
Привет! Сегодня расскажу о том, как устроены процессы работы над web perf у нас в компании.
Немного контекста. В Semrush много (30-40?) кроссфункциональных команд разработки, и каждая полностью отвечает за свой продукт: выбирает стек технологий, решает, какие фичи должны быть, в каком порядке и как их делать.
И есть инфраструктурная команда, которая делает интеграционный сервис с общими частями интерфейса и API, куда все остальные команды встраивают свои SPA.
Отсюда следуют несколько особенностей:
Стек технологий у всех команд очень разный. Пожалуй, общее только то, что фронте почти у всех TS + React (потому что у нас собственный UI Kit для него). Остальные библиотеки могут быть любыми. А на бэкенде вообще что угодно: php, node.js, go, java, c++.
Это, с одной стороны, повышает вовлеченность команд в их работу (многих мотивирует то, что они сами принимают решения по технологиям и могут пробовать новое), но с другой — создаёт некоторые сложности в выработке общих решений и подходов к производительности.
Для принятия решений, которые будут влиять на работу многих команд, создаются рабочие группы из заинтересованных участников. Так, есть рабочая группа по веб-производительности в разработке, унификации UI у дизайнеров, и другие
Так как команда саа принимает решения по своему продукту, мы, как рабочая группа по webperf, не можем "заставить" их что-то делать. Скорее рекомендуем и рассказываем, как сделать лучше. Но за полтора года я не помню случая, когда кто-то отказывался следовать рекомендациям
Еще одна особенность, вызванная архитектурой, где много SPA встраиваются в общий сервис — при переходе по меню, пользователь скачивает заново все ресурсы для каждого SPA, в том числе общие (UI kit, React&co).
До того, как мы начали заниматься улучшением скорости загрузки и оптимизировать размеры бандлов, типична была ситуация, когда за получасовой сеанс работы, выполняя свои ежедневные задачи, пользователь скачивал 200mb JS файлов, и пять минут смотрел на спиннеры.
Когда мы решили заняться оптимизациями веб-производительности, основными задачами стали:
- выбрать метрики и их значения
- каким инструментом их мониторить
- какие продукты нужно оптимизировать в первую очередь
- найти решения, которые помогут всем командам
Список метрик мы определили исходя из типа приложения: для статичных страниц и для SPA.
Для статичных страниц отслеживаем:
- Time to First Byte,
- Largest Contentful Paint,
- Cumulative Layout Shift,
- Time to Interactive,
- Total Blocking Time,
Раньше в этом списке была Visually Complete, но потом мы её исключили.
Для SPA метрики те же, и дополнительно отслеживаем собственную метрику First App Render, которая показывает в секундах первый рендер, совершенный из SPA.
Значения метрик мы выбирали, основываясь на:
- попадание в нижнюю границу зеленой зоны Lighthouse
- их достижимость
- анализ этих метрик в приложениях конкурентов
Список метрик и их значений общеизвестен в компании, хранится в Confuence, и при необходимости обновляется.
Также есть рекомендации по размерам JS/CSS-бандлов, их значения тоже немного отличаются для статичных станиц и для SPA.
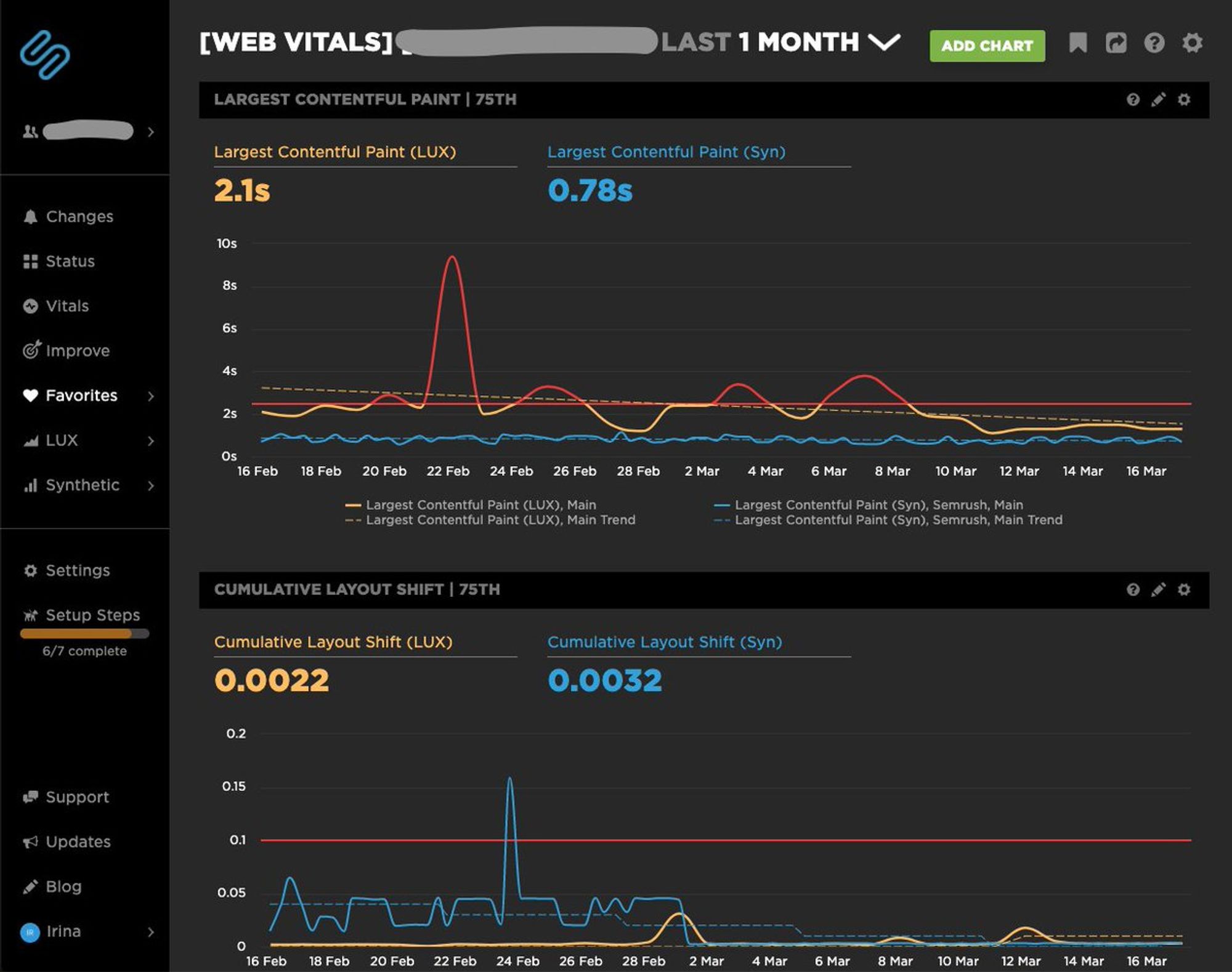
При выборе инструмента мониторинга ориентировались на возможности создать "спейс" для каждой из команд разработки, разграничения доступа, гибкость настройки, цену, и другие критерии. Остановились на SpeedCurve. К сожалению, не знаю, какие варианты ещё рассматривались.
Через SpeedCurve мониторим как синтетические метрики (lab tests несколько раз в день), так и снимаем данные по производительности с реальных пользователей.
Для каждой команды разработки настроен свой спейс с дашбордами (по дашборду на каждый продукт команды), на которых выведены обязательные для отслеживания метрики. Ребята могут при необходимости сами добавлять новые дашборды и выводить на них другие метрики, если считают нужным
Если по какой-то метрике произошло превышение допустимого значения, об этом приходит уведомление в Slack команде.
Приложения, которые нужно оптимизировать в первую очередь, выбрали количеству трафика и критичности для пользователей. В этот список попали большинство публичных страниц, логин-регистрация, и несколько SPA.
С командами, отвечающими за эти сервисами, вели точечную работу:
- Проводили фронтенд-аудит производительности страницы или приложения,
- по итогам составляли список рекомендаций и улучшений,
- передавали список команде, отвечали на вопросы,
- через 3 месяца проверяли повторно
Это дало неожиданный эффект, некоторые команды, у которых ещё не был запланирован webperf-аудит, сами находили проблемы в своём продукте и чинили их :)
В течение года, мы провели аудиты примерно 20 команд, и поняли, что дальше продолжать не очень эффективно — в приложения добавляются новые фичи, и нужно повышать знания разработчиков и сделать так, чтобы забота о производительности стала частью процесса их работы
Теперь делаем аудит по запросу от команд, чаще всего это бывает перед выходом нового продукта в продакшен.
Если у вас похожая ситуация, то полезным может быть выделить самый распространенный user flow, понять, какие продукты пользователь встречает выполняя ежедневные задачи, и сфокусироваться на их оптимизиции.
Оказалось, что многие проблемы общие у разных команд/продуктов, и можно создать единый список рекомендаций, best practices, и даже примеров кода, которые улучшают производительность
Про рекомендации, случаи из практики, best practices, планирую рассказать завтра и послезавтра
Попросили показать, как выглядят дашборды. Показываю :) Красная горизонтальная линия — отметка на которой происходит алертинг.
 Ирина Соколовская
Ирина Соколовская