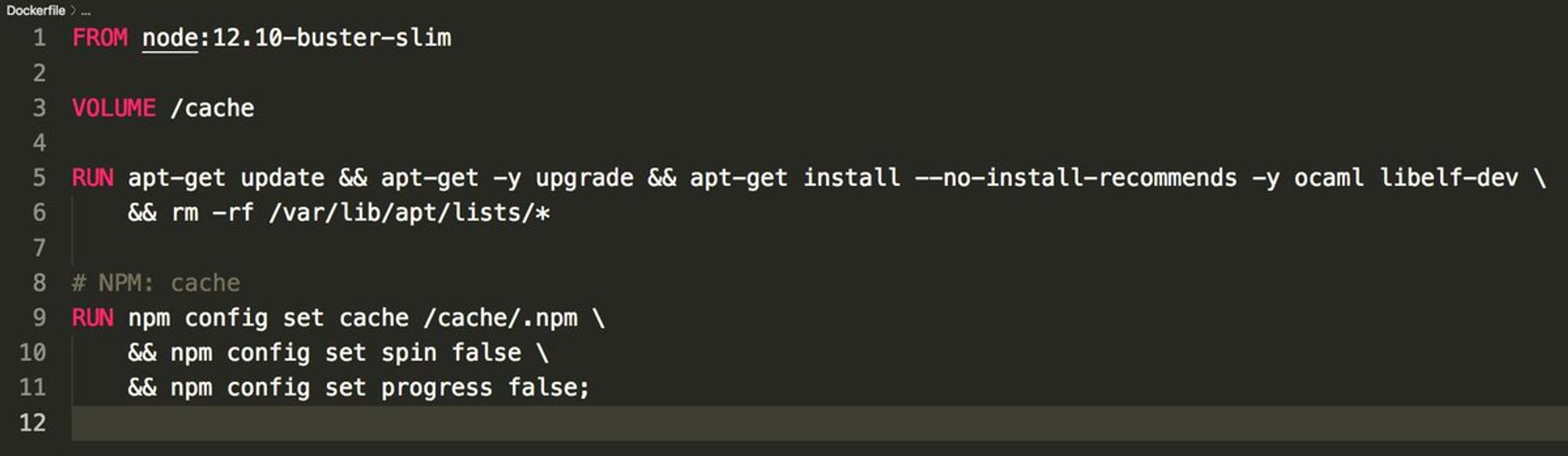
Это даст вам:
Экономию времени, так как не нужно будет ждать пока установятся необходимые пакеты на CI
Вы гарантируете что у вас будет одна версия библиотек/программ между запусками CI, и коллегами
Желательно image делать двух типов: dev и latest (production).
Пример, делаем 2 image:
FROM node:12.5.1 -> dckr/node:latest
FROM dckr/node:latest -> dckr/node:dev
Тем самым, используем :dev тэг для CI, а :latest для контейнеров в проде.
Для таких вещей, советую делать отдельную группу в gitlab внутри организации, к примеру dckr или же docker.
Внутри нее репозитории для ваших нужд,
node
php
А так как docker registry встроен в gitlab, у вас к каждому репозиторию будет свой image.
Тред (@ovrweb)
Я тоже много раз думал бросить @PostCSS из-за критиканства (неконструктивной критики, у которой не понятна цель). Критиканство — проблема сообщества. Если видите её, поддержите автора в обсуждении и укажите критикующему на бессмысленность такой критики. twitter.com/logach/status/…
Самое страшное – это начинать что-то делать зная, что придут и напишут нелестные отзывы. Делаю сейчас свой первый проект не про код, и постоянная мысль в голове, что после релиза читать комментарии будет очень больно. Из-за этого делать не хочется. twitter.com/andrey_sitnik/…
Все что можно автоматизировать, автоматизируй.
К примеру: У меня в backend я использую Swagger (нынешний OpenAPI). Из swagger можно сгенерировать client для любого языка программирования.
Я делаю схему,
api -> swagger -> client
Смотри скриншоты :)
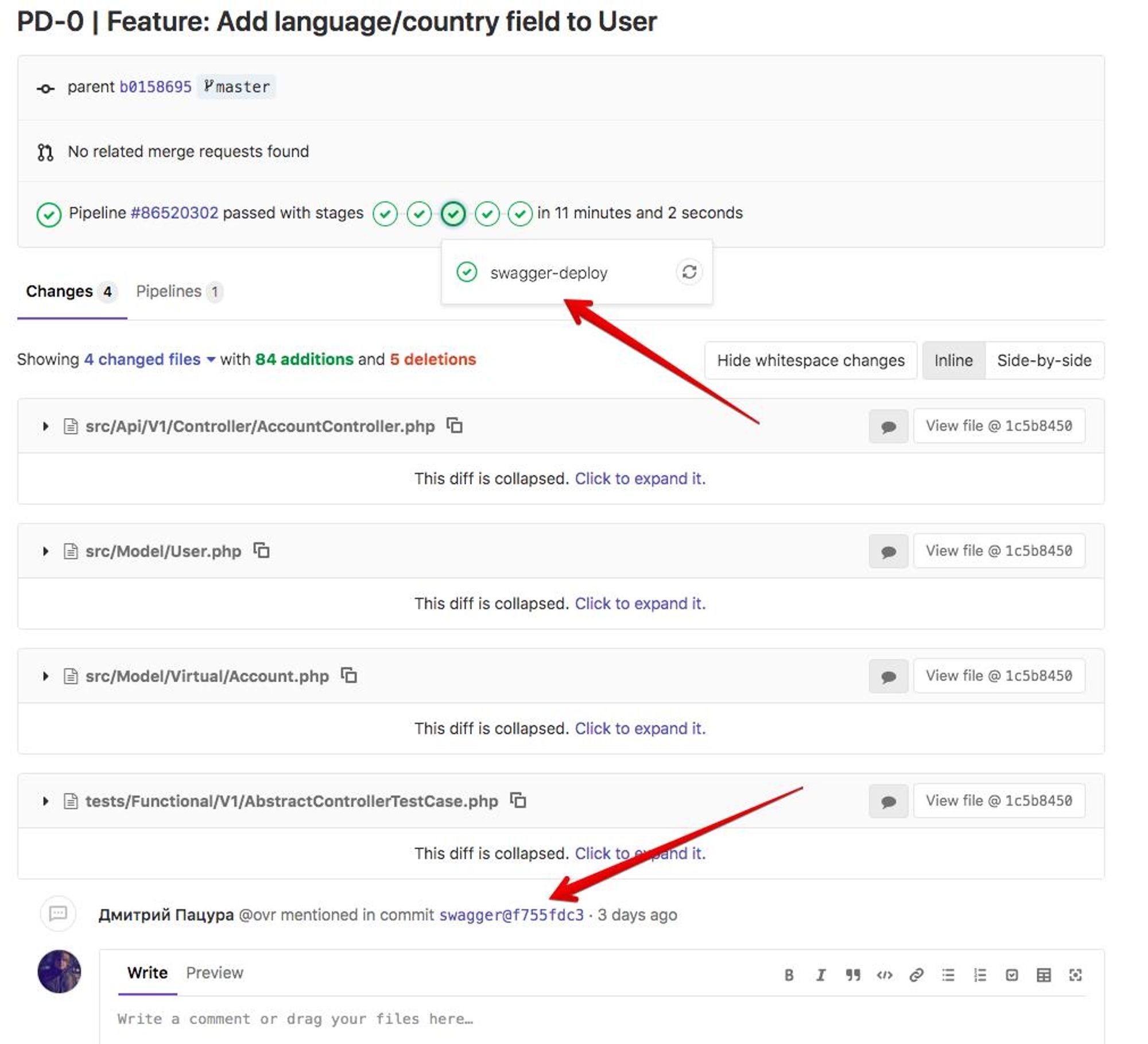
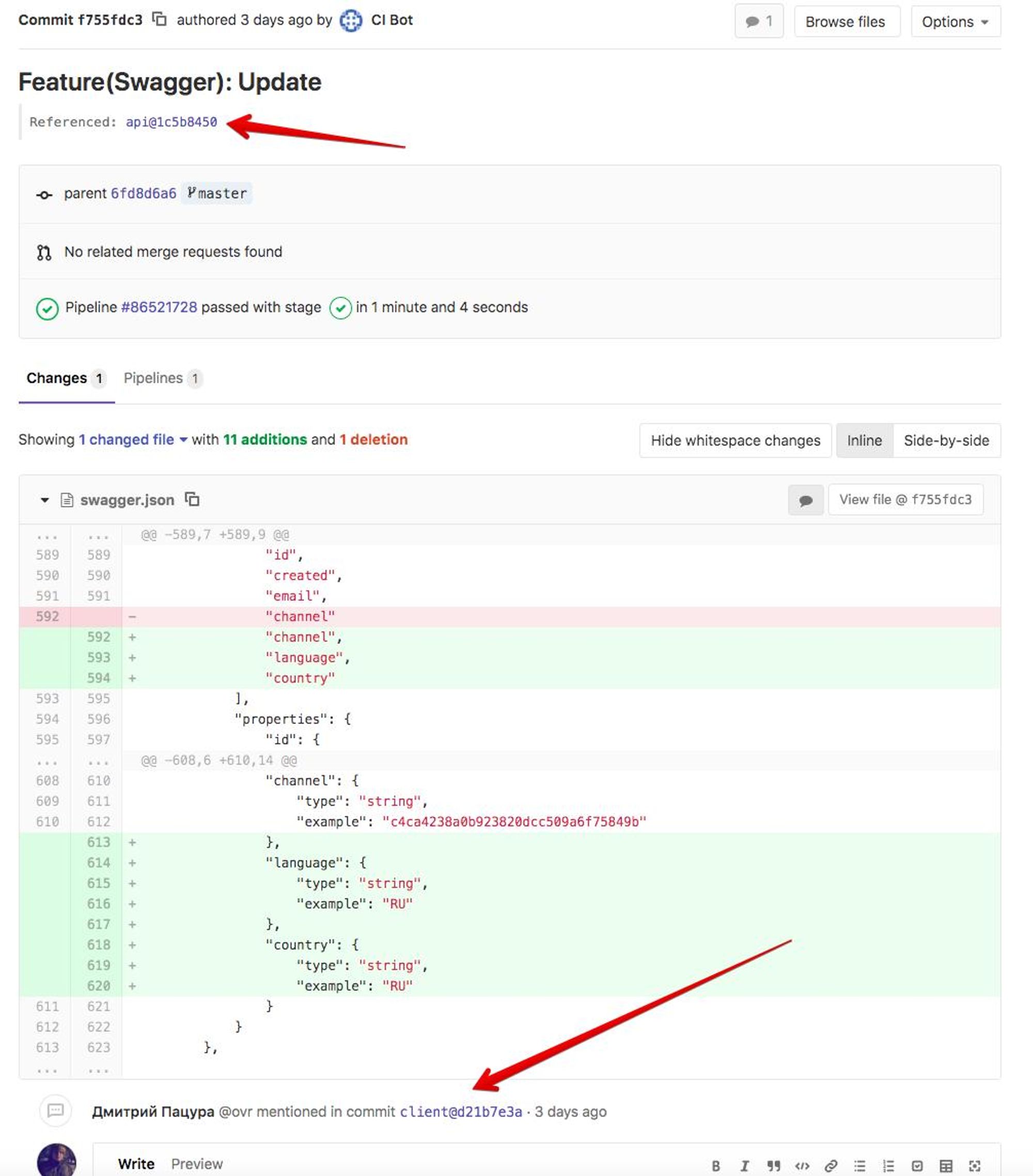
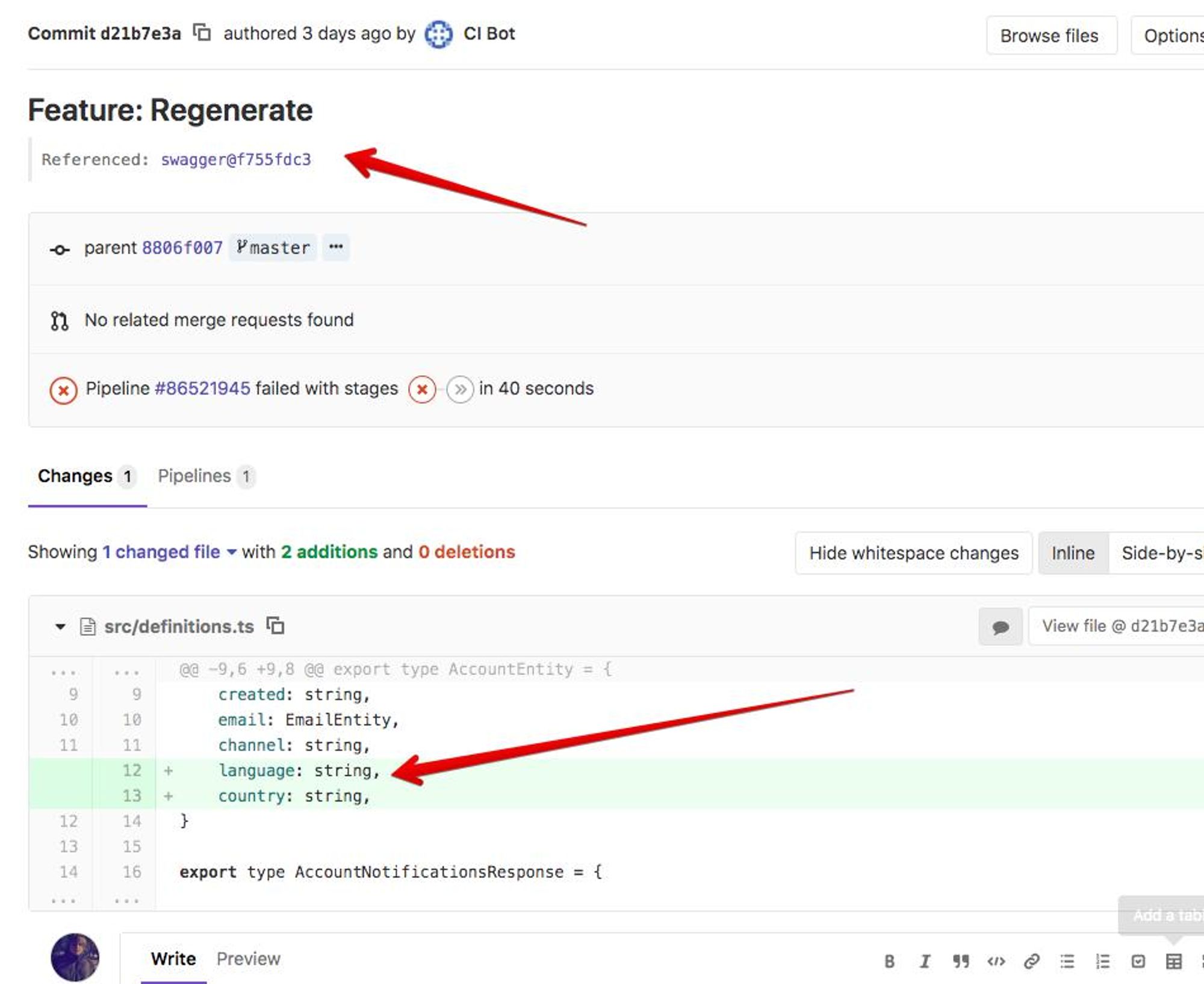
Раз в какое-то время захожу в client repository и жму кнопку релиза новой версии. В итоге, я трачу на поддержку клиента минимум времени. Инвестировав N времени на CI, я сэкономлю времени > N.
Также я доставляю мобильное приложение, с помощью fastlane
fastlane.tools
Экономьте время ваших runners.
7.1 Прочитайте про interruptible, чтобы не тратить время на дубли при постоянном обновлении веток (MR/PR)
docs.gitlab.com/ee/ci/yaml/#in…
7.2 Не делайте "миллион" pipelines внутри одного stage. Возможно начальный запуск таких N pipelines будет стоить дороже чем если бы это был 1 pipeline.
Используйте tmpfs на ваших gitlab-runners для ускорения (если понимаете):
docs.gitlab.com/runner/executo…
Если вы запускаете функциональные тесты для вашего сервиса с первоначальной загрузкой данных. Благодаря tmpfs, вам получиться ускорить первоначальную загрузку данных в БД.
@jsunderhood Ищу ментора во frontend, JavaScript, Vue, React. Хочу сделать первый комит в open source, но не знаю с чего начать 🤷♂️ Если есть такой человек, отзовись 🙏
Есть менторы?) twitter.com/malafeev_en/st…
Вторник
Используйте менеджеры версия для систем на CI где нет docker:
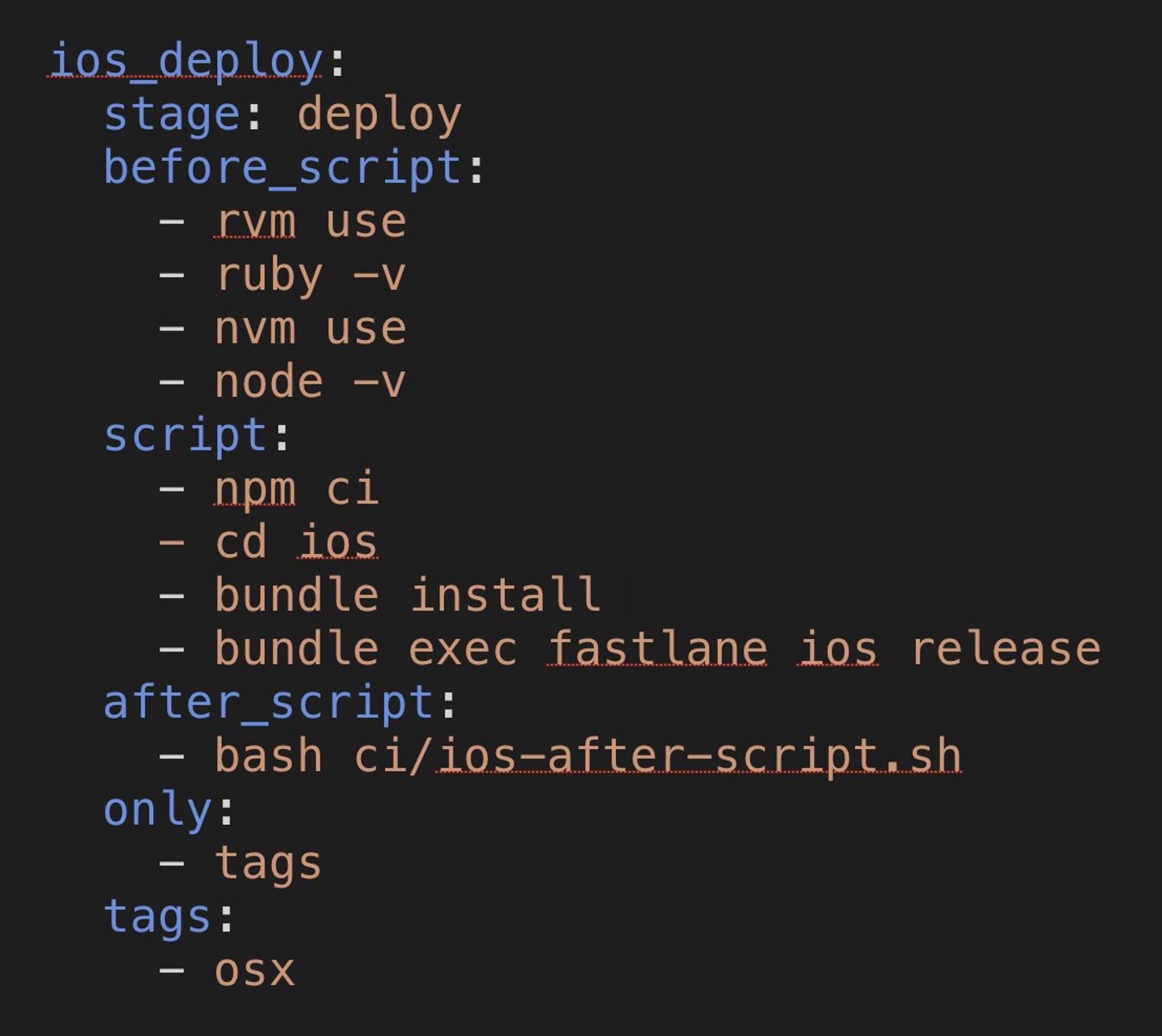
К примеру сборка мобильного React-Native приложения на OSX.
Обязательно:
- rvm.io
- github.com/nvm-sh/nvm
А в проект:
- .nvmrc
- .ruby-version
В pipeline:
nvm use
rvm use
Fastlane также ставим используя bundler
bundle install
bundle exec fastlane -v
bundle exec fastlane ios beta
Старайтесь не ставить софт глобально, ибо в будущем сложнее будет перевести мобильное приложение на новую версию nodejs/rvm/fastlane.
Иногда бывает один OSX CI worker на большое кол-во проектов, и если вы поставите что-то глобально, а в будущем попытаетесь обновить, то можете сломать всем CI за раз.
Если вы один разработчик и часто делаете релизы, могу посоветовать поставить CI worker у себя на компьютере внутри виртуализации (если нет возможности). К примеру я использую @ParallelsCares и с мощным компьютером даже не замечаю как у меня в фоне внутри виртуалки идет build.
Тред (@ovrweb)
Трюк с кешированием через прокидывание volumes внутри gitlab-runner с типом docker:
Ограничиваем limit = 1, ибо параллельные запуски с shared volumn могут давать сбоиlimit = 1
volumes = ["/cache/docker-1:/cache"]
для каждого runner своя папка
Далее меняем уже папку для кеширования
RUN npm config set cache /cache/.npm
Внимания! Данный техника не является легко масштабируемой (нужно постоянно стругать runners), но если знать и понимать ограничения можно неплохой такой механизм кеширования получить.
Сегодня вечером обсудим: Почему я перестал доверять/верить микросервисам.
Про микросервисы у меня был отдельный большой доклад после более года участия в разработке большого проекта.
youtube.com/watch?time_con…
Пока его можно глянуть, а вечером пройдусь по тезисам из доклада.
Начнем с плюсов и минусов:
Когда говорят про микросервисы подразумевают:
- Независимую разработку / легкость масштабирования команд
- Технологическую гетерогенность (технологии под сервис)
- Независимый деплой (выпустил patch релиз, шли его отдельно в прод)
- Переиспользуемость (написав один раз сервис нотификаций, используй в каждом проекте его)
- Продуктовая составляющая (можно продать клиентам микросервисы как разные части проекта)
- Изолированность (может быть решающим звеном для прохождения различных регуляторных compliance-ов)
Но даже эти плюсы не так однозначны, допустим про независимый деплой:
Представьте что ваш проект состоит из 10 микросервисов, чтобы сделать релиз, вам нужно собрать целый поезд из версий который помчится на production.
Такой поезд должен быть хорошо оттестирован.
Про технологическую гетерогенность:
Иногда это реально круто работает, но зачастую у вас в штате команда людей с определённым стэком и давать ей писать на чем-то другом не имеет смысла.
Про переиспользуемость:
Каждый проект имеет свою инфраструктуру, иногда инфраструктуры между проектами могут не совпадать и все равно придётся допиливать, но это в любом случаи лучше чем писать каждый раз один и тот же сервис :)
Так как микросервисная архитектура это распределенная система, то мы получаем минусы распределенных систем.
На уровне БД
Когда каждый сервис имеет свою БД, и вы ходите между микросервисами используя RPC, то быть транзакционными не представляется возможным.
Начинается изобретения своих механизмов, так называемых "state machine"/"saga" которые умеют проводить распределенные операции по сервисам и самое главное делать возврат этих действий для отмены (для консистентности бд).
youtube.com/watch?v=OOP_4k…
youtube.com/watch?v=6HvSpq…
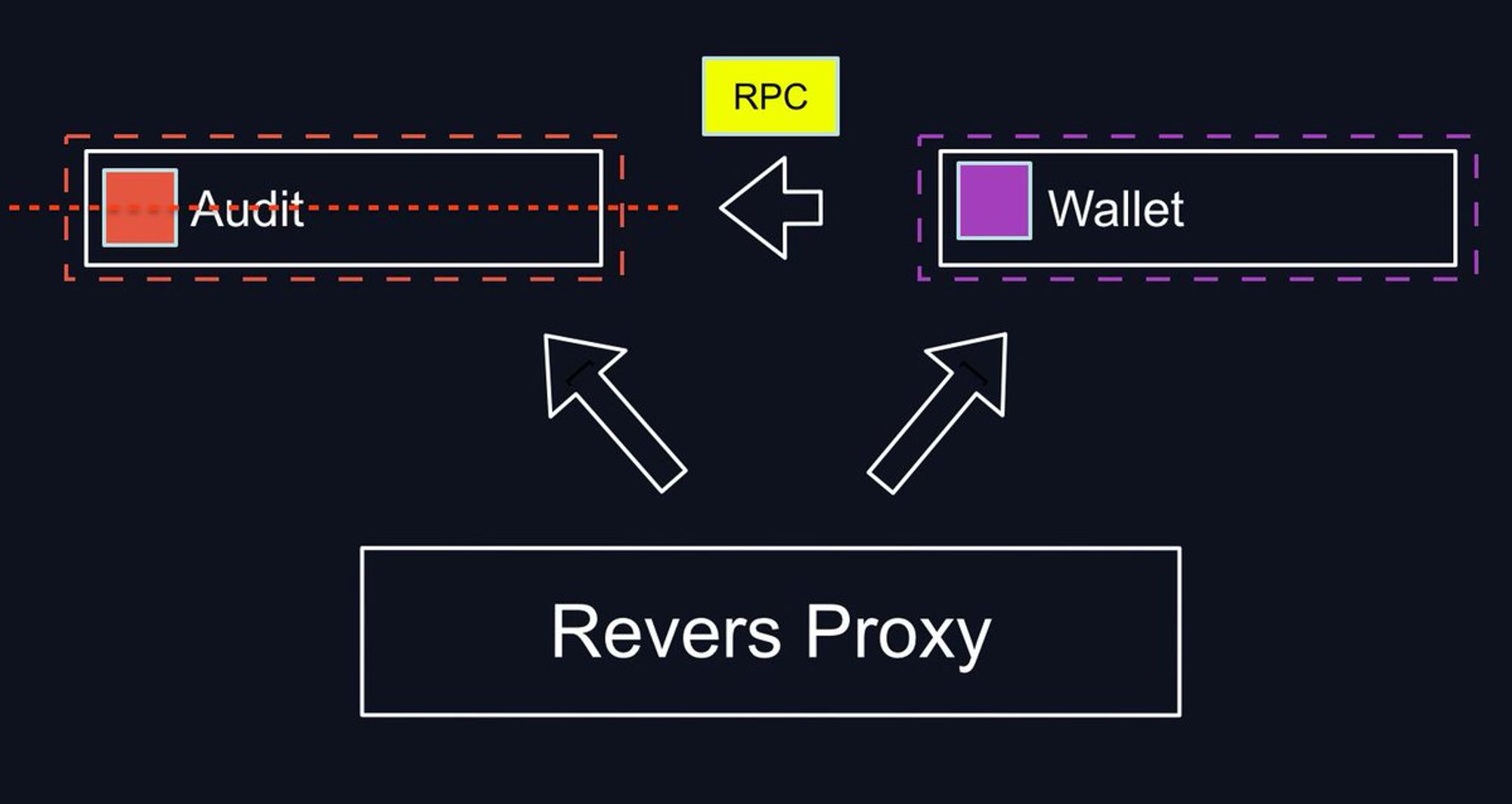
Я занимался разработкой центральной системы (кошелька) внутри платежки, и для проведения транзакций мне нужно было сходить во все места. Теоретически каждый RPC может застрять, значит нужно его иметь возможность повторить или же откатить.
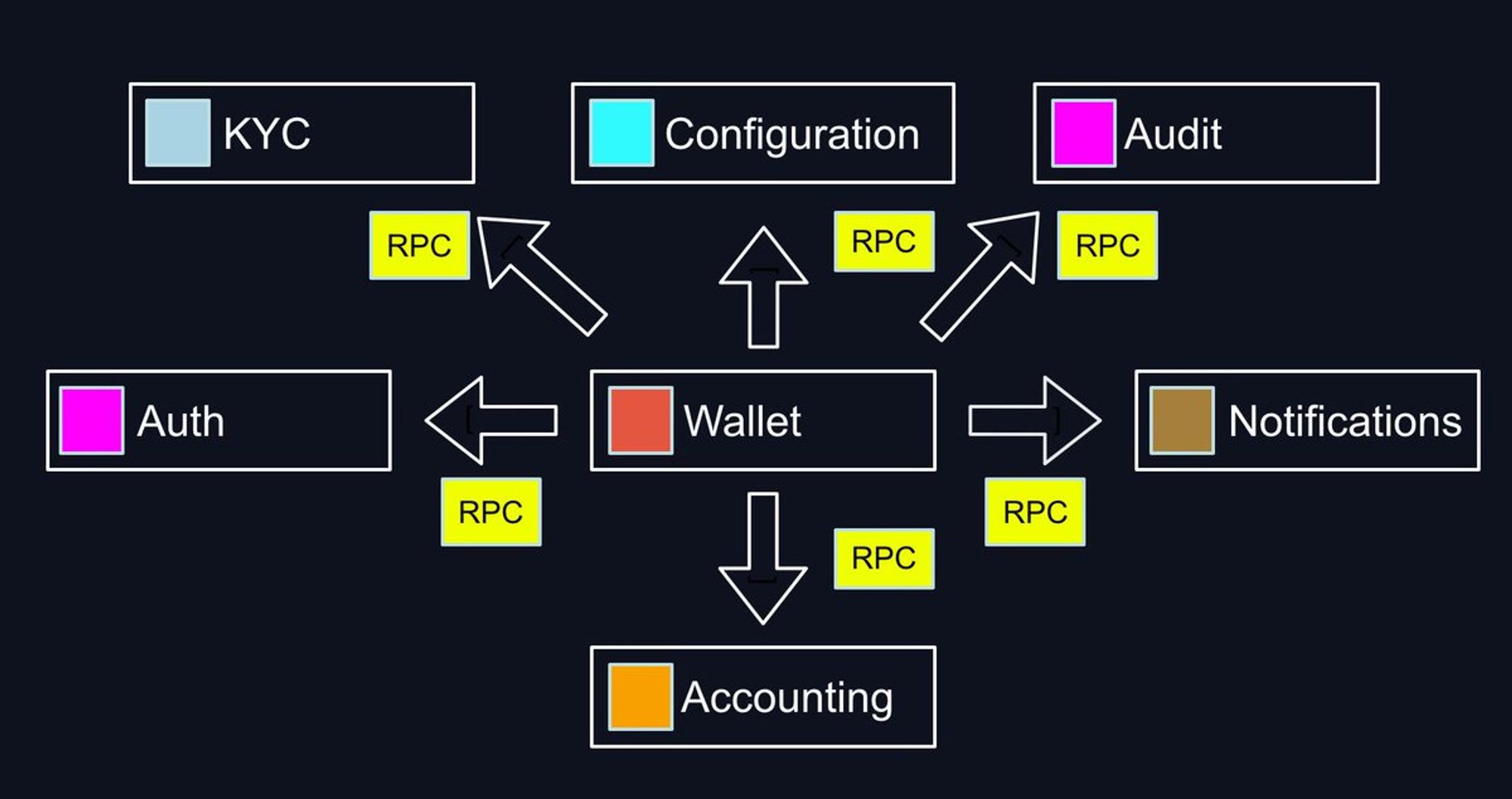
И сам сервис может упасть, а другой сервис может выполнить действий и не успеть ответить за timeout. Все эти вопросы нужно как-то решать и изобретать космический корабль.
Иногда нужно сделать фильтр по данным в таблице, а поле для запроса находиться в другом микросервисе. Что делать? Денормализовывать! В итоге получаем миграции которые уже работают на уровне кода, а не простые запросы.
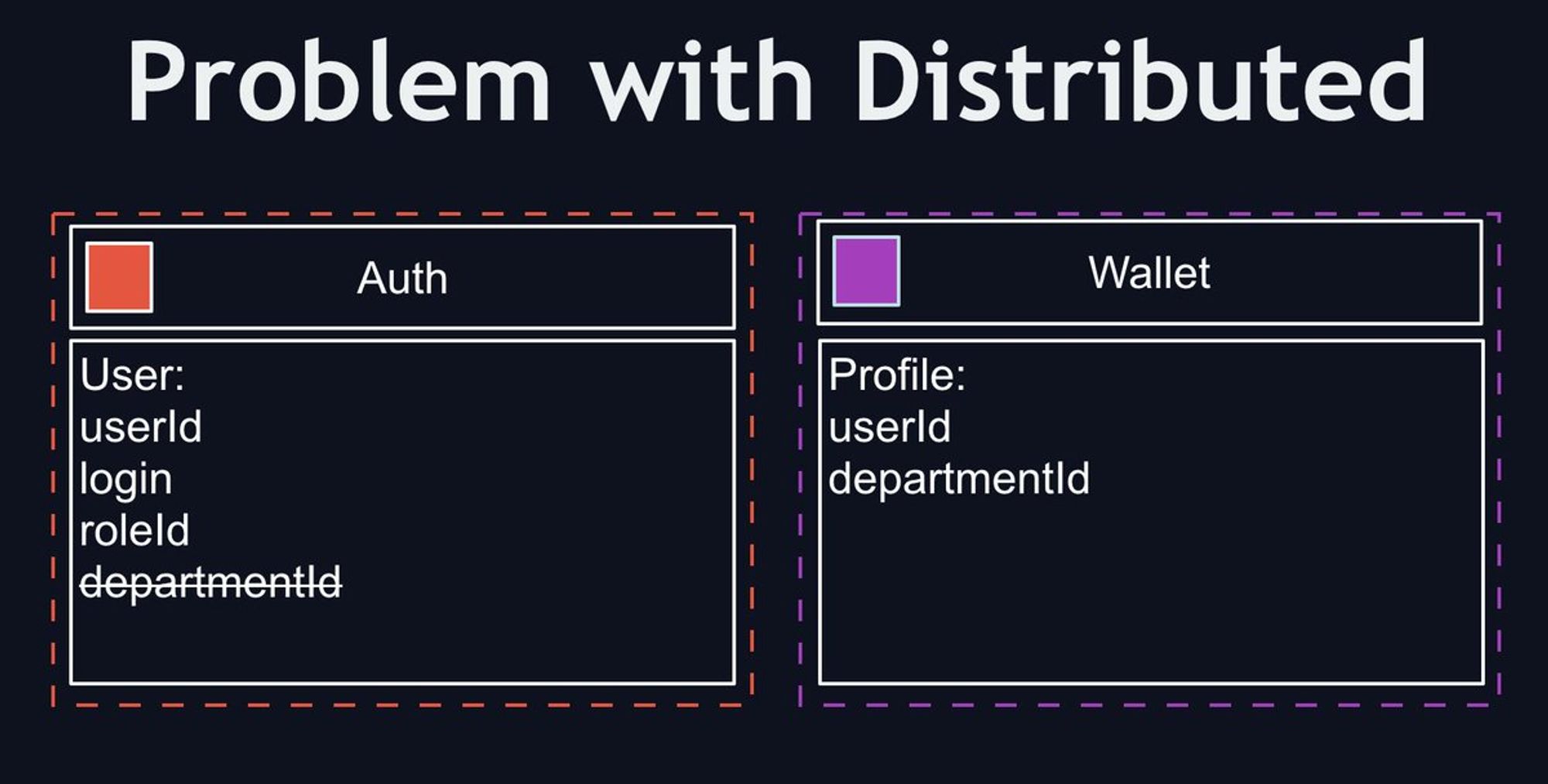

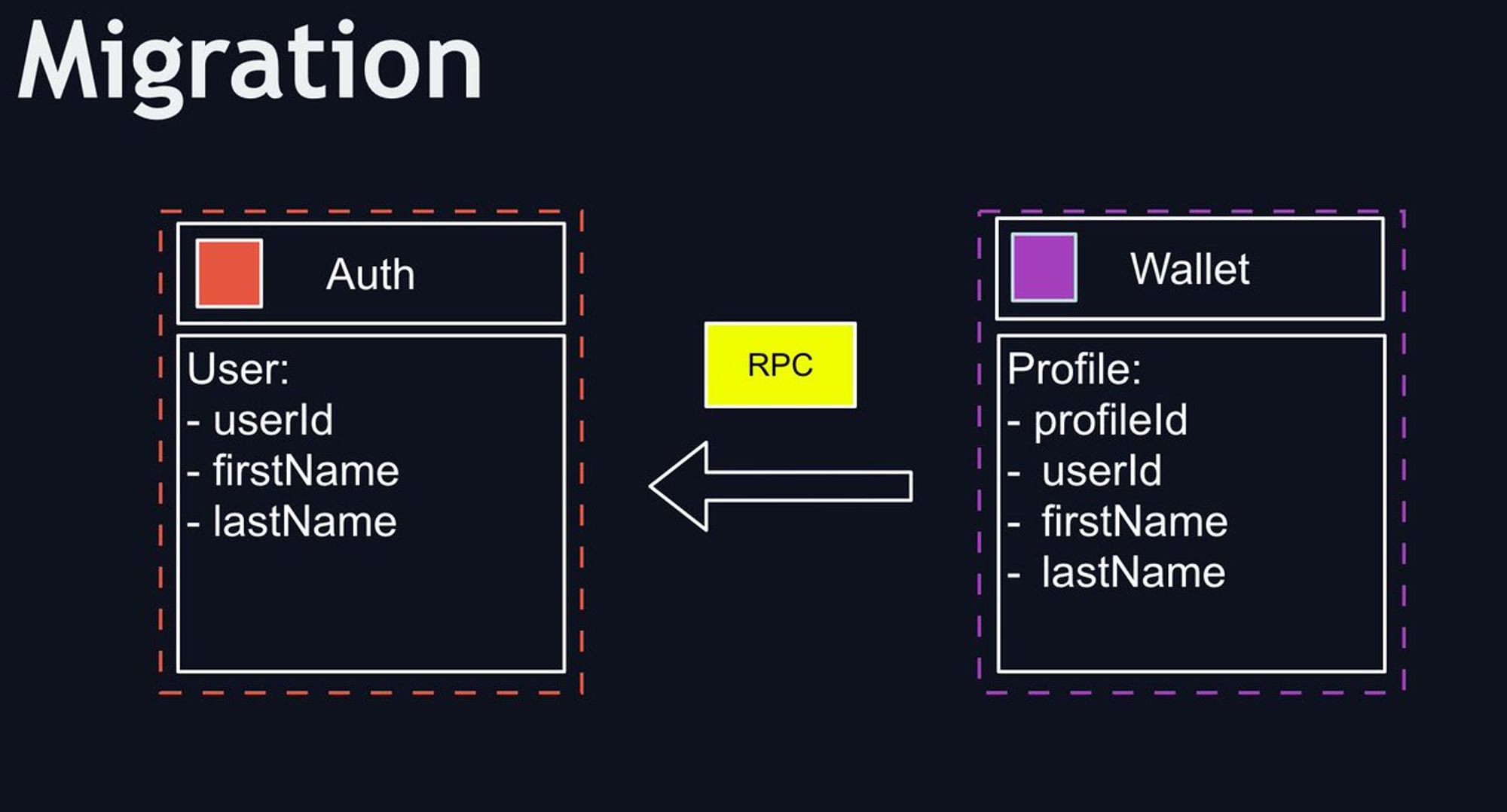
А миграции могут тоже упасть, значит механизм миграций должен уметь восстанавливаться или пропускать данные. А потом к вам придут с задачами про аналитику или про статику, ну вы поняли )))
На уровне разработки
Если у вас комплексная система, где реально много RPC, разрабатывать без тестов не возможно.
Unit/mocks RPC не самая лучшая идея, уже больно мало покрывают реально мира. В итоге для функциональных тестов нужно держать актуальную инфраструктуру на локале
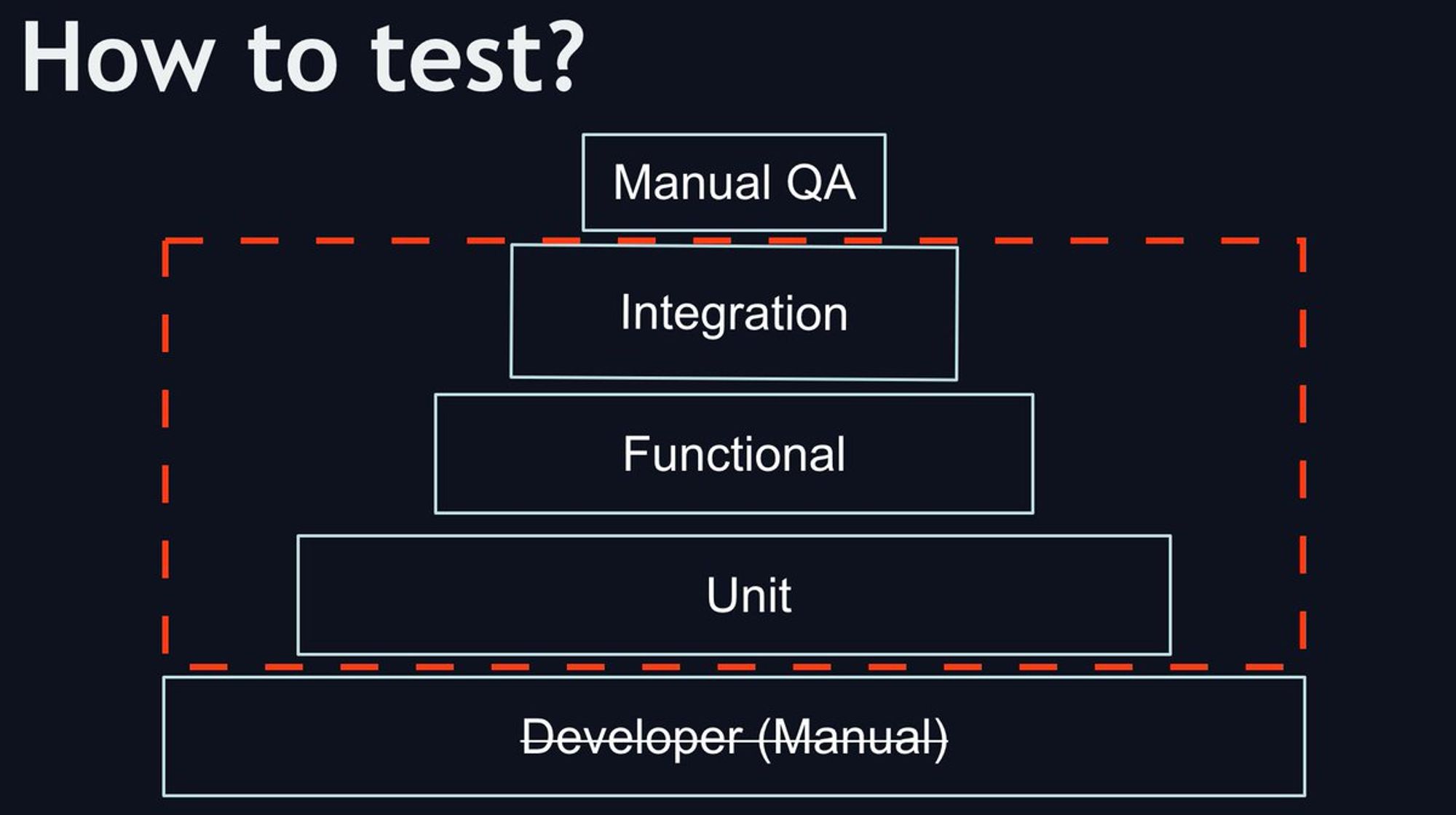
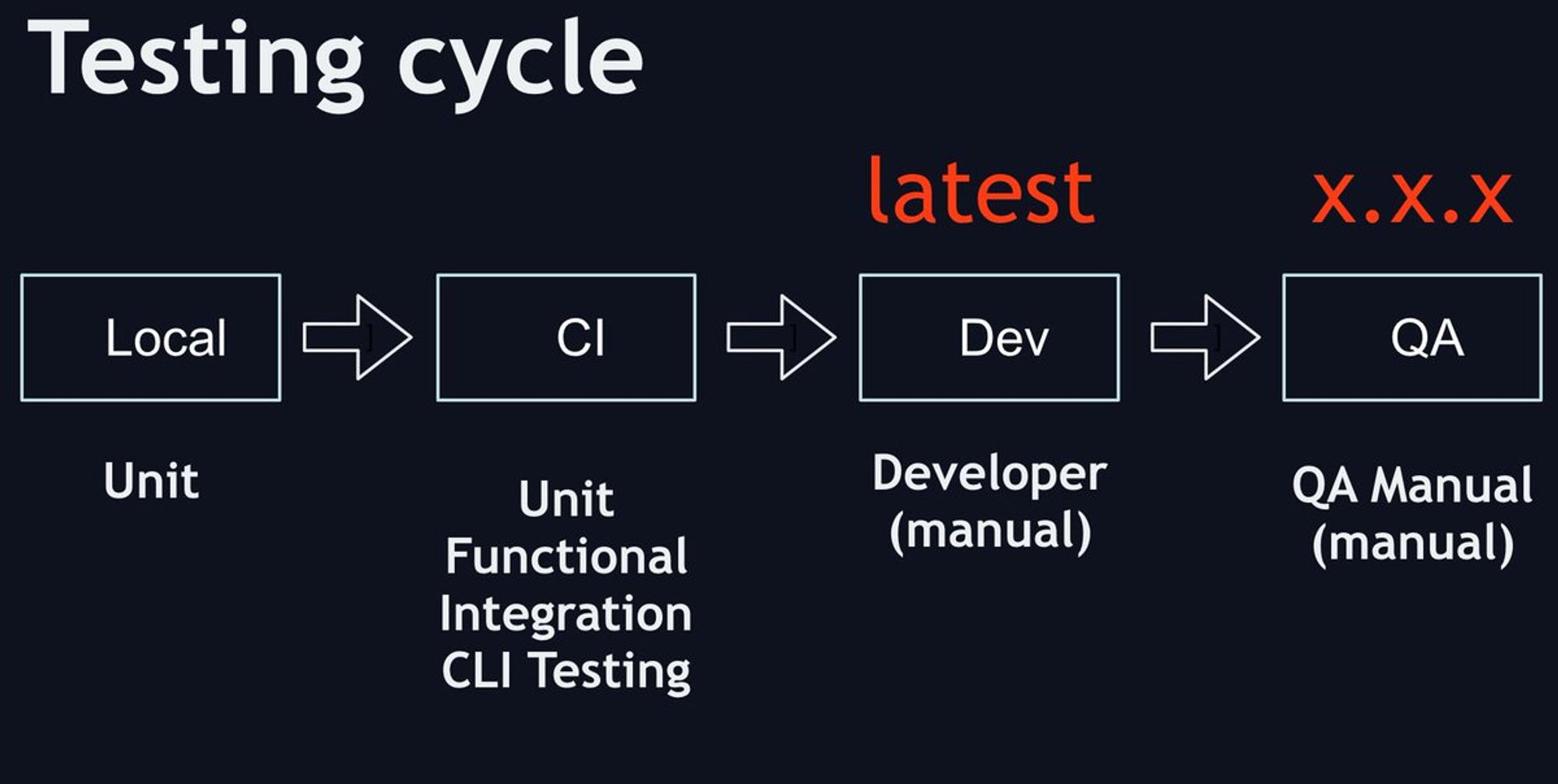
В один момент я просто перестал тестировать руками на локальной машине, начал делал unit тесты, а руками уже тестировал только на dev env. Не возможно держать все микросервисы на локале, особенно в момент старта проекта.
На уровне инфраструктуры:
- Нужен нормальный CI
- Без docker и k8s я вообще представить не могу микросервисы
Обо всем надо читать, все это нужно уметь, боль :(
Нужно уметь в отказоустойчивость
Падение одного сервиса не должно взорвать все, а без сетевого экрана не представляется возможным зачастую реально понять какой сервис общается с какими сервисами.
youtube.com/watch?v=zfmwd5…
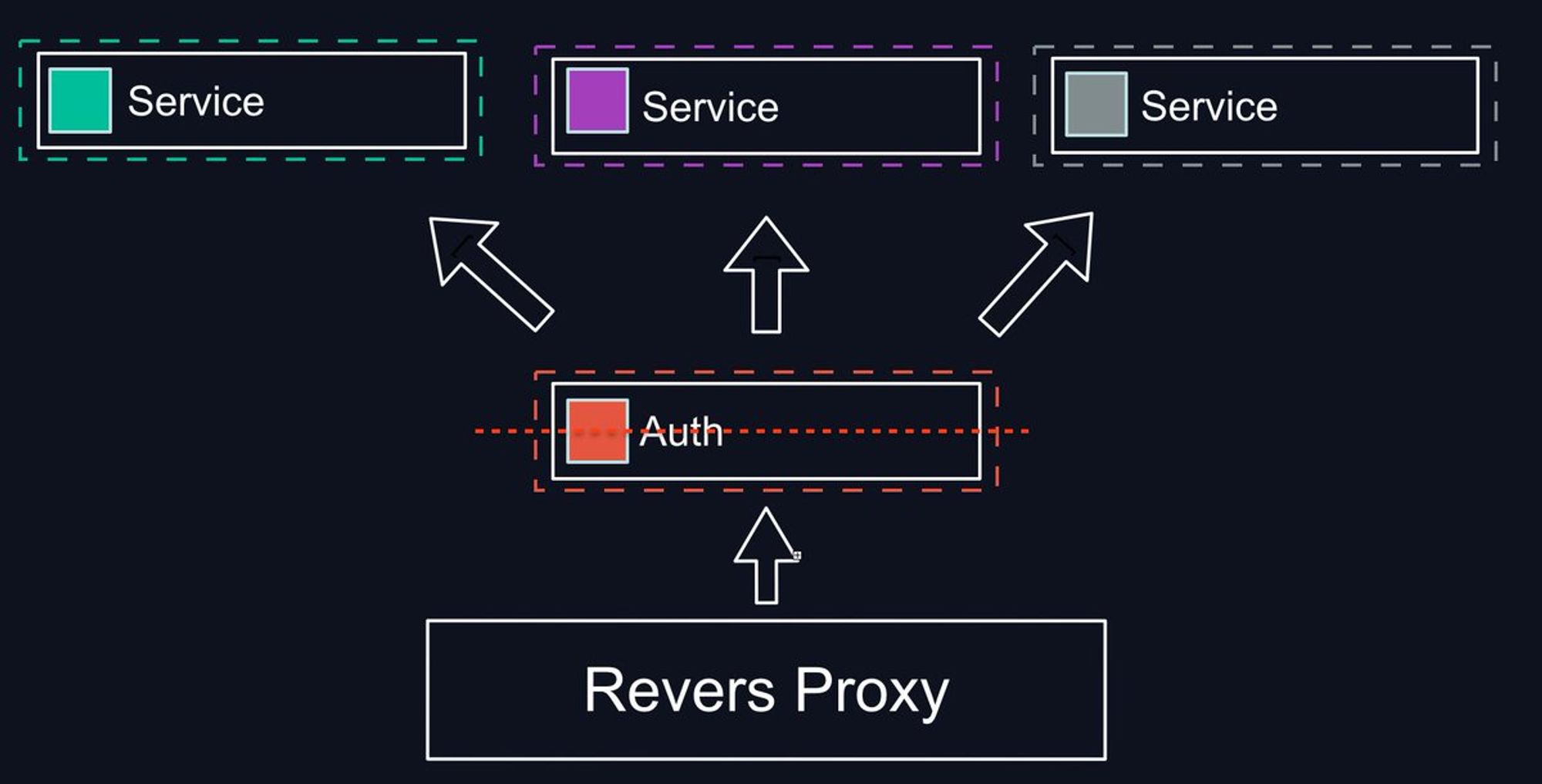
Чтобы понимать, что происходит, нужно уметь в distributed tracing
opentracing.io/docs/overview/…
А теперь представьте, что есть целая цепочка последовательных RPC от сервиса к сервису, и вам нужно понять, где ошибка.
Также нужно постоянно бороться с шаблонным кодом между сервисами, а это бывает крайне сложно. А теперь представьте, что копи-пасте нашлась ошибка и вам нужно пробежаться и поправить какую-то строчку во всех 20 микросервисах.
Нужно уметь в организацию, если разработчики между сервисами не умеют общаться друг с другом. То вы получите реально разные системы и разные подходы, хорошие практики могут не переходить от одного разработчика к другому.

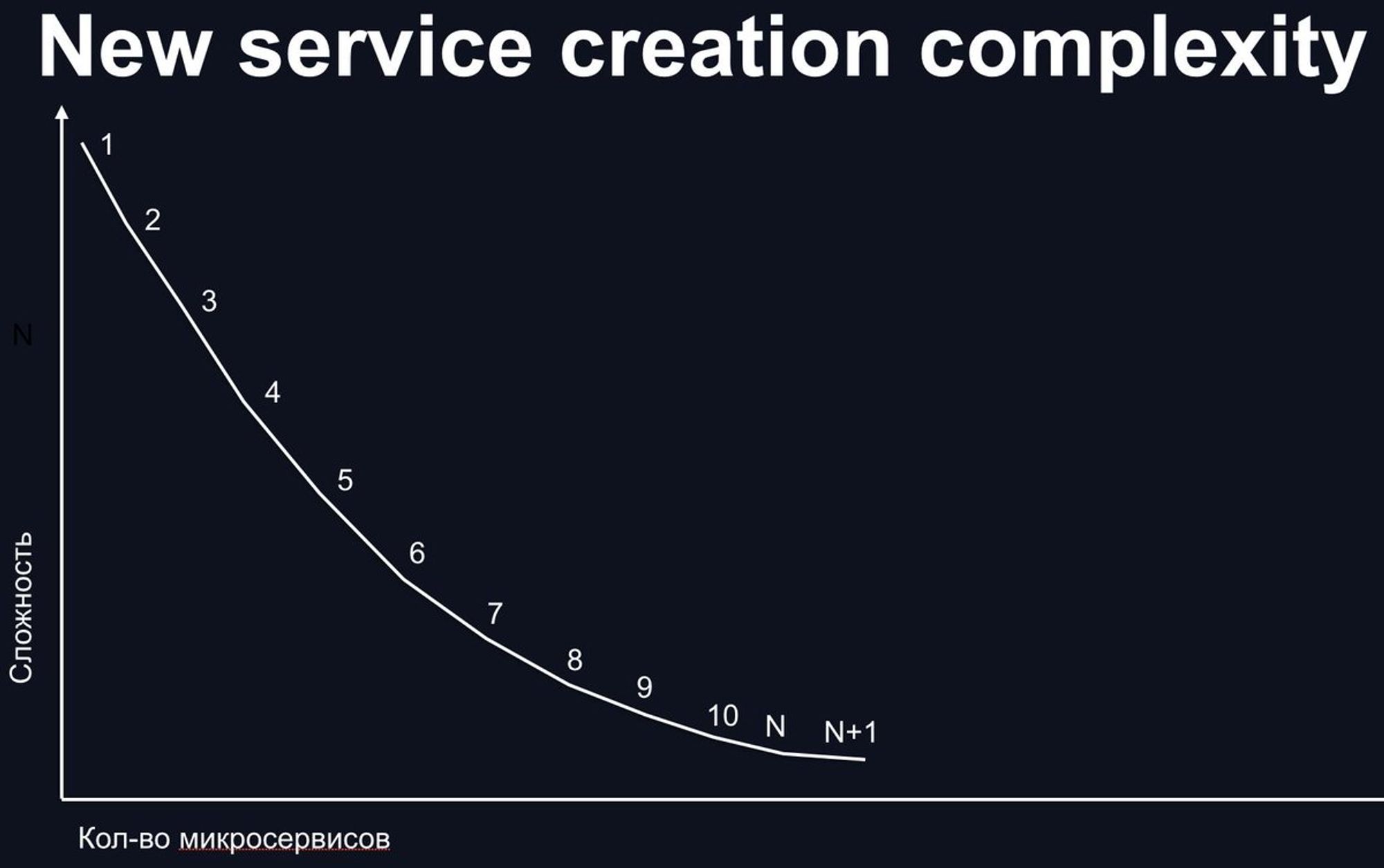
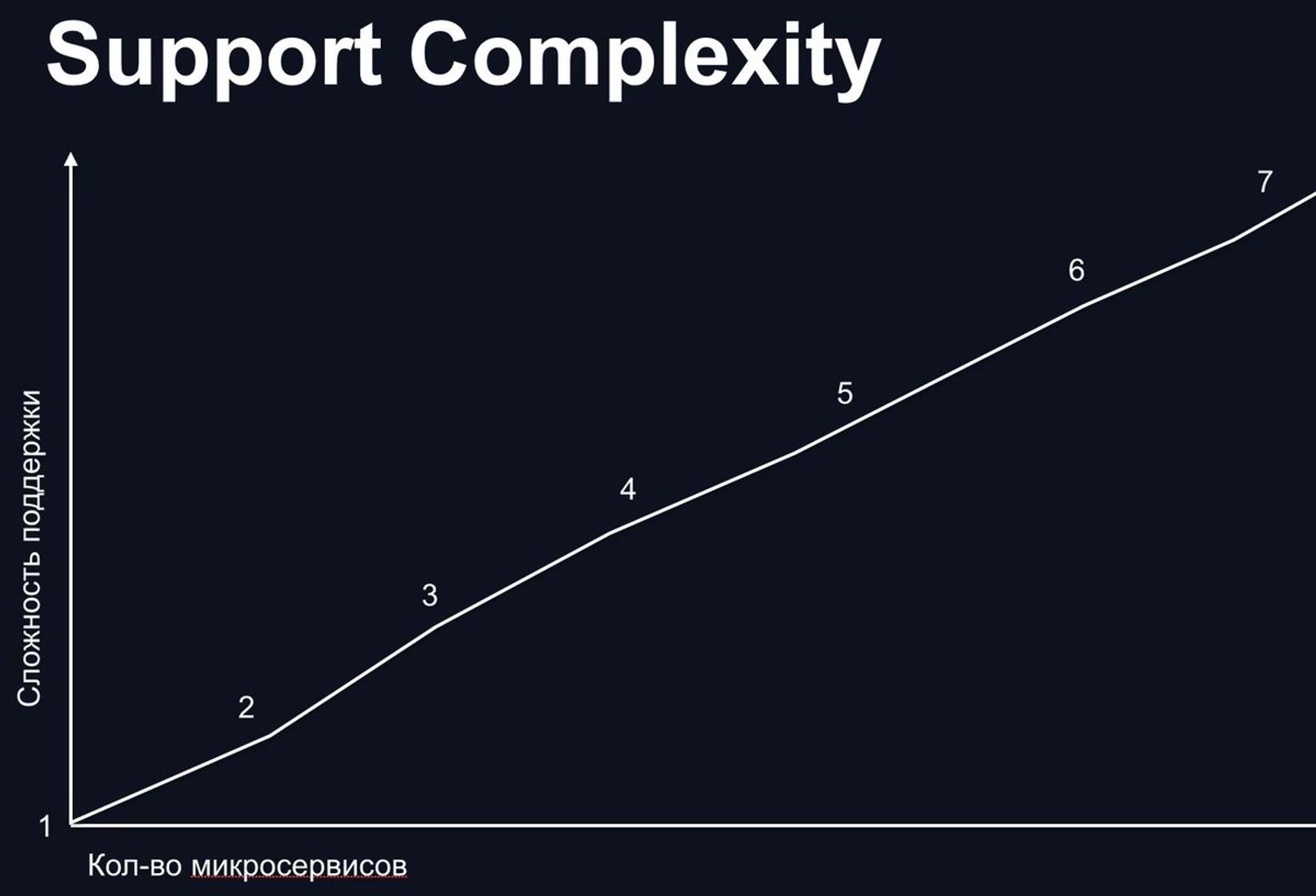
Как итог, для себя я заметил корреляции:
Первые 1...N микросервисов крайне сложно, дальше уже проще. (нужно много опыта)
Поддерживать N+1 микросервис, всегда сложнее чем N. (не старайтесь постоянно делать новые когда этого не нужно)
Тред (@ovrweb)
Среда
Сегодня у нас про менеджмент (технический и не только), расскажу то от чего горит или какие ошибки я видел:
Неумение собирать feedback о себе.
Человек думает что он великий руководитель, творец проектов, квинтэссенция знаний этого мира. Но он банально не слышит людей.
Никто не отменял лицемерие. Все друг другу улыбаются, но не умение собрать отзывы о работе - это является ошибкой менеджмента, а не специалистов.
Получаем:
На проекте полный хаус, руководитель думает что у него все заебись, разрабы горят как ракеты SpaceX с происходящего
Руководитель ходит и говорит всем:
"У нас хорошая команда, мы такой проект подымим"
Как итог, ЧСВ руководителя растет, а команда демотивируется и постепенно уходит.
Если вы руководитель, вытягиваете фидбэк как только можете:
Просите HR сделать форму обратной связи, проводите ретроспективы, измеряйте все метриками, общайтесь со своей командой!
Если команда, не бойтесь донести фидбэк: сказать с чего горит, что плохо, что можно исправить, не получается донести и руководство полные профаны - тiкай з городу.
Компаний много, хороший специалист в IT всегда найдет себе достойную работу с хорошим руководством.
Потерять мотивацию сотрудников и не умение мотивировать
Долгосрочная: вера в руководителя, команду, компанию, продукт. Тут главное понимать, за счет чего держится команда. Если держится за счет руководителя, а не продукта, то тут главное чтобы руководитель не делал ошибок
Если руководитель показал себя с худшей стороны, то отбелить его сможет только tide, надо делать все обдумано.
Если руководитель плохой, то останется из мотивации только деньги/команда/продукт. По этому руководитель должен иметь холодный разум, и думать наперед.
Если плохой продукт, команда плохая, а сотрудник ключевой, можно просто поднять ему $, а не ждать пока он сам придет с увольнительной когда в компании кризис.
И тут без фидбека не обойтись, главное понимать что держит людей. Но обычно никто даже и задумывается об этом.
Самое ужасное:
Не умение общаться с людьми, если это так, то он априори не должен быть допущен к людям. Это самый ад, но такое тоже бывает. Бывает элементарное быдлота от руководства, лучше таких сразу снимать, иначе будет такая лютая атмосфера в компании.
Руководитель должен помнить:
Делает команда, а руководитель управляет и налаживает процессы для управления командой.
Руководитель без команды - это пустое место. Бывает что команда, справляется со всем и без налаженных процессов, а руководитель думает что он классный.
Набирать ненужных людей или пытаться растить команду когда это не нужно:
3.1 Взять слабых людей в сильную команду, тогда команда может расслабиться, зачем работать со всех сил, если новый сотрудник пьет кофе и смотрит в потолок.
3.2 Собеседовать и набирать технических людей без хорошо технического специалиста, и такое тоже бывает.
СТО который N лет уже не программирует, думает что он как рентген смотрит сквозь людей и по общению сможет отличить новый бриллиант для команды от камня.
3.3 Быстро нарастить команду:
Увеличили бюджет и побежали набирать людей в команду.
Было 3 человека, стало 8, но вот так не задача:
Необходимых процессов для команды нет, ввели бюрократию и все усложнили. Теперь 3 человека которые справлялись раньше, уже не тянут и все плохо
Наибольшая команда всегда быстрее по пропускной способности чем наименьшая, но скорость на одного человека в команде падает из-за процессов синхронизации/обсуждения. Растите команду планомерно, по мере улучшение процессов внутри компании.
Forward менеджмент
Не читать задачи, письма и напрямую швырять специалисту.
Как итог:
Специалист что-то сделает как понял, QA тестит тоже как понял, бизнес хотел вообще 3-е.
Не делать BRD (Business Requirements Document)
Если не понять задачу, то будет так:
Вы быстро взялись что-то делать.
Сделали не то, десять раз переделали.
Ни вам, ни заказчику не нравится результат.
Бизнес думает, что вы дебилы.
Вы думаете, что бизнес дебилы.
Чтобы разобраться в задаче, необходимо узнать:
- О бизнесе в целом: как он работает, на чем зарабатывает?
- О ближайшей задаче бизнеса: чего хотят достичь, что изменить?
- О решении, которое он ожидает от вас: что нужно, и почему оно будет работать?
Об ожиданиях от результата:
В каком виде клиент ожидает вашу работу, в какой срок, в каком объеме, на что это будет похоже? С чем связан такой срок?
Разное отношение к работникам
Не обязательно руководитель должен относиться к каждому работнику одинаково, но они должны чувствовать равное отношение к себе. Осознание того, что у вас есть "любимчики" подрывает отношение, как и предвзятость к определённому сотруднику.
Тред (@ovrweb)
Четверг
Пришло время обсудить React-Native:
Про плюсы, минусы, быстрый старт, но без архитектуры, про нее у меня был ломовейший доклад:
youtube.com/watch?v=v4MnR4…
Плюсы.
- Кроссплатформенность (iOS, android, OSX Desktop с помощью developer.apple.com/mac-catalyst/)
- Простота и удобство разработки
- Сокращение затрат времени на разработку
- Близость к нативным приложениям (по производительности и визуально)
Хорошее сообщество и ее участие в разработке и развитии RN:
К примеру: AsyncStorage/NetInfo/Share раньше был в ядре, сейчас вынесен
github.com/react-native-c…
Тот же CLI - отдали комьюнити. Тем самым Facebook ускоряет развитие и привлекает больше контрибьюторов
Минусы:
Bridge не является минусом, это какая-то мистика когда не хватает аргументов у людей в пользу Flutter (кто его продвигает). В своем докладе прям предметно показывал что происходит если JS thread загружен и как работаю анимации.
Главный недостаток это нет major релиза и постоянно ломают совместимость. Каждую версию и по чуть-чуть, зачастую комьюнити библиотеки не успевают обновляться и приходиться допиливать или ждать. Тут надо понимать мотив: команда Facebook хочет поддерживать только хороший продукт
Если не обновляться 3-10 релизов и попробовать обновиться, то проще будет проект рядом создать и перекопировать все.
Раньше было в помощь git-upgrade, сейчас github.com/react-native-c…
Стало лучше, но вот я с 57 -> 60 релиз чуть ли не плакал, чтобы обновиться.
Про подводные камни при разработке на RN, советую еще глянуть статью:
medium.com/lowl/5-%D0%BF%…
Хоть и статья 2017го года, но актуальность она не потеряла.
Переходим к советам по быстрому старту на RN и куда смотреть:
Начинайте ваш проект сразу с TypeScript:
TypeScript стал де-факто стандартом, времена flow прошли, писать код без типизации крайне не оправдано.
facebook.github.io/react-native/d…
С первой же секунды вам нужна библиотека навигации:
Они бывают двух типов: нативная и не нативная (написанная полностью на JS). Крайне рекомендую брать react-navigation (не нативную, проверенную библиотеку, которая уже пережила не один major релиз)
reactnavigation.org
В документации заострите ваше внимание особенно на:
reactnavigation.org/docs/en/common…
reactnavigation.org/docs/en/auth-f…
reactnavigation.org/docs/en/typesc…
@jsunderhood а что на счёт reasonml? я всё чаще слышу что проекты на нём стартуют
В живую и даже в слухах не слышал чтобы где-то реально был reason. Знаю что есть github.com/reason-react-n…. Есть кто может поделиться опытом? twitter.com/kitos_kirsanov…
Будьте осторожны:
- Используйте одинаковую версию nodejs через .nvmrc когда работаете в команде (обжигались)
- Кешированием в metro bundler (обжигались тоже, привет --reset-cache)
Выберите любой понравившейся UIKit если только у вас нет желания сделать свой в процессе работы (допустим вы большая компания/продукт) или делаете множество приложений и вам будет удобнее использовать и допиливать свой.
blog.bitsrc.io/11-react-nativ…
Решите:
Нужно ли что бы ваше мобильное приложение было offline first (использование базы данных). Если решили использовать БД, помните: не нужно хранить данные в двух местах redux + DB.
Из баз классно очень выглядит github.com/realm/realm-js
Но у него есть 3 большие проблемы:
Медленно развивается и можно встретить баги
github.com/realm/realm-js…
У них один пакет для nodejs и react-native. Обычно команда не успевает за новым nodejs и нативный аддон к node мешает установки пакета для rn.
github.com/realm/realm-js…
Не юзабельно в debug режиме (когда код исполняется в браузере через RPC).
github.com/realm/realm-js…
Realm скрывает все объекты при дебаге делая их Proxy, и каждое обращение к полю это отдельный RPC запрос. Как итог вывести 10 строчек по 3 поля, это 1 + 3 * 10 запросов.
Это прям какой-то ад, а еще сетевой стэк под эмулятором в android дико медленный, что делает дебаг режим под android совсем не юзабельным.
Какие альтернативы?
Я начал пробовать TypeORM поверх SQLite
github.com/typeorm/typeorm
github.com/andpor/react-n…
Но говорить еще рано :)
Пятница
Локализация для проекта
Советую взять github.com/i18next/i18next, а что бы вычислить какой язык взять (нативный модуль) github.com/react-native-c…
Вот тут есть пример:
github.com/i18next/react-…
Конфигурация per environment
Раньше использовал:
github.com/FormidableLabs… (но он не перешел на babel 7)
Сейчас юзаю:
github.com/zetachang/reac… (но поддерживает только 2 env из коробки)
Есть еще:
github.com/luggit/react-n…
Для анимаций советую брать github.com/kmagiera/react…
Дико удобная штука!

Для SVG есть github.com/react-native-c…
Но иногда нужна помощь дизайнеров что бы они переделали "оптимизировали" svg и это отображалось нормально.
Еще можно конвертировать SVG в компоненты и к примеру программно менять цвета (как идея) :)
smooth-code.com/open-source/sv…
Деплойте используя FastLane/CI
fastlane.tools
Для Android проще и правильнее делать билд через подготовленный image в docker используя CI, где есть java/build tools/ruby
Пример:
github.com/react-native-c…
Для OSX все сложнее, нужен worker c macOS
Подготовка к @HolyJSconf идет полным ходом, а так как доклад будет хардкорным, изобретаю VM на JS которая будет работать с V8 ignition bytecode (для демо), что бы показать на простых примерах как это все работает. Смотри скриншоты. pic.twitter.com/E6UYYQPklx
Пользуясь случаем, хочу рассказать и позвать на свой доклад который готовлю к @HolyJSconf
Доклад хоть и называется "Разработка компилятора для TypeScript на TypeScript на базе LLVM", но будет состоять из двух частей: twitter.com/ovrweb/status/…
Суббота
Обязательно используйте средства для отслеживания ошибок/падений, крайне дико рекомендую взять Sentry.
docs.sentry.io/clients/react-…
Сервер можно установить на свое железо, это open source
У него хорошая документация и модуль который уже себя зарекомендовал
Воскресенье
После 32 alpha релизов, webpack 5 сделал beta-0 🎉 и ожидает фидбэка бесстрашных frontend разработчиков
github.com/webpack/webpac…
И тут я решил попробовать....

Уделите время изучение Flexbox.
FlexBox в RN крайне похож на FlexBox который мы используем в web. Чтобы не страдать, советую этой теме изначально уделить побольше времени в документации и конечно же практике.
facebook.github.io/react-native/d…
Уделите немного внимания структуре проекта, а то если приложение большое, может быть не удобно смотреть на N файлов в одной папке.
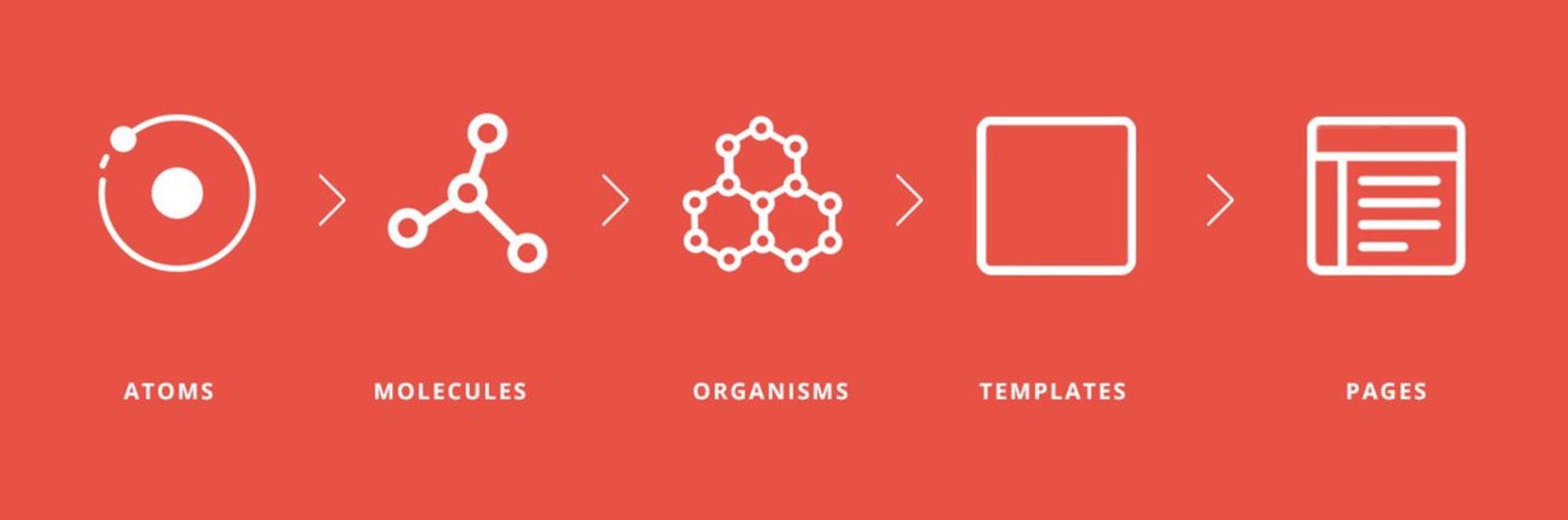
Советую вдохновиться Atomic Design Pattern:
medium.com/@janelle.wg/at…
Только вместо pages у нас screens ;)
Не забывайте про тесты:
12.1 Минимум это snapshot test на ui библиотеку
jestjs.io/docs/en/tutori…
12.2 Покрыть чуток unit тестами
12.3 e2e тесты, хотя бы парочку нужно (топорная защита от релизов когда приложение падает на старте)
Используйте множество каналов для деплоя:
Для Play Market начинайте:
В internal channel (разработчики и тестеры)
alpha (+ свои люди)
beta (открытая бета на пользователях)
market
Всегда постепенно, не торопитесь выпустить релиз как можно быстрее.
Будь готовы к apple review:
- Это всегда занимает время
- Могут вернуть на доработку
- Требования растут постепенно к приложению с каждым релизом
Они реально тыкают приложение, ни разу не видел чтобы просто так допустили без просмотра.
Нельзя пожаловаться на контент внутри прилаги, а это соц. сеть - лови reject. Не смогли авторизоваться для теста - reject, используешь старый API - reject, нашли где падает - reject.
Тред (@ovrweb)
Моя неделя подходит к концу, с вами был Дмитрий Пацура @ovrweb. Буду рад видеть на github.com/ovr или лично на @HolyJSconf. Не забываем слушать самый безызвестный подкаст @UnderJS ;)
На это неделе мы обсудили 4 большие темы: