

Расскажу немного про GraphQL. Вы наверняка уже слышали про эту технологию, но как и в докладах, я люблю почитать какие-то реальные истории об использовании, чем абстрактные рассказы, поэтому расскажу про наш опыт. Почему мы выбрали GraphQL, как это работает, какие профиты даёт
Сразу оговорюсь, что это мой личный опыт и наблюдения, в некоторые вещи я не успел погрузиться достаточно глубоко, могу иногда нести чушь на взгляд graphql-гуру
Некоторые считают, что GraphQL это что-то типа запросил с клиента всё что хочешь, сервер вытащил всё из базы и погнали. На самом деле не совсем так. Запросить можно только то и так, как вы это сделали
У нас на бэкенде микросервисная архитектура, у каждого микросервиса своя зона ответственности, например один отвечает за пользователей, другой за депо, третий за автобусы и т.д. Как правило они не связаны, и максимум что у нас есть это ID какой-то связанной сущности
Так же мы предпочитаем разделять фронтенд на API и клиентскую часть. Во-первых чтобы не мешать мух и котлеты, а во-вторых этим API могут воспользоваться другие сервисы и мы сразу закладываем это при разработке
По сути всё просто — клиентское приложение идёт в API за данными, API через клиент (рассказывал вчера) идёт в микросервис, агрегирует и возвращает данные, плюс содержит некоторую логику
До этого у нас было одно API на Nest — куча контроллеров, там же проверка доступов, там же некоторая логика. Нам приходилось внедрять в запросы параметры типа includes чтобы по запросу доставать дополнительные данные,отсутствовала какая-либо синхронизация с клиентским приложением
Мы так жили, но было некомфортно. Кстати про то, как мы сделали систему контроля доступа через рефлексию в TypeScript я делал доклад на прошлой Холи. Если не слышали про рефлексию в TS — советую посмотреть youtube.com/watch?v=sjtQyr…
Когда нам понадобилось сделать новое API для нового проекта, мы примерно прикинули схему сущностей, написали в голове несколько сотен методов nest-контроллеров, и загрустили. В этот момент нам пришла идея попробовать GraphQL
Нам казалось, что он удовлетворяет многим нашим потребностям — легко запрашивать только необходимое, получение связанных сущностей, отсутствие отдельного метода контроллера на каждый чих. Мы решили рискнуть
У меня такого опыта не было вообще не считая прекрасных докладов от @nodkz youtube.com/results?search…, а у моего коллеги был, но небольшой. И мы начали делать MVP
Первый выбор который перед нами встал — какие библиотеки использовать. Я пересмотрел пару докладов от Павла, вспомнил наши разговоры на HolyJS и предложил Apollo apollographql.com
На сколько я понимаю, серверная часть может быть практически любой. Можно написать свою, можно взять какую-то из готовых, мы решили выбрать и на клиенте и на сервере Apollo, т.к. он более близок к сообществу и лучше развивается, чем тот же Relay, хоть и уступает ему иногда
Серверное приложение с GraphQL можно писать минимум двумя способами — schema first и code first, можно даже совмещать их. В первом случае чтобы описать сущности вы пишете в специальном синтаксисе типизированную graphql-схему типа такой (картинка из интернета)

Во втором случае, вы описываете все сущности как классы в nodejs, берёте type-graphql в помощь, можете навешивать валидации из возможно привычного вам class-validator, и т.д.
Мы начали со schema first, код конечно всё равно нужно было писать (описывать связи между сущностями), и честно говоря мне этот подход нравился больше, но в итоге мы перешли на code first для большей гибкости. Выглядит это примерно вот так
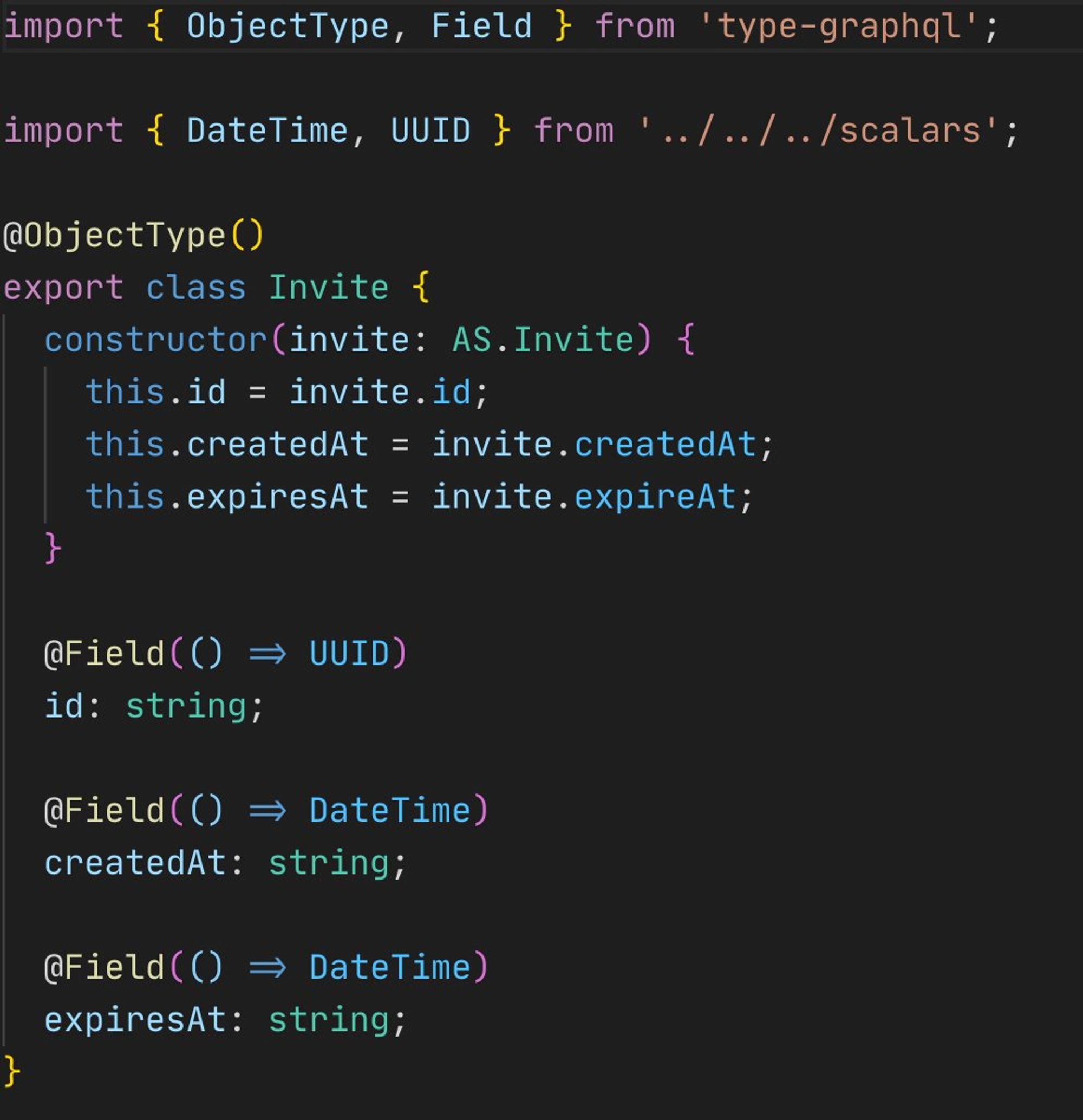
Связи тоже описываются довольно просто. У сущности вы описываете поле методом класса, внутри функции которого делаете запрос за связанной сущностью. Нужно только не забывать использовать DataLoader’ы чтобы не генерировать лишние запросы на бэкенд
Я пока немного поработаю. Если у вас есть вопросы — с удовольствием отвечу. Чуть позже продолжу про клиентскую часть, кодогенерацию, синхронизацию между API и клиентской частью, и возможно что-то ещё
Так же с Apollo Server идёт удобная тулза, которая содержит всю документацию, все связи в удобном виде, все ваши схемы, и песочницу с валидацией для выполнения запросов
Возможно я иду немного поверхностно. Если хотите каких-то более глубоких подробностей — дайте пожалуйста знать)
Погнали дальше. Как я говорил для сервера мы выбрали Apollo Server, соответственно на клиенте мы решили взять Apollo Client (AC для краткости)
Через AC можно делать запросы на сервер, кэшировать данные (например вы переключаетесь между страницами и второй раз запрос не выполнится — это настраивается)
Так же он позволяет делать optimistic UI, например вы отправили формочку создания пользователя, эти данные сразу подпихнули в кэш и уже можете его показать. Дальше можно перезапросить эти данные, чтобы всё было совсем консистентно
С AC вам по сути не нужен стейт-менеджер. Более того, его использование не рекомендуется. Я уже год не видел Redux и очень этому рад.
Так же AC поставляет react-HOC’и для староверов и hook’и для модных ребят. Работают они примерно одинаково, я буду рассказывать в контексте хуков
Хук useQuery через который вы делаете запрос на ваш сервер, подставляя туда собственно graphql query и переменные при необходимости, предоставляет вам кучу всего полезного apollographql.com/docs/react/dat…

Собственно сами данные, ошибки, признак того что запрос выполняется, функцию для перезапроса данных и пагинации, возможность включать/выключать перезапросы по таймеру и другие полезные штуки. Так же можно описать события типа onCompleted
Так же есть его аналог useLazyQuery чтобы вы могли делать запрос не при рендере, а по нужным вам условиям.
В итоге, всё довольно сильно упрощается — берёте ваш умный компонент, в нём вызываете useQuery, берёте эти данные, показываете их — profit! Но и это ещё недостаточно хорошо
Всем же нам хочется сделать запрос в API с теми параметрами, которые оно действительно принимает, и точно знать что мы оттуда получим и будем использовать. Для этого есть отличная тулза graphql-code-generator (зацените сайт) graphql-code-generator.com
Чтобы совсем автоматизировать процесс мы при старте приложения идём через тулзу graphqurl в наше API по http, забираем схему и скармливаем её в codegen, который для каждого компонента где у нас есть запросы генерирует специальные хуки на основе useQuery, полностью типизированные
После этого, в коде мы вызываем что-то вроде useGetUsers() или useGetUser({variables: {id: '123'}}) и получаем наших пользователей типизированных так же как в API
Что мы получили в итоге? В API описываем только сущности и их связи, на клиенте только то что мы хотим запросить, стартуем приложение и получаем типизированные хуки с типизированными запросами и ответами которые супер удобно использовать, но давайте и о недостатках тоже поговорим
Из того что я заметил на текущей версии AC (говорят часть из этого уже стала удобнее):
Не очень удобная ручная работа с кэшом. Чтобы после запроса его оптимистично обновить, нужно писать примерно такую балалайку со всей структурой
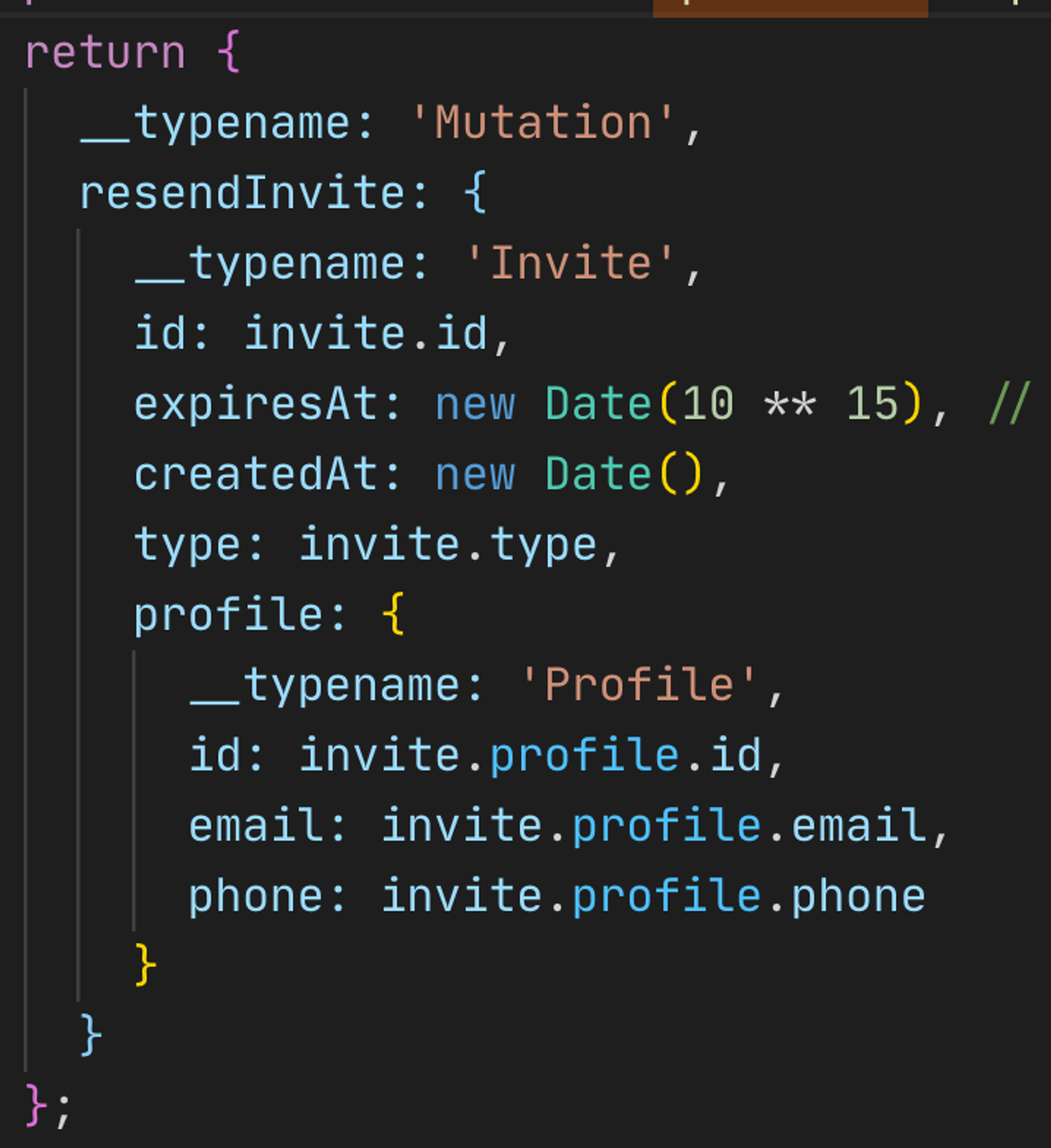
Похожая ситуация с пагинацией. С одной стороны удобно, с другой — вам нужно в специальном методе updateQuery самому смёржить данные и вернуть их. Звучит вроде логично, пагинация всегда разная, но мне кажется можно было придумать решение изящнее
Типы из вашего API это не совсем те типы, которые вы получите. Тип ответа от apollo-server будут содержать ещё некоторую информацию, другие (но такие же) енамы. Вам скорее всего придётся научиться с этим жить (мы вроде научились)
Так же, т.к. apollo матчит данные с кэшом по двум полям: id и __typename, вы всегда должны запрашивать сущность с её id, иначе при обновлении кэша стрельните себе в ногу
Например, вы переполучили данные, apollo пытается положить их в кэш, они там уже есть, пытается их смержить, но безуспешно. Если вы явно не обработали ошибку, есть вероятность увидеть white page и долго думать
Так же, вам нужно научиться корректно обрабатывать массивы ошибок от сервера. Мы пока не дошли до этого, поэтому показываем стрёмный ответ. Уверен, какое-то решение есть, возможно у каждого своё
Если вы используете (по-умолчанию) включенный кэш всех запросов, есть вариант забыть где-то что-то обновить и получить неконсистентное состояние. Мы решили по-умолчанию этот кэш выключить и возможно включать для отдельных запросов. Пока не болит
Так же, внезапно вы можете получить ситуацию, когда на одну страницу у вас будет скажем 15 запросов вместо 3. Забыли где-то DataLoader или ещё что-то, поэтому мы в dev-окружении всегда выводим небольшие попапы с количеством запросов
На этом пока кажется всё. Решайте сами стоит ли оно того. Лично для меня — 100% стоит. Удоство использования на высоте, синхронизация с API, много всего из коробки, всё типизировано. Приятно разрабатывать такие приложения