

Архив недели @ierhyna
Понедельник
Всем привет! Меня зовут Ирина @ierhyna, я фронтенд-разработчик в Semrush. Последние полтора года занимаюсь улучшением web performance на уровне всей компании, об этом в основном и буду рассказывать :)
@jsunderhood @ierhyna performance очень круто и сложно, нужно много времени, чтобы погрузиться и разобраться, уж точно не нужно от разработчиков спрашивать как required skill
Я считаю, что хороший разработчик должен знать best practices по веб-производительности, ведь разработка это не только про код, но и про то, как он в итоге работает. twitter.com/iGontarev/stat…
Давайте для начала познакомимся, сегодня расскажу немного о себе и своём пути в разработке.
Наверно как и многие, я увлеклась программированием ещё в школе. К сожалению, не благодаря, а скорее вопреки школьной программе по информатике — даже учебные языки, как и нормальные учебники, в нашу глубинку не завезли, и на уроках мы учились включать компьютер.
Тут надо пояснить, что я росла в маленьком посёлке в Ханты-Мансийском округе, и о такой профессии, как "программист", там никто не слышал.
Примерно в 2001 году дома появился компьютер и интернет. Но он был медленным и с поминутной оплатой, поэтому единственным способом что-то прочитать было открыть все интересные страницы, нажать "Сохранить как html", и отключить соединение. Так я узнала о существовании html 😄
Моим любимым развлечением стало открывать сохраненные страницы в Блокноте, что-то там менять, открывать в IE, и смотреть, что произошло.
Потом я нашла самоучитель HTML с сайта "постройка-ру", и понеслось :) Сделала страничку про наш класс, сайт про Гарри Поттера, сайт со стихами подруги, и разместила всё это на каком-то бесплатном хостинге.
Но когда возник вопрос, на какой факультет я буду поступать, мысли про IT даже не возникло. Сайты делать? Да кто же за это будет платить? А инженер в моем понимании тогда — тот, кто ремонтирует теплосети. Так, не без убеждения родителей, я оказалась на истфаке.
Учиться было сложно ("прочитайте 600 страниц к семинару на завтра", и так по всем предметам), а временами даже физически тяжело (привет, археологическая практика!), но интересно. А навык работы с большим объемом информации, полученный за время учёбы, оказался полезен.
На третьем курсе преподаватели узнали о том, что я умею делать сайты, и меня стали привлекать к работе над грантами. Они проводили исследования, а я оформляла их в виде красивых веб-страничек, и получала за это большие для студента 30-50 тысяч рублей.
Вдохновившись этим успехом, летом после 3го курса мы с приятелями основали свою веб-студию, чтобы делать сайты-визитки для местных компаний. И так в моей трудовой появилась первая запись "директор", которую я сама туда и вписала :)
Бизнес не взлетел, и через год мы закрылись. В 20 лет это было просто, походы в налоговую казались приключением, а сейчас фиг бы я такое ввязалась ещё раз.
Я поняла, что мне больше нравится делать что-то самой, чем организовывать работу людей. И с 2012 года стала заниматься разработкой на фрилансе. О основном, вёрсткой, темами и плагинами для WordPress. Появились постоянные клиенты, но для меня это было скорее хобби, чем работа.
В таком режиме прошло три года, я работала в разных местах якобы по специальности, а по ночам фрилансила. И однажды поняла, что больше так не могу, и хочу развиваться в разработке. Уводилась и через неделю устроилась в первую фирму, куда меня взяли фронтендером без опыта в 25 лет
Сейчас понимаю, что явно себя недооценивала: я имела опыт в open source, умела использовать git, настраивать деплой не через ftp, сборку с gulp и browserify (был 2015 год). Но думала, что без коммерческого опыта меня никуда не возьмут, и согласилась на первый оффер
Кстати, та фирма заплатила мне за тестовое задание!
Но через полгода основатели поругались, и фирма закрылась 😅 Решив, что со стартапами покончено, я устроилась в DataArt, и за два с половиной года там выросла из кого-то между джуном и мидлом до синьора (по их внутренней шкале).
Кстати, про DataArt я узнала благодаря этому андерхуду. Пришла на собес, а там @suevalov, который вёл неделю. И я сразу захотела там работать 😅😅
А потом я устала от аутсорса. Захотелось погрузиться в продуктовую разработку и видеть, как твои решения влияют на пользователей, понимать, что будет с твоим кодом через год, принимать долгосрочные решения и нести за них ответственность.
С этими мыслями я пришла в Semrush, где работаю чуть больше 2,5 лет. Сначала я занималась фронтом в только своей команде, а потом присоединилась к рабочей группе по веб-производительности, участвую в создании общих рекомендаций и помогаю другим командам делать их продукты быстрее
Тред (@ierhyna)
Вторник
Доброе утро! В ближайшие три дня планирую рассказать:
- о метриках webperf: как замерить, насколько приложение быстрое?
- как ускорить приложение и улучшить метрики?
- о процессах работы над производительностью у нас в компании.
Давайте проведём несколько опросов, чтобы я лучше понимала, о чем именно и насколько подробно писать :)
Занимаются ли в вашей компании веб-производительностью?
🤔
6.2% Да, отдел/роль в компании🤔
14.5% Да, тимлид/роль в команде🤔
53.8% На усмотрение команды🤔
25.5% НетЕсли вам скажут, что ваше приложение/сайт медленный, знаете ли вы, как это проверить?
🤔
32.8% Хорошо знаю🤔
53.4% Знаю немного🤔
13.8% Ничего не знаюЕсли нужно сделать ваше приложение/сайт быстрее, знаете ли, как можно это сделать?
🤔
32.3% Да🤔
51.3% Догадываюсь🤔
12.2% Нет🤔
4.2% Никак, оно и так быстрое!Тред (@ierhyna)
Первая тема — о метриках web performance. Как замерить, насколько приложение быстрое, какие для этого существуют метрики и инструменты.
Пожалуй, самый известный инструмент для отслеживания веб-производительности, это Lighthouse. Я надеюсь, что о нём все слышали :) Его можно запустить прямо из devtools Chrome. Лучше делать это в анонимном окне, чтобы на результат не влияли плагины и кеш.
Однако на результат может повлиять конфигурация вашего компьютера, поэтому лучше запускать проверки в изолированном окружении. Например, через PageSpeed Insights, который показывает те же данные, что и Lighthouse developers.google.com/speed/pagespee…
Получить более подробные данные, на изолированном окружении, можно через Web Page Test. Он позволяет сравнивать результаты между собой, смотреть трейсы, и обладает довольно гибкой настройкой через скрипты webpagetest.org
На основе Web Page Test работают многие другие инструменты, например, Speedcurve speedcurve.com, который мы используем для отслеживания метрик в Semrush.
Но Speedcurve, в отличие от Web Page Test, платный.
@jsunderhood Lighthouse измеряет только скорость загрузки страницы, практически ничего не говорит о возможной скорости ее использования и вообще ничего не говорит о скорости переключения между страницами (особенно актуально для SPA). А есть инструменты для аналитики перфа SPA?
Для отслеживания скорости переключения между страницами и взаимодействия, например, когда по действию что-то появляется, можно использовать скриптинг и Custom Metrics в WebPagetest. Я это настраиваю через SpeedCurve, но под капотом там тоже WebPagetest. twitter.com/artalar_dev/st…
Смысл в том, что когда на странице происходит какое-то изменение, нужно выполнить performance.mark('my-mark'), и это отслеживается скриптом WebPagetest.
То есть нужно будет дописать в коде метрики в тех местах, производительность которых требуется отслеживать
Ещё есть вкладка Performance в хроме, где можно профилировать приложение, но пока я не буду на этом останавливаться
Если вы знаете и используете какие-то другие инструменты для мониторинга производительности, напишите! А я пока перейду к метрикам.
Метрик производительности довольно много. Они показывают определенные события, которые происходят в процессе загрузки страницы (таких метрик большинство), либо в процессе взаимодействия с ней.
Отслеживать все возможные метрики не нужно — мы поначалу так делали, но потом поняли, что это довольно бессмысленно.
Сейчас мне кажется оптимальным следить за Core Web Vitals, это отличный вариант, если вы не знаете, с чего начать. Во-первых, именно они влияют на показания лайтхауза, и во-вторых, дают представление как о загрузке, так и интерактивности. web.dev/vitals/
Особенно важны Core Web Vitals, если у вас сайт, индексируемый поисковиками — гугл умеет определять скорость загрузки страниц на основе этих метрик, и выше в выдаче оказываются более быстрые страницы.
Если у вас SPA, или приложение, которое не индексируется, Core Web Vitals можно рассматривать как показатель скорости загрузки, что пользователь не смотрит на начальный спиннер по пять минут.
@jsunderhood В какой момент нужно задумываться о производительности и начинать её измерять?
Хороший вопрос. В идеальном мире, на этапе проектирования. В реальности, перед выходом в продакшен уже хорошо. Мы задумались через 8 лет существования продукта, и теперь встречаем проблемы, связанные с архитектурой и инфраструктурой. twitter.com/NUM13RU/status…
Скорее всего, для мониторинга интерактивности SPA потребуется добавить собственные метрики, которые будут показывать скорость работы отдельных элементов интерфейса при взаимодействии с ними, через preformance.mark() и performance.measure()
Для отслеживания скорости переключения между страницами и взаимодействия, например, когда по действию что-то появляется, можно использовать скриптинг и Custom Metrics в WebPagetest. Я это настраиваю через SpeedCurve, но под капотом там тоже WebPagetest. twitter.com/artalar_dev/st…
Я немного рассказала об этом в соседнем треде: twitter.com/jsunderhood/st…
В зависимости от используемого инструмента, метрики можно визуализировать на графиках. Вот, например, так выглядит график с Custom Metric vs Largest Contentful Paint одного нашего SPA
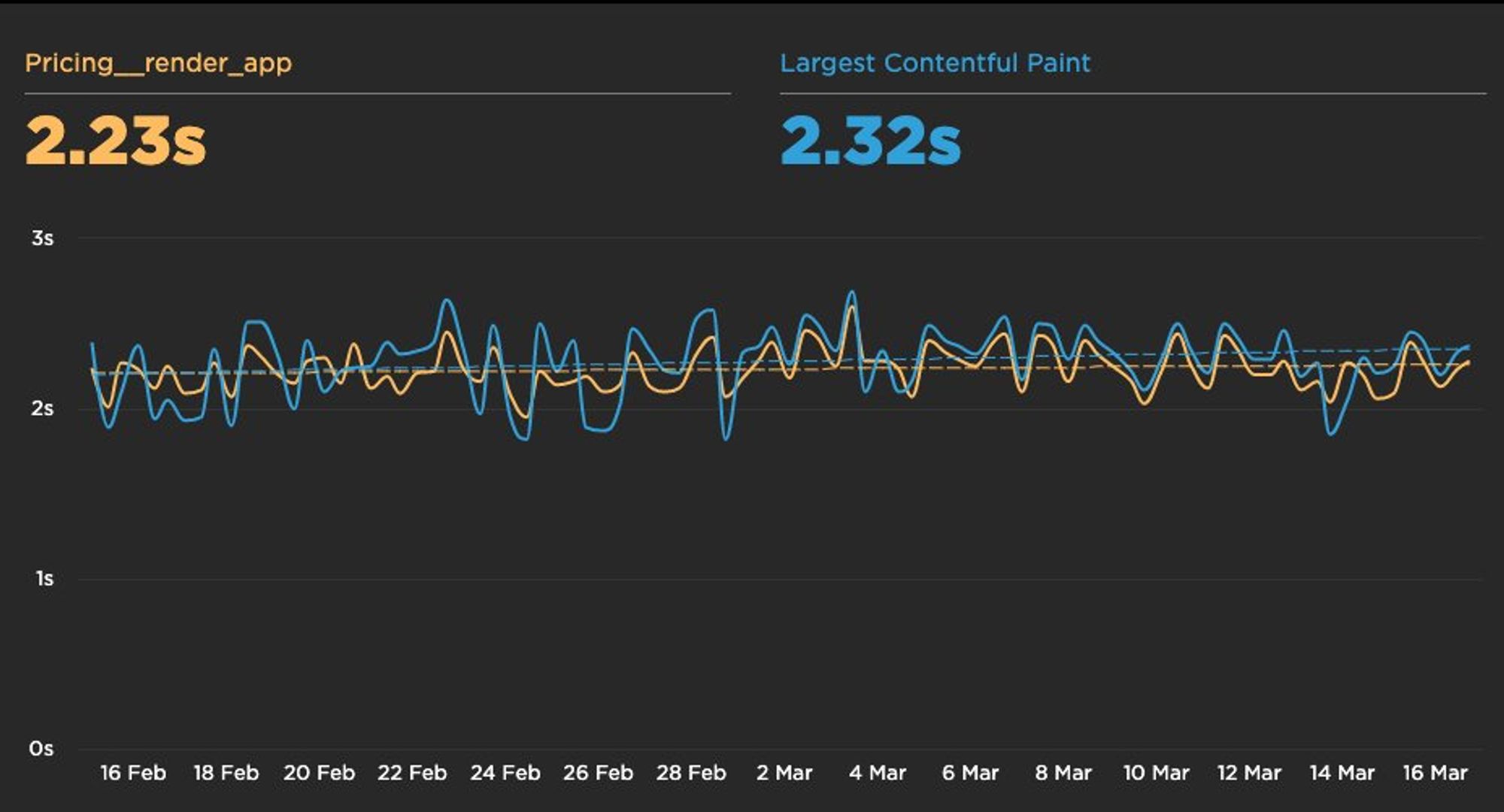
Тред (@ierhyna)
@jsunderhood Что скажешь по поводу недавнего добавления поддержки HTTP/2? "With this improvement, you can expect more similarity between Lighthouse results from PSI and from Lighthouse CLI and DevTools" seroundtable.com/google-pagespe…
Спасибо, пропустила эту новость. Мне кажется, что для сервисов, использующих HTTP2, синтетические метрики будут более приближены к реальности. Но нужно быть готовым, что значения метрик могут неожиданно улучшиться :) twitter.com/4rontender/sta…
@mr_mig_by @jsunderhood Если это базовое свойство системы, то оно должно быть зафиксировано в требованиях, при этом с конкретными измеряемыми целевыми показателями. "Медленно" и "быстро" это субъективные ощущения и если главный прОдукт "подписал" требования без них, то получил что хотел.
В моём представлении, разработчик участвует во всех этапах жизни приложения. Требования не должны появляться, потому что их кто-то подписал или не подписал. Иначе получается, что продакт не внёс в спеку, разработчик не сделал, тестировщик не проверил, а жить с этим пользователю twitter.com/stuffed_seal/s…
@jsunderhood В интерактивных приложениях немного другая модель. Например навигация должна быть максимально быстрой, как допустим переключение папок на десктопе, а вот навигация с действием (создание или открытие документа) ожидаемо медленная, как и открытие файла допустим в Фотошопе и т.п.
UX и визуальная производительность очень интересная тема! twitter.com/roman01la/stat…
Среда
@jsunderhood А у вас как-то эта история автоматизирована (например, после выкатки очередного билда приходит репорт, что вот такие-то страницы стали на x пунктов быстрее или на y медленнее)? Или это все фантастика и приходится переодически гонять все руками и разбираться почему стало хуже?
У нас сбор, мониторинг и алерты по метрикам настроены через SoeedCurve, данные собираются несколько раз в сутки, и можно вручную запустить после деплоя. Если происходит превышение лимитов, по в слак ответственной команде приходит уведомление twitter.com/query_string/s…
Привет! Сегодня расскажу о том, как устроены процессы работы над web perf у нас в компании.
Немного контекста. В Semrush много (30-40?) кроссфункциональных команд разработки, и каждая полностью отвечает за свой продукт: выбирает стек технологий, решает, какие фичи должны быть, в каком порядке и как их делать.
И есть инфраструктурная команда, которая делает интеграционный сервис с общими частями интерфейса и API, куда все остальные команды встраивают свои SPA.
Отсюда следуют несколько особенностей:
Стек технологий у всех команд очень разный. Пожалуй, общее только то, что фронте почти у всех TS + React (потому что у нас собственный UI Kit для него). Остальные библиотеки могут быть любыми. А на бэкенде вообще что угодно: php, node.js, go, java, c++.
Это, с одной стороны, повышает вовлеченность команд в их работу (многих мотивирует то, что они сами принимают решения по технологиям и могут пробовать новое), но с другой — создаёт некоторые сложности в выработке общих решений и подходов к производительности.
Для принятия решений, которые будут влиять на работу многих команд, создаются рабочие группы из заинтересованных участников. Так, есть рабочая группа по веб-производительности в разработке, унификации UI у дизайнеров, и другие
Так как команда саа принимает решения по своему продукту, мы, как рабочая группа по webperf, не можем "заставить" их что-то делать. Скорее рекомендуем и рассказываем, как сделать лучше. Но за полтора года я не помню случая, когда кто-то отказывался следовать рекомендациям
Еще одна особенность, вызванная архитектурой, где много SPA встраиваются в общий сервис — при переходе по меню, пользователь скачивает заново все ресурсы для каждого SPA, в том числе общие (UI kit, React&co).
До того, как мы начали заниматься улучшением скорости загрузки и оптимизировать размеры бандлов, типична была ситуация, когда за получасовой сеанс работы, выполняя свои ежедневные задачи, пользователь скачивал 200mb JS файлов, и пять минут смотрел на спиннеры.
@jsunderhood Простите, пожалуйста, за вероятный повтор. Может пропустил. Но сколько человек в вашей "рабочей группе по webperf"? Я так понимаю, что она одна на всю компанию?
В рабочей группе 2 фронтенд-разработчика и engineering manager, так как в основном мы фокусируемся на фронтенде. При необходимости, нам помогают админы и SRE. twitter.com/4rontender/sta…
У нас есть некоторое разделение ролей, я больше занимаюсь "экспертизой", создаю общие решения, и консультирую команды; второй разработчик больше занимается "технической" частью, настройкой инструментов; engineering manager организует работу на уровне компании
Но мы в целом готовы подхватить задачи друг друга :)
Когда мы решили заняться оптимизациями веб-производительности, основными задачами стали:
- выбрать метрики и их значения
- каким инструментом их мониторить
- какие продукты нужно оптимизировать в первую очередь
- найти решения, которые помогут всем командам
Список метрик мы определили исходя из типа приложения: для статичных страниц и для SPA.
Для статичных страниц отслеживаем:
- Time to First Byte,
- Largest Contentful Paint,
- Cumulative Layout Shift,
- Time to Interactive,
- Total Blocking Time,
Раньше в этом списке была Visually Complete, но потом мы её исключили.
Для SPA метрики те же, и дополнительно отслеживаем собственную метрику First App Render, которая показывает в секундах первый рендер, совершенный из SPA.
Значения метрик мы выбирали, основываясь на:
- попадание в нижнюю границу зеленой зоны Lighthouse
- их достижимость
- анализ этих метрик в приложениях конкурентов
Список метрик и их значений общеизвестен в компании, хранится в Confuence, и при необходимости обновляется.
Также есть рекомендации по размерам JS/CSS-бандлов, их значения тоже немного отличаются для статичных станиц и для SPA.
При выборе инструмента мониторинга ориентировались на возможности создать "спейс" для каждой из команд разработки, разграничения доступа, гибкость настройки, цену, и другие критерии. Остановились на SpeedCurve. К сожалению, не знаю, какие варианты ещё рассматривались.
Через SpeedCurve мониторим как синтетические метрики (lab tests несколько раз в день), так и снимаем данные по производительности с реальных пользователей.
Для каждой команды разработки настроен свой спейс с дашбордами (по дашборду на каждый продукт команды), на которых выведены обязательные для отслеживания метрики. Ребята могут при необходимости сами добавлять новые дашборды и выводить на них другие метрики, если считают нужным
Если по какой-то метрике произошло превышение допустимого значения, об этом приходит уведомление в Slack команде.
Приложения, которые нужно оптимизировать в первую очередь, выбрали количеству трафика и критичности для пользователей. В этот список попали большинство публичных страниц, логин-регистрация, и несколько SPA.
С командами, отвечающими за эти сервисами, вели точечную работу:
- Проводили фронтенд-аудит производительности страницы или приложения,
- по итогам составляли список рекомендаций и улучшений,
- передавали список команде, отвечали на вопросы,
- через 3 месяца проверяли повторно
Это дало неожиданный эффект, некоторые команды, у которых ещё не был запланирован webperf-аудит, сами находили проблемы в своём продукте и чинили их :)
В течение года, мы провели аудиты примерно 20 команд, и поняли, что дальше продолжать не очень эффективно — в приложения добавляются новые фичи, и нужно повышать знания разработчиков и сделать так, чтобы забота о производительности стала частью процесса их работы
Теперь делаем аудит по запросу от команд, чаще всего это бывает перед выходом нового продукта в продакшен.
Если у вас похожая ситуация, то полезным может быть выделить самый распространенный user flow, понять, какие продукты пользователь встречает выполняя ежедневные задачи, и сфокусироваться на их оптимизиции.
Оказалось, что многие проблемы общие у разных команд/продуктов, и можно создать единый список рекомендаций, best practices, и даже примеров кода, которые улучшают производительность
Про рекомендации, случаи из практики, best practices, планирую рассказать завтра и послезавтра
Попросили показать, как выглядят дашборды. Показываю :) Красная горизонтальная линия — отметка на которой происходит алертинг.
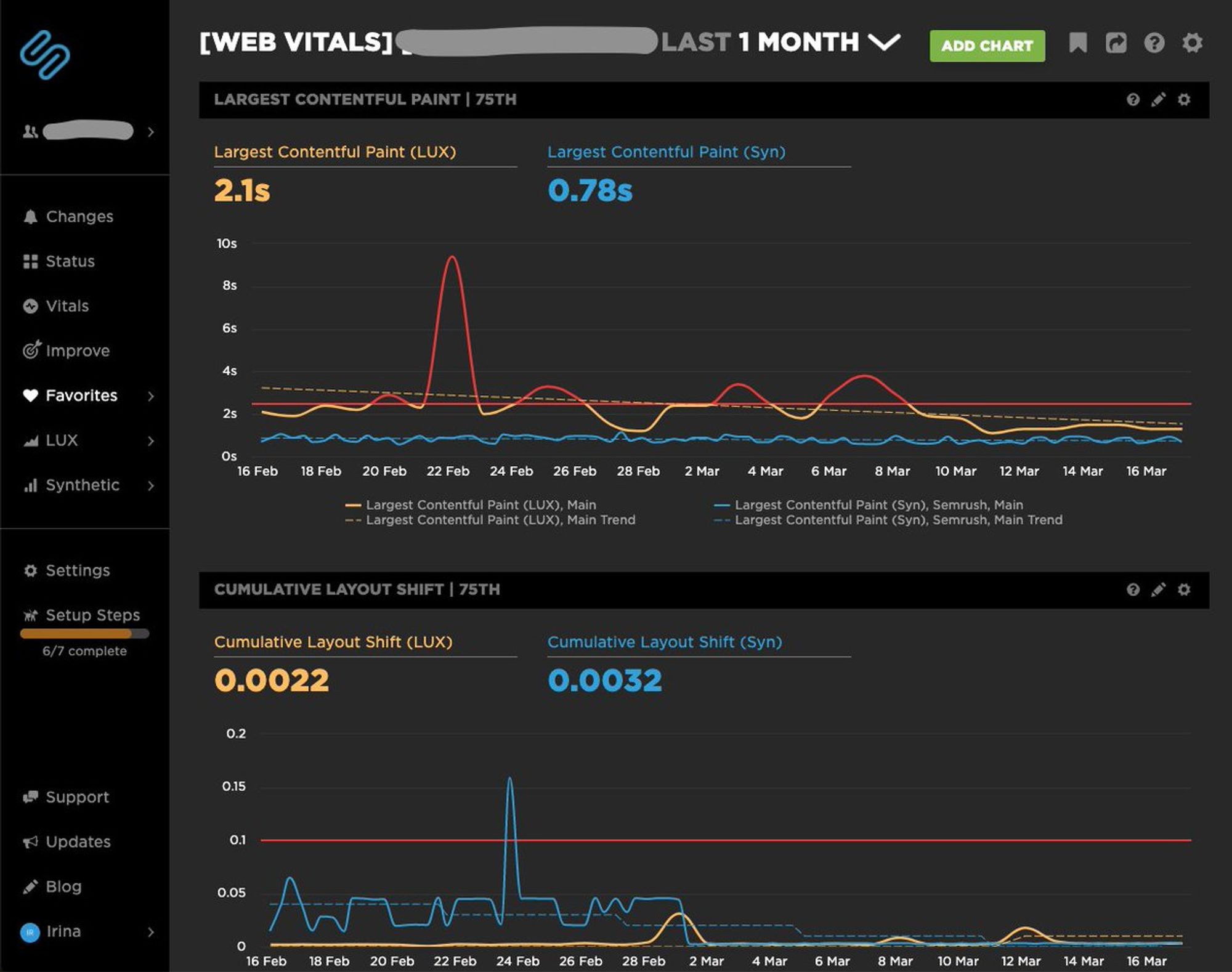
Тред (@ierhyna)
⏱ Улучшение метрики First Contentful Paint (FCP) — нелегкая и комплексная задача. Однако, есть простые шаги с которых можно начать, чтобы без больших затрат значительно ускорить отображение контента страницы. Трэд ⬇️
Тред про улучшение метрики First Contentful Paint (FCP) twitter.com/Omgovich/statu…
Пятница
Привет! Сегодня поговорим про оптимизации, что влияет на метрики, расскажу про best practices и случаи из жизни :)
Выделю три основные направления возможных оптимизаций:
- размеры бандлов и их доставка
- загрузка и отрисовка страницы
- взаимодейстивие со страницей, отзывчивость, UX
Про бандлы и доставку:
Кажется очевидным, но почему-то часто об этом забывают:
- включите сжатие gzip/brotli для ресурсов
- используйте в вебпаке хеш от контента в имени файла, и включите кеширование на подольше (у нас на месяц)
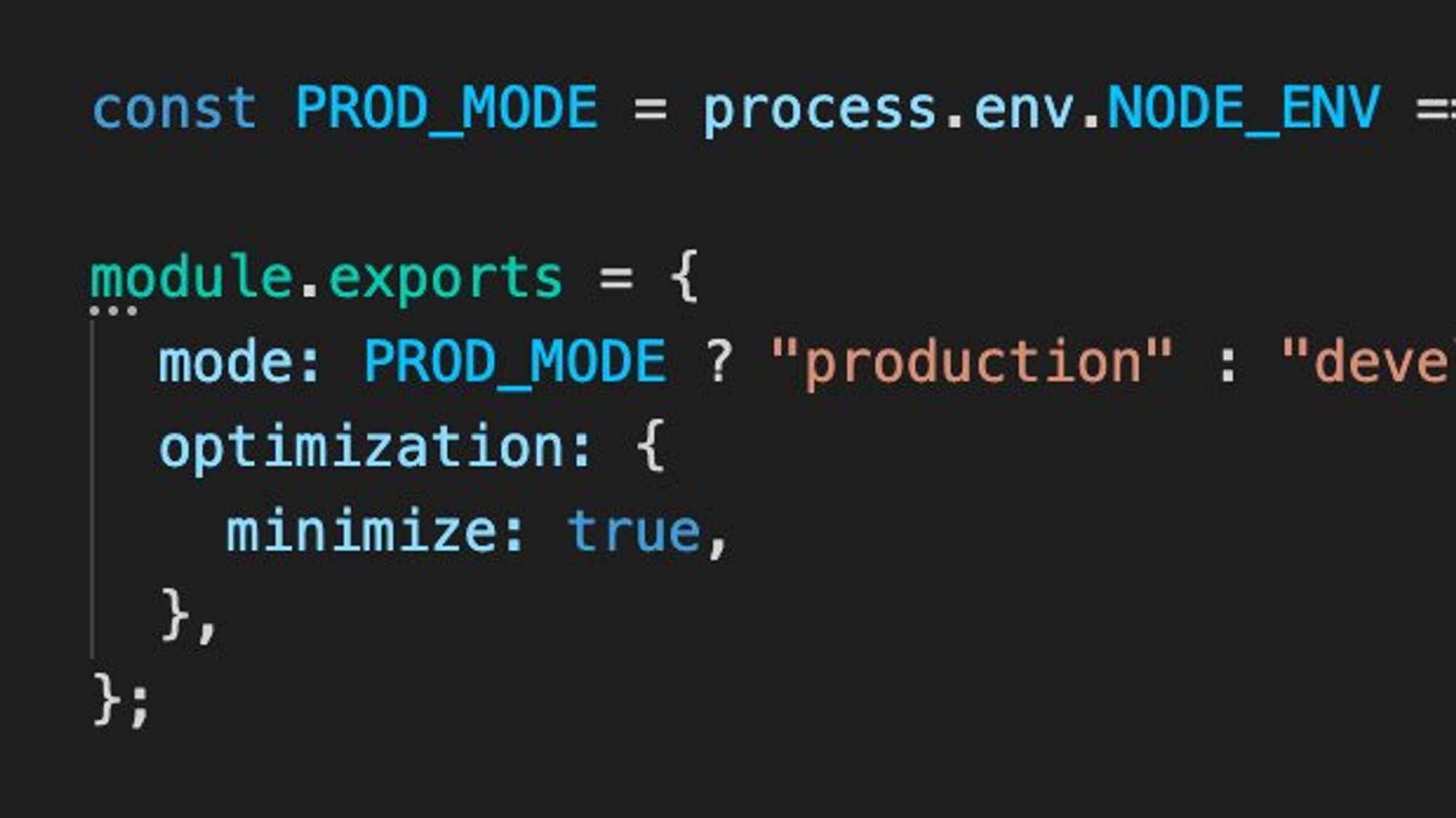
Тоже очевидно, но всё же, убедитесь, что вебпак собирает бандлы в продакшен-режиме с включенной опцией minimize:
Следующим шагом можно настроить в вебпаке разбивку на чанки. Чтобы это сделать, неплохо для начала проанализировать, из чего состоит итоговый бандл. Например, с помощью webpack-bundle-analyzer
npmjs.com/package/webpac…
Распространён подход, когда в один чанк (или несколько) выносят зависимости node_modules, а в другой код приложения. Это кажется не очень оптимальным, поскольку при таком подходе при первой загрузке приложения пользователь всё равно скачает всё.
Лучше, изучив состав бандла через webpack-bundle-analyzer, выделить в отдельный чанк общие зависимости для всех роутов приложения (например, реакт, роутер, redux, и UI-kit), а зависимости, используемые в 1-2 страницах, включить в состав чанка этой страницы
Для генерации отдельного чанка для каждого роута отлично подходит React.lazy() в сочетании с react-router ru.reactjs.org/docs/code-spli…
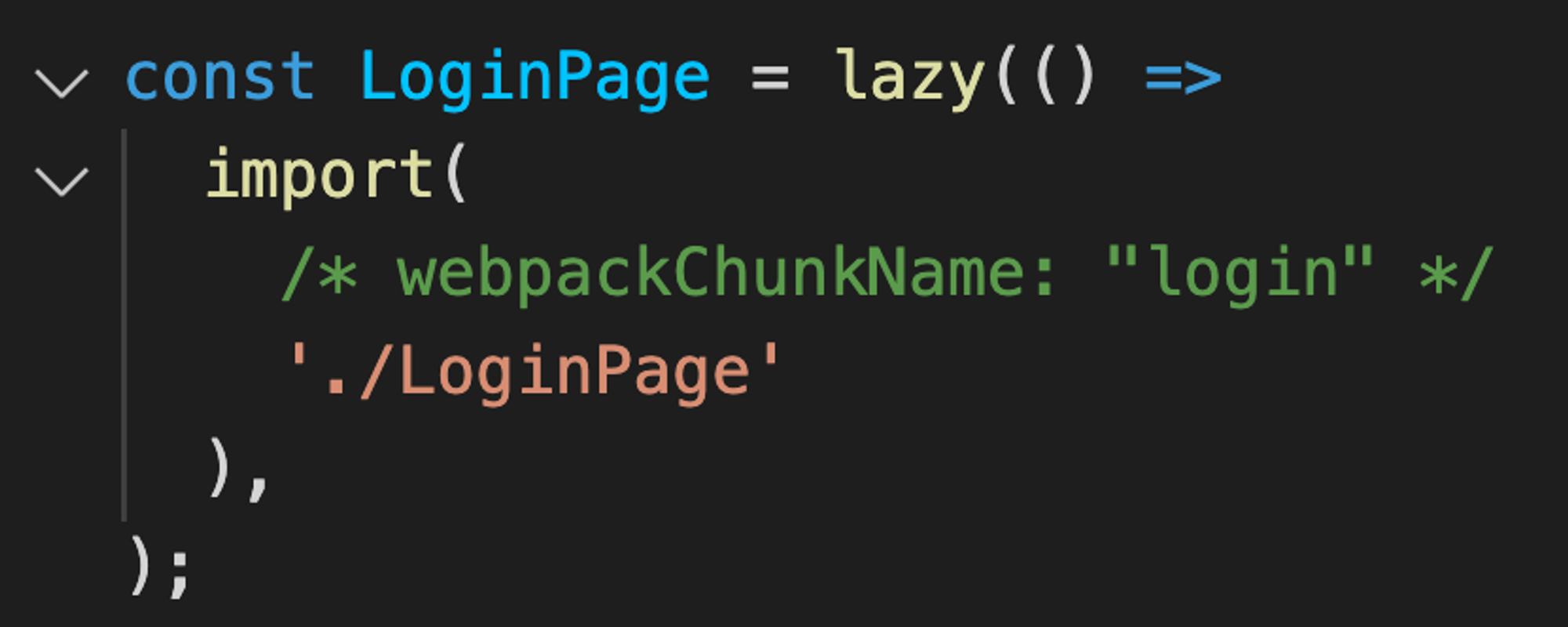
Дать файлам чанков человеко-читаемые имена поможет волшебный комментарий для вебпака:
Хорошим способом сократить объем кода, скачиваемого при первой загрузке React приложения, будет импортировать с lazy() все компоненты, с которыми пользователь не взаимодействует сразу: модалки, скрытые компоненты, и подобное.
Некоторые npm пакеты могут существенно увеличить объем бандла кодом, который никогда не будет использован. Например, moment.js по-умолчанию включает все возможные локали, а lodash — все хелперы.
Исключить лишние локали из moment.js можно через moment-locales-webpack-plugin,
github.com/iamakulov/mome…, IgnorePlugin или ContextReplacementPlugin github.com/jmblog/how-to-…
Про загрузку только необходимых функций lodash, можно почитать тут: azavea.com/blog/2019/03/0…
Про загрузку, отрисовку и взаимодейстивие со страницей продолжу завтра
Суббота
Про загрузку и отрисовку страницы:
Чтобы разобраться в том, как оптимизировать отрисовку, нужно понимать, как браузер рендерит страницу.
Пара ссылок:
1)developers.google.com/web/fundamenta…,
2)medium.com/jspoint/how-th…
Блокируют отрисовку страницы:
- Стили, подключенные без атрибута media,
- стили, подключенные с атрибутом media, который совпадает с текущими параметрами устройства,
- скрипты без атрибута async/defer.
Стили и скрипты будут загружены, даже если они не блокируют отрисовку.
Чтобы немного упростить браузеру задачу отрисовки:
- разделите CSS на файлы так, чтобы один файл — один media query (плагин: npmjs.com/package/postcs…),
- подключайте скрипты с async/defer, и проверяйте в них событие DOMContentLoaded
Пользователь, заходя на страницу, видит только какую-то её часть. Важно сделать так, чтобы эта видимая часть отобразилась как можно быстрее. Для этого можно выделить стили, необходимые для отрисовки первого экрана, и заинлайнить их. Плагин для вебпака:
github.com/GoogleChromeLa…
Применение critical css позитивно скажется на метриках, например, Largest contentful paint
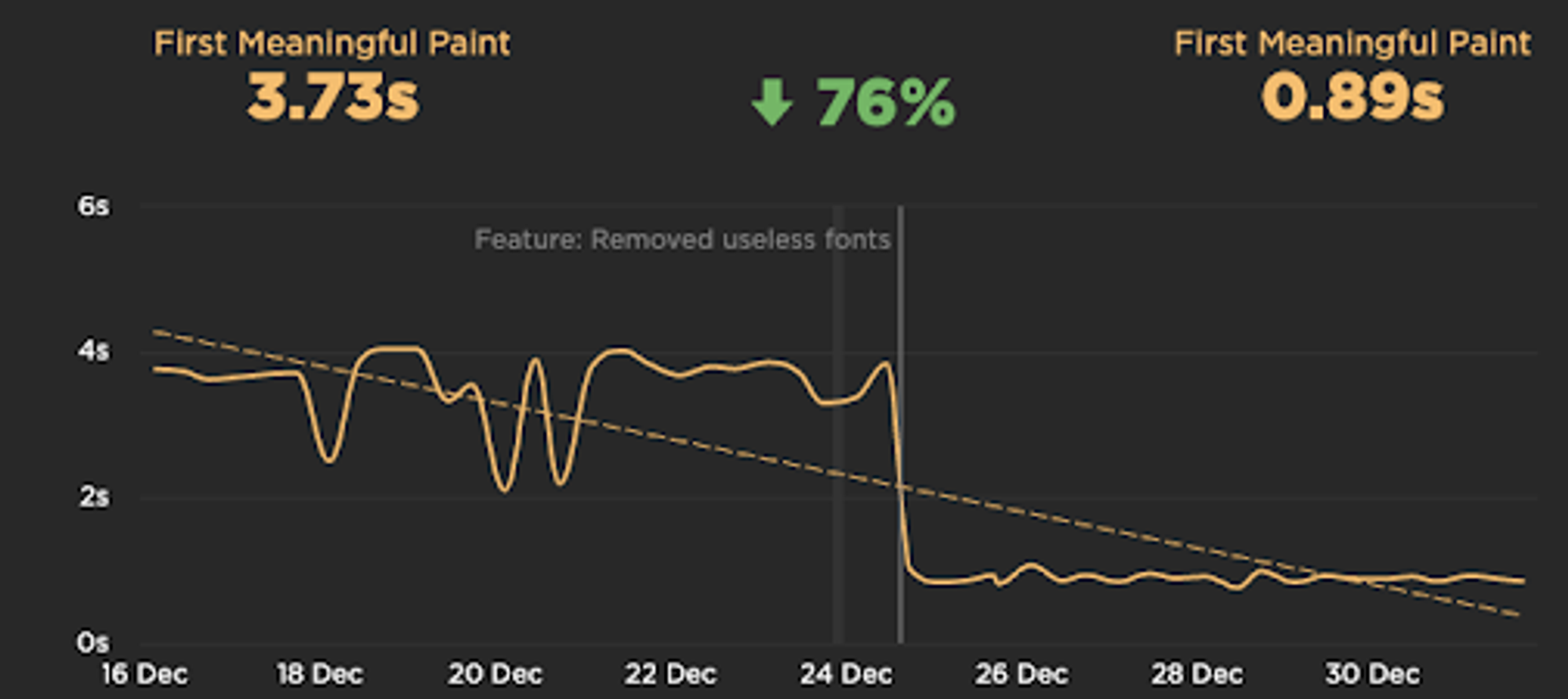
На контентные метрики (Largest contentful paint / First meaningful paint) влияет и то, как подключаются и используются шрифты.
Мы однажды обнаружили, что на одном из сервисов загружался, но не использовался, кастомный шрифт. После его удаления, метрика FMP улучшилась на 76%!
Ещё немного про шрифты:
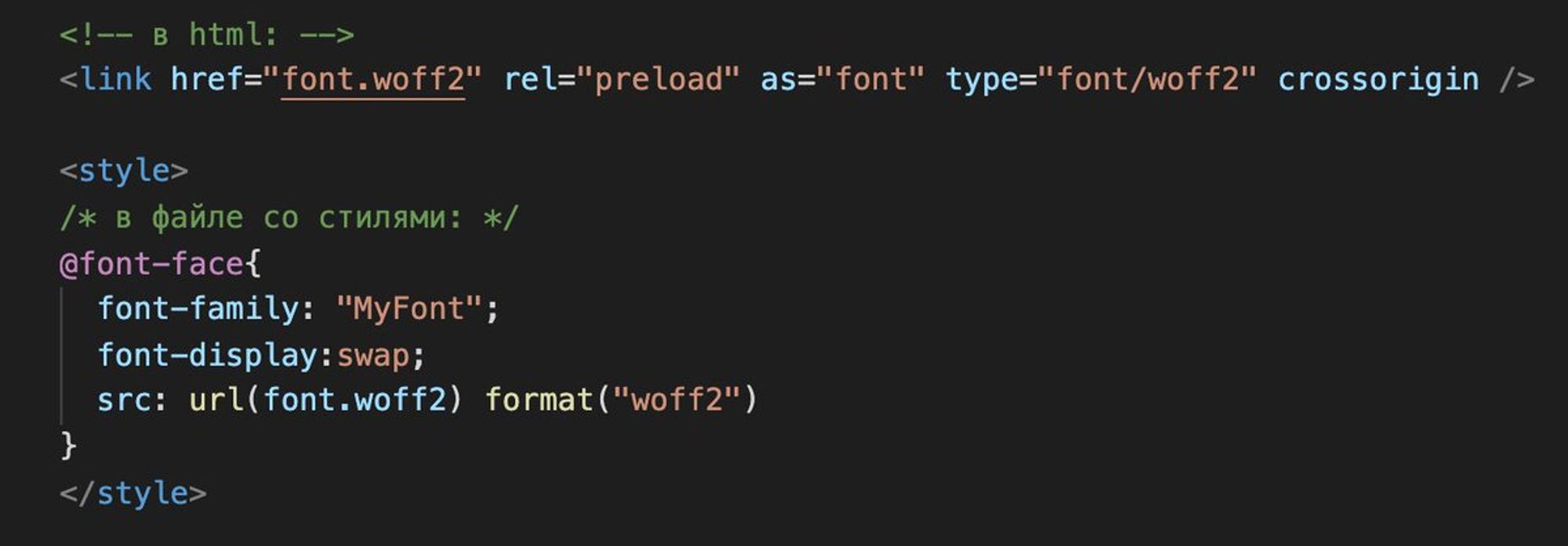
- формата woff2 достаточно в большинстве случаев (caniuse.com/?search=woff2);
- подключайте шрифт с preload;
- используйте font-display: swap;
Про изображения:
- указывайте width/height, так браузер заранее зарезервирует место для картинок
- для контентных картинок — атрибут loading="lazy" (caniuse.com/loading-lazy-a…) для нативной загрузки по скроллу (полифил: github.com/mfranzke/loadi…)
Для контентных картинок можно использовать тег picture (developer.mozilla.org/en-US/docs/Web…), чтобы, например, загружать более легкие изображения на маленьких экранах. Плагин: responsive-loader (npmjs.com/package/respon…).
Совет от кэпа: убедитесь, что картинки минимизованы и имеют адекватные размеры! Особенно, если картинки могут загружать пользователи. В одном нашем сервисе мы сэкономили 10мб просто на том, что привели изображения к ширине 1024px и качеству 85% ¯_(ツ)_/¯
Воскресенье
Кулстори про клиентский и серверный рендеринг. Есть мнение, что рендерить страницу на сервере быстрее, чем на клиенте. Поэтому мы выпилили реакт на одной из статичных страниц, и переписали её на чистом html, который собирается через Django на бэке (Django там уже был) ->
Постепенно к странице появлялись всё новые требования: сначала кастомизации в зависимости от тарифного плана и страны пользователя, а через год — от нескольких десятков параметров. Настройки делали на бэке условиями в темплейте, в итоге time to first byte составил 2 сек
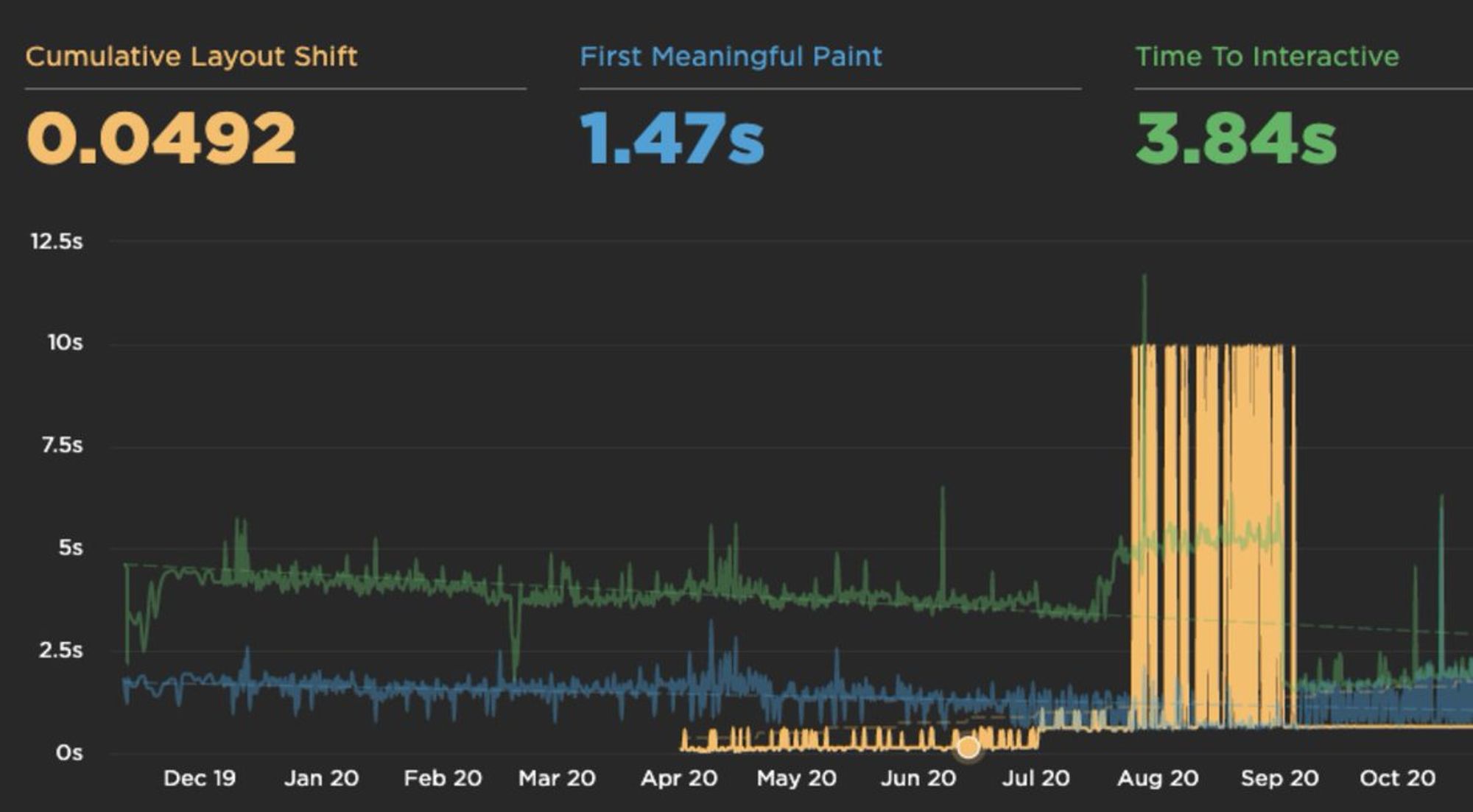
Поддерживать это стало очень сложно, решили снова переписать на реакте. Страница стала отдаваться за 200мс, но выросли TTI и CLS (август-сентябрь на графике):
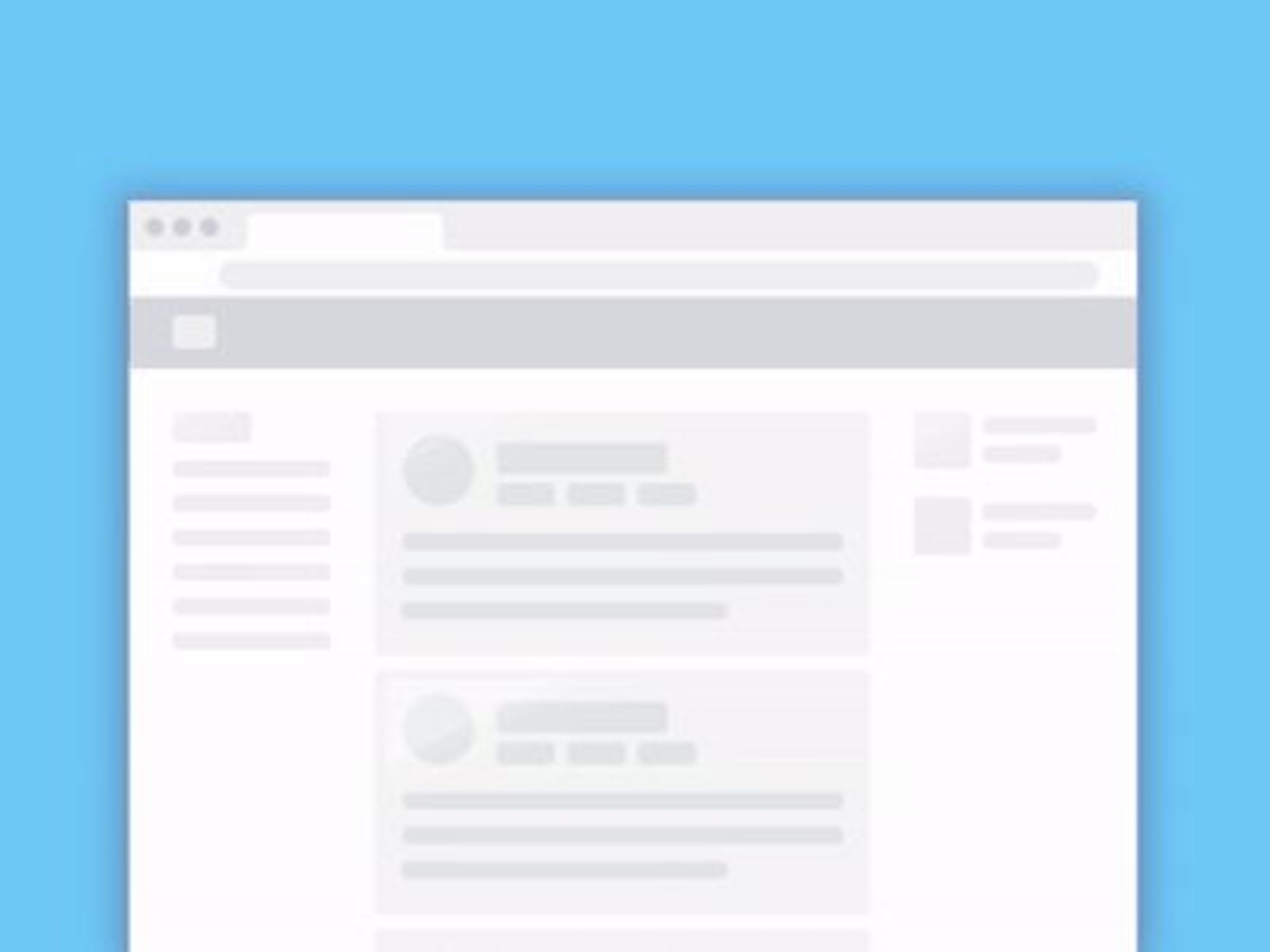
Тогда придумали к̶о̶с̶т̶ы̶л̶ь изящное решение: для видимой части сверстали скелетон (штуку как на картинке) и заинлайнили его стили в <style>. Поместили этот код внутри тега, куда рендерится реакт, чтобы он заменялся на реактом на готовую страницу с контентом.
Если нужно передать через шаблон данные с сервера на клиент (например, initial state для redux store), лучше завернуть их в JSON.parse(), так браузер сможет распарсить их быстрее, и это тоже улучшит TTI:
joreteg.com/blog/improving…
Про взаимодействие и UX.
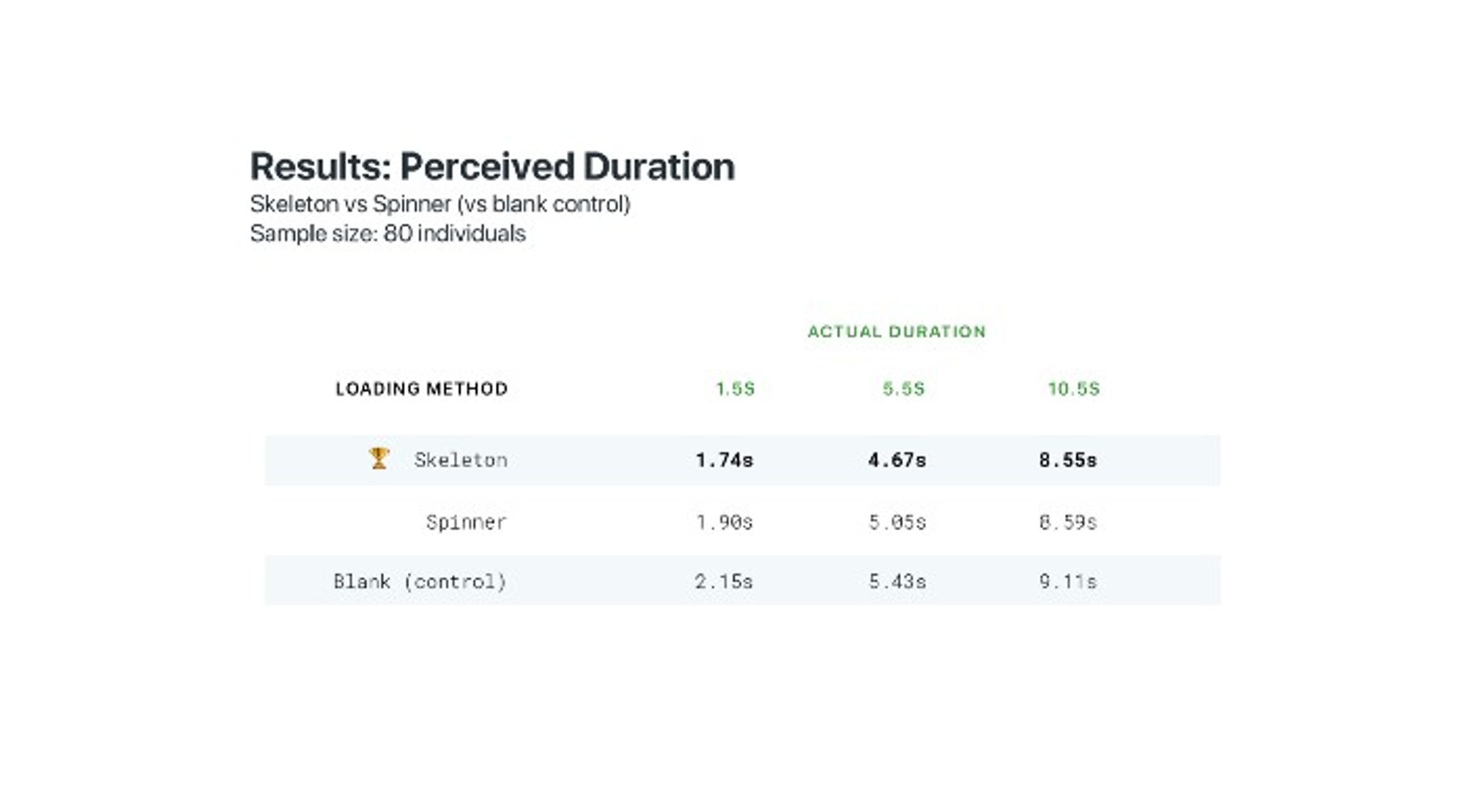
Если использовать скелетон, а не спиннер, то пользователям кажется, что страница загружается быстрее:
uxdesign.cc/what-you-shoul…
Полезно изучить, как пользователи переходят по страницам сайта, и использовать это знание для предварительной загрузки ресурсов. Допустим, с главной 80% идут на регистрацию, тогда можно заранее загрузить ресурсы и в фоне отрендерить эту страницу.
caniuse.com/link-rel-prere…

С rel="prerender" нужно работать осторожно, так как это ускоряет следующую страницу для части пользователей за счёт загрузки доп ресурсов на текущей для всех. Не рекомендуется делать более одной ссылки с rel="prerender" на странице.
Используюя rel="preload" можно скачать и закешировать ресурсы, которые скоро понадобятся. В отличие от rel="prerender", они не будут исполнены (только скачаются).
caniuse.com/link-rel-prelo…

Guess.js — экспериментальная библиотека, которая на основе данных гугл-аналитики предсказывает, на какую страницу дальше пойдёт пользователь, и динамически делает prerender/preload.
github.com/guess-js/guess
Для Webpack есть preload-webpack-plugin, он решает проблему добавления ссылок на ресурсы с хешем в имени:
npmjs.com/package/@vue/p…
Совсем немного про отзывчивость интерфейса:
Если в течение ~100мс после действия (клик по кнопке, нажатие на меню, фокусировка в инпуте и начало ввода текста и тд) пользователь не получил визуального подтверждения, ему кажется, что интерфейс тормозит
Поэтому важно не блокировать интерфейс при выполнении запросов к API и других операциях, и максимально быстро показать, что что-то произошло.
Есть паттерн Optimistic UI, согласно которому предполагается, что операция завершилась успехом, и показывает результат сразу по взаимодействию, ещё до того, как выполнен запрос/пришли данные. uxplanet.org/optimistic-100…
Особенно хорошо такой подход работает в случае с атомарными независимыми друг от друга операциями
Как реализовать Optimistic UI с Apollo GraphQL:
apollographql.com/docs/react/per…
Как реализовать Optimistic UI с React Query:
react-query.tanstack.com/guides/optimis…
Тред (@ierhyna)
С вами была Ирина Соколовская, и моя неделя в этом аккаунте подошла к концу. Вы классные, мне было с вами интересно, надеюсь и вам со мной тоже :)
Мой личный твиттер: @ierhyna
В реплаях соберу тред тредов из всего, о чем рассказала на этой неделе.
Давайте для начала познакомимся, сегодня расскажу немного о себе и своём пути в разработке.
О себе: twitter.com/jsunderhood/st…
Доброе утро! В ближайшие три дня планирую рассказать: - о метриках webperf: как замерить, насколько приложение быстрое? - как ускорить приложение и улучшить метрики? - о процессах работы над производительностью у нас в компании.
Опросы о том, насколько аудитория андерхуда знакома с темой веб-производительности:
twitter.com/jsunderhood/st…
Первая тема — о метриках web performance. Как замерить, насколько приложение быстрое, какие для этого существуют метрики и инструменты.
О метриках и инструментах:
twitter.com/jsunderhood/st…
Привет! Сегодня расскажу о том, как устроены процессы работы над web perf у нас в компании.
О процессах работы над производительностью в компании:
twitter.com/jsunderhood/st…
Привет! Сегодня поговорим про оптимизации, что влияет на метрики, расскажу про best practices и случаи из жизни :)
Оптимизации, лучшие практики, истории:
twitter.com/jsunderhood/st…
Тред (@ierhyna)




















