

🧑🔬 Ревёрс-инжиниринг медленного Твиттера
Так получилось, что Твиттер в этой стране работает не шустро.
Давайте представим, что мы в штате и должны предложить решения этой проблемы.
Q–Как инженеры Твиттера могут решить сетевые проблемы сервиса в этой стране?
A–Никак.
Это логично, ведь проблема по другую сторону их штаб-квартиры. Где-то на магистрали до Франкфуртского CDN, который и отдаёт нам статику.
Возможно, команда Твиттера вообще ничего не делала. Но я в это не особо верю, так как отдел мониторинга привык видеть «пики» на графике TTI, а вот к иллюстрации комбинаторного взрыва на графиках 10 марта они точно не были готовы.
На всём пути инвестигации нам потребуется только вкладка «Network» в «DevTools», терминал и понимание работы сети.
Кстати, проверить фундаментальные знания оппонента о работе сети можно прямо на этом инфоповоде.
Если собеседник считает, что технически заблокировать Твиттер сложно и шутит отсылками к инциденту с Телеграмм, то… ему есть повод освежить знания о (де)централизованных сетях.
В случае споров — напомните историю с LinkedIn.
Если же услышите «ты не понимаешь, это другое!», то просто извинитесь.
Начнём с того, что конкретно я не могу гарантировать технику, которая инкапсулирована в осуществление троттлинга запросов к Твиттеру. Есть ряд вариантов, которые внешне похожи.
Да и мне не особо интересна истина от первоисточника. Я хочу в ревёрс-инжиниринг.
Приступим.
Собственно, если полазить по Твиттеру, то всё кроме картинок и первых экранов выглядит шустрым, если не заострять внимание. Даже через день.
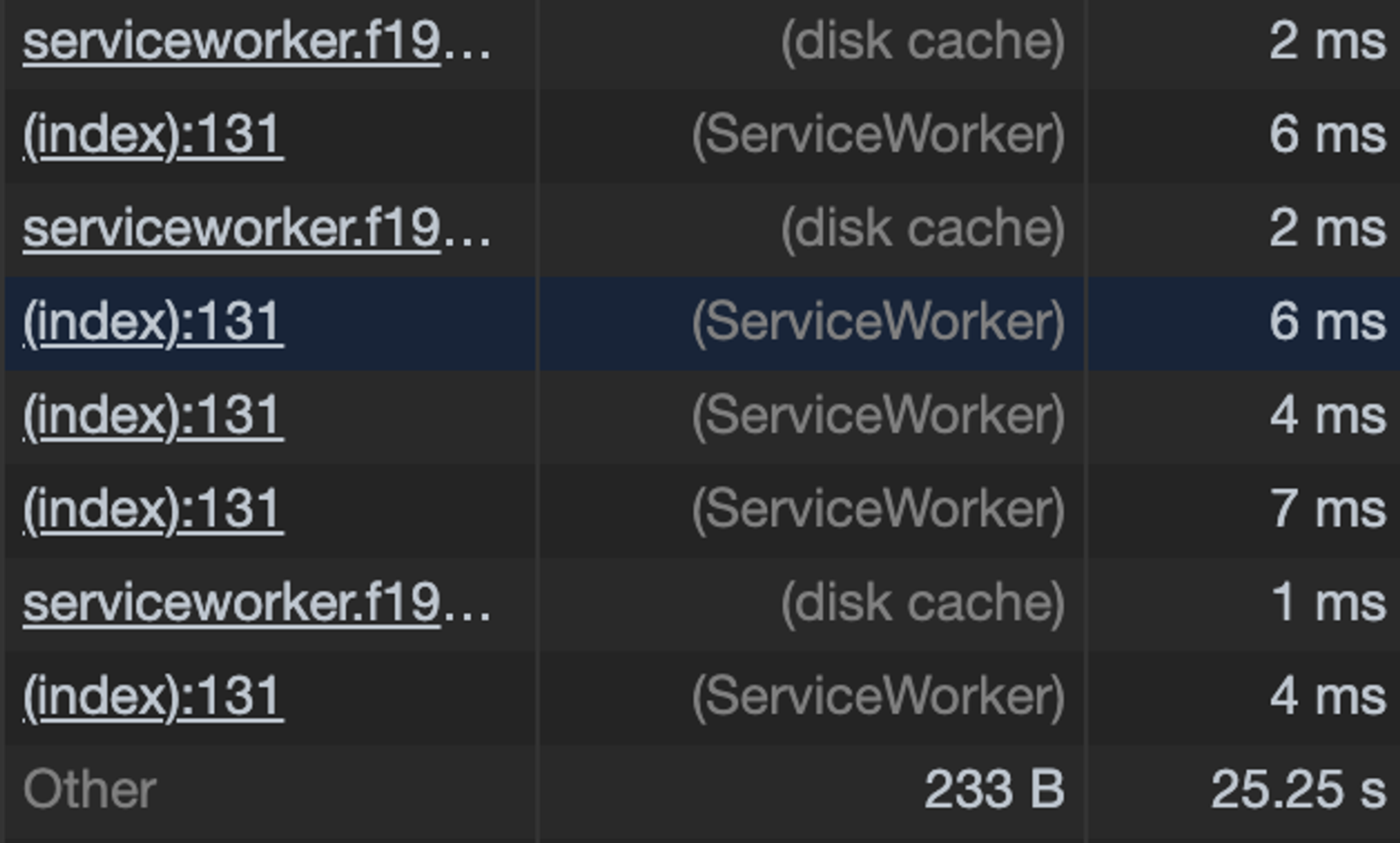
Открываем «F12» > «Network» и пролистав колонку «Size» видим, что статика закэширована на диске или в Service Worker.
Это отголосок грамотного агрессивного кэширования. 🙂
Вам пишу «F12», сам нажимаю «Cmd+Option+I», а думаю вообще про «DevTools»...
То есть, пара принципов агрессивного кэширования:
весомую, редко меняющуюся статику и «скелет» приложения поместили в «Service Worker».
у остальной статики — как можно реже менять хэш в имени файла и выставить долгие сроки «протухания» (в серверных заголовках).
Для потенциально изменчивых ассетов это даёт непрятный эффект. Пример с аватаром...
Вы: загрузили аватар и обновили страницу
Твиттер: мгновенно отображает старый аватар и... секунд 5 загружает новый.
Так себе UX. И парировать это поведение — затратно.
Это поведение можно переложить и на CSS.
Так что, keep in mind.
А про ETag сегодня кто-нибудь помнит ещё? 🧐
В погоне за неизменчивыми хэшами в файлах можно взять и сделать из 100 модулей, например, 1000.
Тогда эта «оптимизация» даст сбой, и увеличится и время загрузки и TTI, соответственно.
Ref: nolanlawson.com/2016/08/15/the…
Переводя зарубежный мем, получим формулу: «Чем больше вы модуляризируете приложение, тем больше оно становится».
В довесок, может быть, и выкатывают релизы теперь пореже. Эдакая параллель с LTSB-веткой Windows – черри-пикают только критично-важные патчи из основной ветки приложения.
Ветка, наверное, называется в стиле:
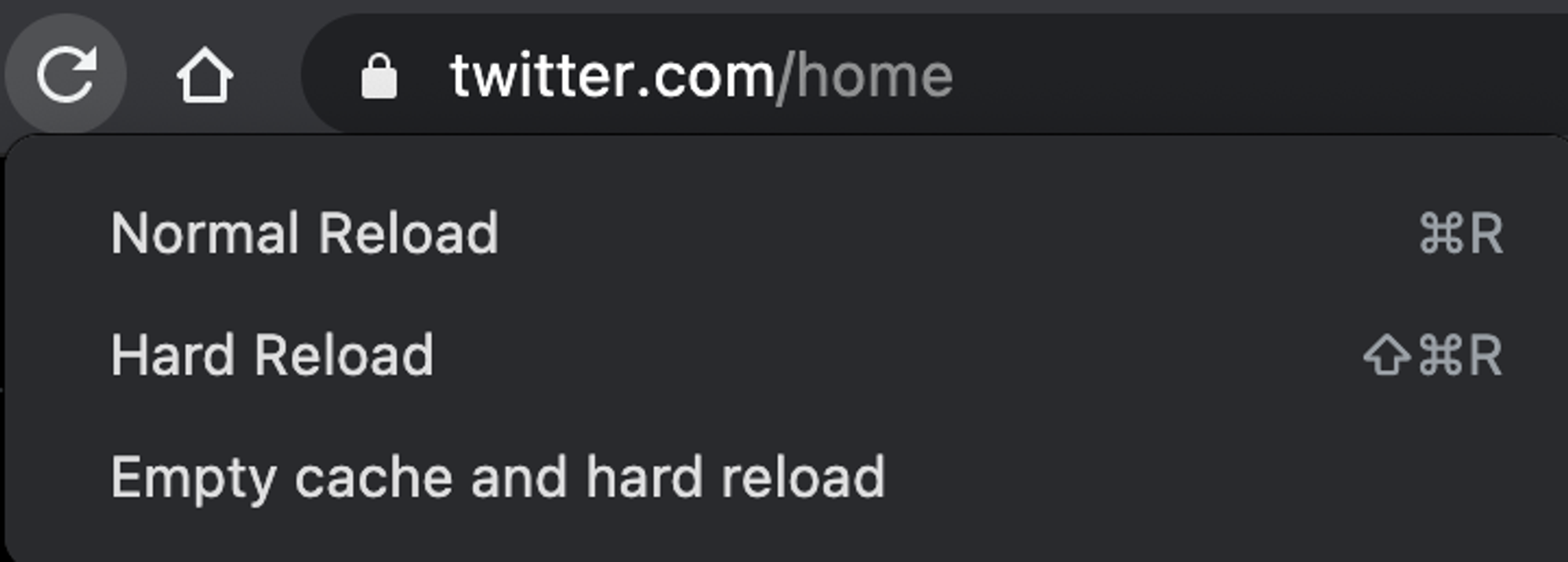
delete-after-a-monthА теперь, оставаясь в «DevTools» > «Network» сбросим кэш и жёстко перезагрузим страницу. Для этого — зажмите кнопку перезагрузки страницы и подождите секунду.
Собственно, после перезагрузки страницы тормозят все запросы: от Initial (где мы получаем HTML) до API вообще на другой хост.
Выполним десяток-другой замеров и посмотрим на корреляцию показаний...
Характер тормозов один и тот же — очень долгий TTFB и Content Download.
Похоже, что хотя бы потери пакетов нет.

Иначе, будь там PLR, тайминги загрузки для одного и того же ассета были бы разрозненные.
В стиле, что каждый 3-ий раз есть сильное отклонение от медианы.
Это уже флуктуацией не назовёшь.
Чтож. Перепроверим мои «теории» инструментами. Выполнив сотни тестов и попыток хоть как-то определить, что теряются пакеты... и я вижу, что нет, не теряются. Либо совсем в ничтожном количестве.
Да и вряд ли я теоретик... ибо не пишу на Coq.
Так почему потеря пакетов — это важно?
Потому что есть вариант переключить протокол CDN на HTTP/1.1 + доменное шардирование.
Я не прикалываюсь. И вот почему...
Дело в том, что H1 куда более устойчив к PLR (Packet Loss Rate), в отличии от H2.
TL;DR - Всё дело во внутреннем устройстве протокола.
Хотите разобраться? Пожалуйста: vimeo.com/190932569
Доменное шардирование в 2k21…
Кстати, вспоминается та шутка про UDP, которая обычно не д
Разумеется, подобного рода «спорные» решения не должны приниматься чисто на авторитете.
Это как в Data Science полагаться на эзотерику.
Для гипотез есть АБ-тесты.
Есть гипотеза по переходу с H2 на H1 для RU-региона?
Значит, её стоит подвергнуть АБ-тесту, где А-группа на H1, а Б - на H2.
Цифры не соврут.
Разумеется, Твиттер использует HTTP/2 для статики. Ведь этот протокол был заточен и под медиа-контент. Но есть проблема — чувствительность к PLR, что особенно актуально для мобильного интернета.
Будь Твиттер на HTTP/1.1, то в четверг сюда можно было бы тупо не заходить.
Резюмируем.
Инженеры твиттера применили:
- агрессивное кэширование посредством SW и серверных заголовков
- возможно, увеличили релизный цикл
- не переключилисьна протокол H1
Собственно, против топорного троттлинга\сужения канала, были применены такие же деревянные методы.
Послесловие:
Острых проблем с «Percieved Performance» в Твиттере не наблюдается, поэтому я их и не упоминаю. Они нивелируют на фоне проблем с сетью.
Виден инженерный подход 🥲
И это всё?
Да. Ибо продолжать генерировать нерентабельные варианты — странная затея, чтобы набрать классы.
Например:
- жать изображения в AVIF «на лету»
- понаделать скелетонов на все типы контента
- пробрасывать заблюренное изображение, а не его доминантный цвет
- ...
Неважно. Это нерентабельно. Инженер должен смотреть на проблему шире и оценивать не только пользу, но и затраты.