Архив недели @belov
Понедельник
Привет!
Я — Артём @belov, инженер-программист.
Последние пару лет исследую «Web Perf», и с недавних пор — это моя должностная обязанность.
Иногда бывал спикером. Мои расшифровки были на главной «Хабра», а записи солидно просматривались на «Ютубе».
В программировании почти 10 лет.
Будет круто, если позволите мне провести эту неделю на уровне «Advanced».
Попробую рассказать о чём-то продвинутом, с академической терминологией, но без долгих подводок. 🧐
Ну и чтобы хоть как-то поднять доверие к своим последующим тредам — представлюсь...
Мне посчастливилось найти своё дело ещё в юности. В школе шёл на медаль и боялся после 9 класса поступать в ссуз (хоть и при РКЦ «Прогресс», где строили ракеты), чтобы быстрее прикоснуться к программированию. Рискнул.
Взял красный диплом ССУЗа, и, как итог, на 18-летие я получил в трудовой книжке запись «программист». С тех пор стаж не прерывался.
Я работал фронтендером и параллельно фулл-тайм учился в лучшем ВУЗе города.
Это был как раз тот период, когда «каждый день выходил новый JavaScript-фреймворк».
Через несколько лет получил ещё один красный диплом (уже бакалавра) и начал выступать на профессиональных конференциях. В основном рассказывал о производительности фронтенда.
Двух лет выступлений хватило, чтобы на «YouTube» и «Хабре» искаться по запросу «Белов Артём фронтенд».
Со временем стал тимлидом.
Поступил в магистратуру, чтобы с профессором исследовать предиктивную загрузку веб-приложений. Уже три семестра экспериментирую с рациональным применением машинного обучения в рамках JS-приложений.
На момент первого курса магистратуры, стал руководителем разработки React-направления в одной из самарских компаний.
Сейчас работаю над «Web Performance» в компании, которая отвечает за цвет купола в доме «Зингера».
По сей день не боюсь быть студентом (в широком смысле слова) — учусь, пробую себя в контестах по программированию и не боюсь чего-то не знать.
Тред (@belov)
Вторник
🧑🔬 Ревёрс-инжиниринг медленного Твиттера
Так получилось, что Твиттер в этой стране работает не шустро.
Давайте представим, что мы в штате и должны предложить решения этой проблемы.
Q–Как инженеры Твиттера могут решить сетевые проблемы сервиса в этой стране?
A–Никак.
Это логично, ведь проблема по другую сторону их штаб-квартиры. Где-то на магистрали до Франкфуртского CDN, который и отдаёт нам статику.
Возможно, команда Твиттера вообще ничего не делала. Но я в это не особо верю, так как отдел мониторинга привык видеть «пики» на графике TTI, а вот к иллюстрации комбинаторного взрыва на графиках 10 марта они точно не были готовы.
На всём пути инвестигации нам потребуется только вкладка «Network» в «DevTools», терминал и понимание работы сети.
Кстати, проверить фундаментальные знания оппонента о работе сети можно прямо на этом инфоповоде.
Если собеседник считает, что технически заблокировать Твиттер сложно и шутит отсылками к инциденту с Телеграмм, то… ему есть повод освежить знания о (де)централизованных сетях.
В случае споров — напомните историю с LinkedIn.
Если же услышите «ты не понимаешь, это другое!», то просто извинитесь.
Начнём с того, что конкретно я не могу гарантировать технику, которая инкапсулирована в осуществление троттлинга запросов к Твиттеру. Есть ряд вариантов, которые внешне похожи.
Да и мне не особо интересна истина от первоисточника. Я хочу в ревёрс-инжиниринг.
Приступим.
Собственно, если полазить по Твиттеру, то всё кроме картинок и первых экранов выглядит шустрым, если не заострять внимание. Даже через день.
Открываем «F12» > «Network» и пролистав колонку «Size» видим, что статика закэширована на диске или в Service Worker.
Это отголосок грамотного агрессивного кэширования. 🙂
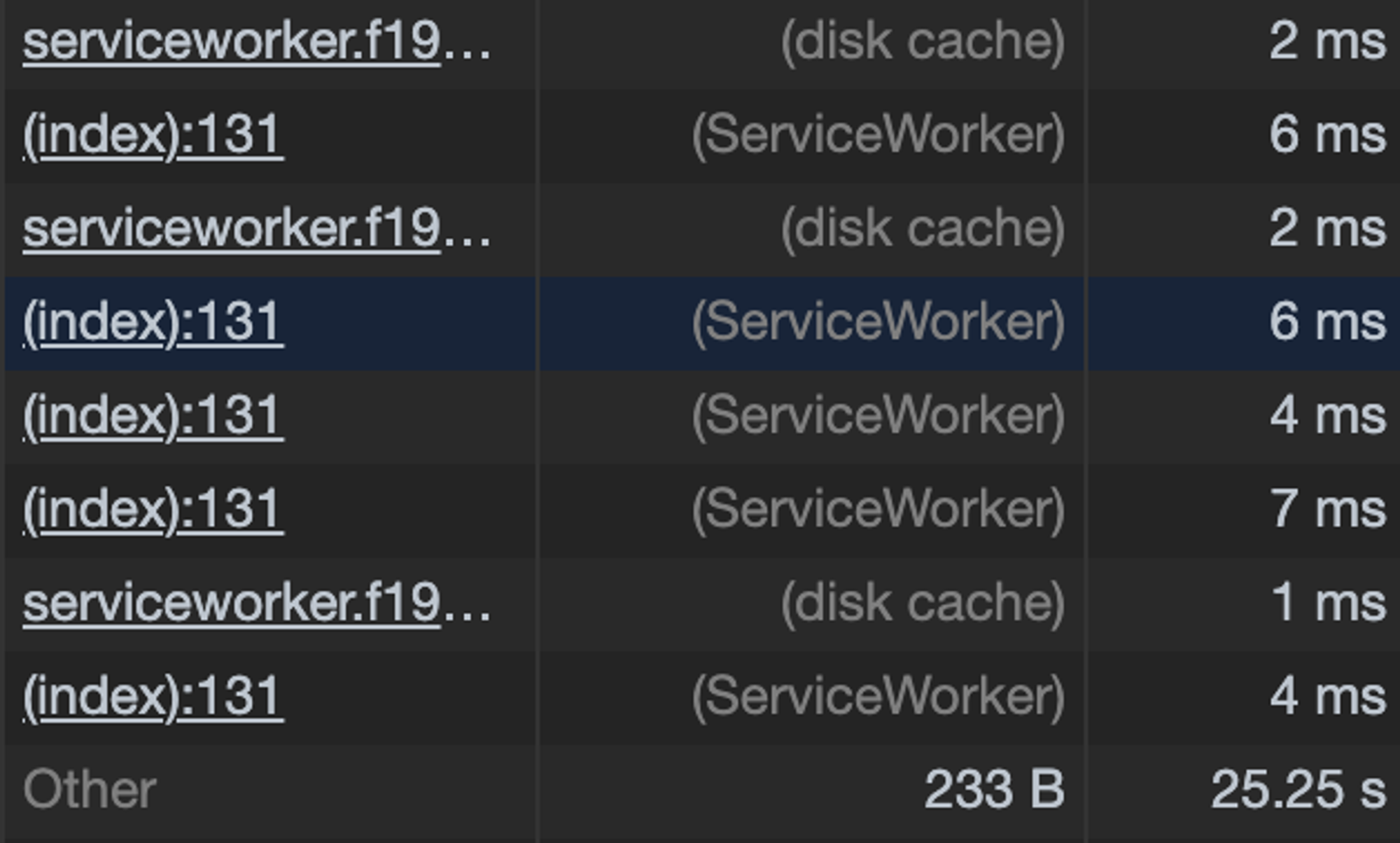
Вам пишу «F12», сам нажимаю «Cmd+Option+I», а думаю вообще про «DevTools»...
То есть, пара принципов агрессивного кэширования:
весомую, редко меняющуюся статику и «скелет» приложения поместили в «Service Worker».
у остальной статики — как можно реже менять хэш в имени файла и выставить долгие сроки «протухания» (в серверных заголовках).
Для потенциально изменчивых ассетов это даёт непрятный эффект. Пример с аватаром...
Вы: загрузили аватар и обновили страницу
Твиттер: мгновенно отображает старый аватар и... секунд 5 загружает новый.
Так себе UX. И парировать это поведение — затратно.
Это поведение можно переложить и на CSS.
Так что, keep in mind.
А про ETag сегодня кто-нибудь помнит ещё? 🧐
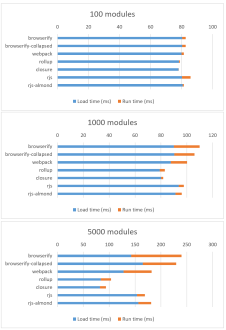
В погоне за неизменчивыми хэшами в файлах можно взять и сделать из 100 модулей, например, 1000.
Тогда эта «оптимизация» даст сбой, и увеличится и время загрузки и TTI, соответственно.
Ref: nolanlawson.com/2016/08/15/the…
Переводя зарубежный мем, получим формулу: «Чем больше вы модуляризируете приложение, тем больше оно становится».
В довесок, может быть, и выкатывают релизы теперь пореже. Эдакая параллель с LTSB-веткой Windows – черри-пикают только критично-важные патчи из основной ветки приложения.
Ветка, наверное, называется в стиле:
delete-after-a-monthА теперь, оставаясь в «DevTools» > «Network» сбросим кэш и жёстко перезагрузим страницу. Для этого — зажмите кнопку перезагрузки страницы и подождите секунду.
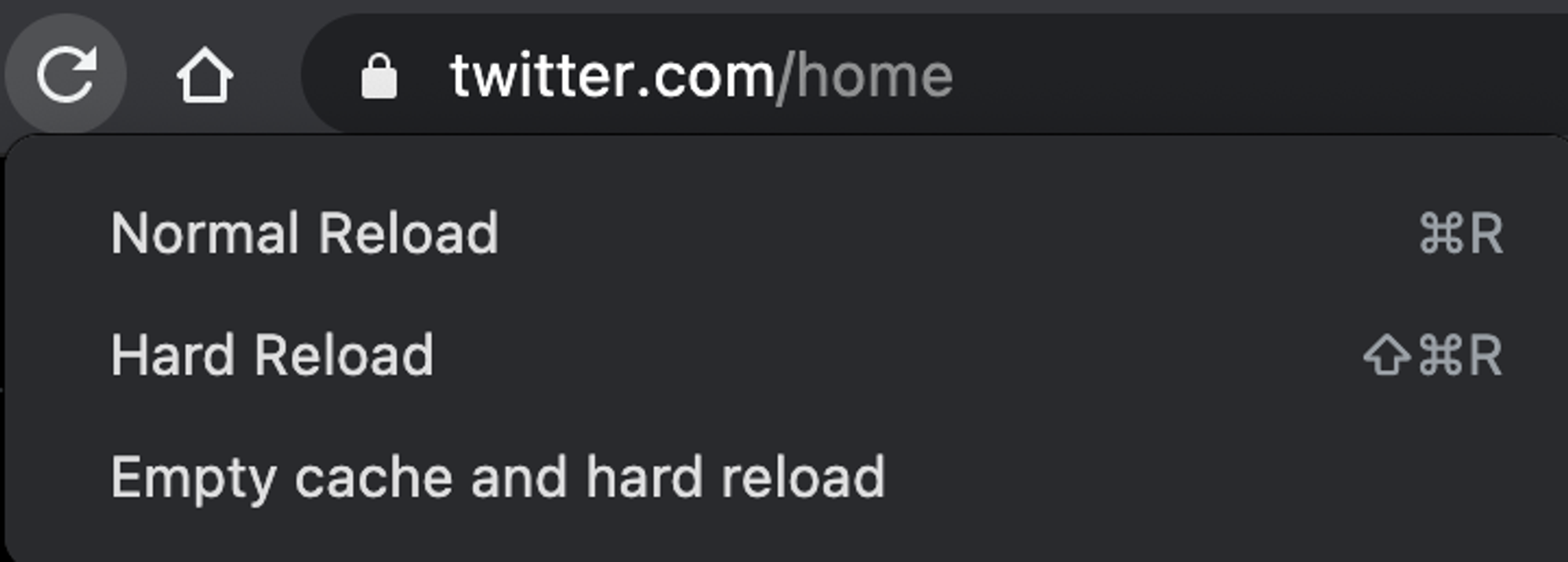
Собственно, после перезагрузки страницы тормозят все запросы: от Initial (где мы получаем HTML) до API вообще на другой хост.
Выполним десяток-другой замеров и посмотрим на корреляцию показаний...
Характер тормозов один и тот же — очень долгий TTFB и Content Download.
Похоже, что хотя бы потери пакетов нет.

Иначе, будь там PLR, тайминги загрузки для одного и того же ассета были бы разрозненные.
В стиле, что каждый 3-ий раз есть сильное отклонение от медианы.
Это уже флуктуацией не назовёшь.
Чтож. Перепроверим мои «теории» инструментами. Выполнив сотни тестов и попыток хоть как-то определить, что теряются пакеты... и я вижу, что нет, не теряются. Либо совсем в ничтожном количестве.
Да и вряд ли я теоретик... ибо не пишу на Coq.
Так почему потеря пакетов — это важно?
Потому что есть вариант переключить протокол CDN на HTTP/1.1 + доменное шардирование.
Я не прикалываюсь. И вот почему...
Дело в том, что H1 куда более устойчив к PLR (Packet Loss Rate), в отличии от H2.
TL;DR - Всё дело во внутреннем устройстве протокола.
Хотите разобраться? Пожалуйста: vimeo.com/190932569
Доменное шардирование в 2k21…
Кстати, вспоминается та шутка про UDP, которая обычно не д
Разумеется, подобного рода «спорные» решения не должны приниматься чисто на авторитете.
Это как в Data Science полагаться на эзотерику.
Для гипотез есть АБ-тесты.
Есть гипотеза по переходу с H2 на H1 для RU-региона?
Значит, её стоит подвергнуть АБ-тесту, где А-группа на H1, а Б - на H2.
Цифры не соврут.
Разумеется, Твиттер использует HTTP/2 для статики. Ведь этот протокол был заточен и под медиа-контент. Но есть проблема — чувствительность к PLR, что особенно актуально для мобильного интернета.
Будь Твиттер на HTTP/1.1, то в четверг сюда можно было бы тупо не заходить.
Резюмируем.
Инженеры твиттера применили:
- агрессивное кэширование посредством SW и серверных заголовков
- возможно, увеличили релизный цикл
- не переключилисьна протокол H1
Собственно, против топорного троттлинга\сужения канала, были применены такие же деревянные методы.
Послесловие:
Острых проблем с «Percieved Performance» в Твиттере не наблюдается, поэтому я их и не упоминаю. Они нивелируют на фоне проблем с сетью.
Виден инженерный подход 🥲
И это всё?
Да. Ибо продолжать генерировать нерентабельные варианты — странная затея, чтобы набрать классы.
Например:
- жать изображения в AVIF «на лету»
- понаделать скелетонов на все типы контента
- пробрасывать заблюренное изображение, а не его доминантный цвет
- ...
Неважно. Это нерентабельно. Инженер должен смотреть на проблему шире и оценивать не только пользу, но и затраты.
Тред (@belov)
Среда
⚛️ Is React Suspense Ready Yet?
Тред о том, чему можно поучиться у инженеров «FB», что закладывали Suspense-логику в реконсилер.
Ну... помимо того, что код можно ещё и релизить.
Disclaimer:
Подчеркну, что тред — исследование внутреннего устройства и попытки понять решения инженеров.
Призыва к использованию здесь нет.
Вообще, первое впечатление о Suspense, достаточно обескураживающее.
- Во-первых, ты думаешь, что это компонент.
- Во-вторых, ты понимаешь, что этот «сахар» не особо-то впечатляет:

Но если всё же начать разбираться и понять, что «Suspense» — термин, а затем разложить его на составляющие, то их будет всего две:
React.lazy() - отвечает за разбиение кода
Кэш - отвечает за кэширование данных от API
C Reat.lazy() все знакомы — компонент для код-сплиттинга.

И для того, чтобы заменять fallback-компонент, на тот, что загружается, тут используется «алгебраический эффект».
Объяснение в 5 строк внизу на картинке, а солидная статья по этой ссылке: overreacted.io/algebraic-effe…

Со вторым компонентом Suspens'а (кэшем) всё неопределённо.
С ним непонятно что делать. Уже второй год.
В документации так и написано: reactjs.org/docs/concurren…

Принцип работы React-компонента с кэшем аналогичен — бросить из компонента асинхронную функцию к API, так как для неё уже инкапсулирован обработчик в <Suspense />.

В этот момент происходит первая фаза понимания паттерна — отрицание.
— «Всмысле, кидать промис из компонента?»

Затем, «гнев».
— «Так мне ещё и кэш самому надо инвалидировать? А давно это надо делать на фронте?»

Потом, торгуешься, но всё же делаешь первую реализацию своего нерабочего кэша (на картинке).
— А что, пускай отдыхает 😎
Потом, погружаешься в тему и узнаешь про LRU-алгоритм, так как объект — так-себе кэш.
ru.bmstu.wiki/LRU_(Least_Rec…

В конце приходит и понимание того, что в Suspense, так-то, содержится конструкция
catch, которая ожидает выбрасывания промиса от API...
...но ты использовал этот потенциал только для React.lazy() 😶О да, и вот, без лишних предисловий, 20 твитов спустя, мы у чего-то интересного. 👏
Понятие Suspense не ограничивается только отложенной загрузкой компонентов и данных.
Рассмотрим нестабильный компонент <SuspenseList />, что способен делать композицию из <Suspense />.
В документации всего 1 абзац. Зато в репозитории есть тесты. Их и почитаем.
Про параметр
revealOrder можно узнать самостоятельно. Из одноабзацевой документации.
Сейчас же, мы приглядимся что Энрю Кларк покрыл тестами для пропа tail.Опция
tail имеет 2 состояния.
Нам интересен tail="collapsed", что использует алгоритм отображения компонентов строго очереди, а не по готовности.
Десонмтрация работы алгоритма: suspensive-react.artbelov.now.sh/74
листайте вправо.
Продублирую работу алгоритма...
Дано: 4 компонента, обёрнутые в SuspenseList c
tail="collapsed".
Hint: Начните следить за судьбой компонента <D /> 👀
1 коммит: 3 фоллбэк-компонента из 4. Где <D />? 😒

2 и 3 коммит — поочерёдная вставка загрузившихся компонентов <A /> и <B />.
4 коммит — одновременная вставка загрузившихся компонентов <C /> и <D />. (О, повезло-повезло...)
а вот фоллбэк-компонента <D /> так никто и не видел. 👀

Реконсилер в реакте штука сложная и она знает цену коммита в (Virtual)DOM. Это дорого.
А конкретно в данном случае, было заранее просчитано, что рендерить фоллбэк-компонент - нецелесообразно.
Фактически — реконсилер сэкономил на рендере фоллбэк-компонента, а к следующей транзакции уже был готов и сам загружаемый компонент.
Итого, Suspense своей реализацией показывает:
DX — это важно.
Кэш — это то, с чем уже пора учиться работать.
Для больших транзакций, рациональнее считать время планируемых работ, нежели выполнять инструкции.
Ибо если всё важно... то может ничего не важно?
Тред (@belov)
Десонмтрация работы алгоритма: suspensive-react.artbelov.now.sh/74 листайте вправо.

⚛️ Is React Suspense Ready Yet? Тред о том, чему можно поучиться у инженеров «FB», что закладывали Suspense-логику в реконсилер. Ну... помимо того, что код можно ещё и релизить.
Этот тред — выжимки из моих исследований 2019 года. Feel old yet?
Есть презентация suspensive-react.artbelov.now.sh
twitter.com/jsunderhood/st…
Если «React Suspense» сам себя остановил на стадии эксперимента, то это можно считать успешным релизом? 🤔
Четверг
🧑🔬 ML & JS: Предиктивная загрузка модулей веб-приложений
В этом треде я постараюсь популярно описать положение дел в этом направлении, так как уже 3 семестра магистратуры экспериментирую над этой темой вместе с профессором. 🧐
Disclaimer:
Автор треда постарался не жестить и особо не оперировать терминами из «Machine Learning».
Но тут всё равно очень душно. 🥵
Что мы знаем и слышали о предиктивной загрузке?
Очевидно — Guess.js
Проект был анонсирован на Google I/O 2018, затем много звёзд на Github, доклады, кейноуты и маркетинг с участием Эдди Османи.
Потом, плагин для не менее популярного Gatsby.

По README в Guess.js видно принадлежность автора – человек из науки, Минко Гечев.
Структура документа, будто бы не из «Open Source», а чисто тезис на научную конференцию*.
Вот он — github.com/guess-js/guess…
причём наивысшего качества! Много смысла, мало текста!

И после этого шквала событий… всё.
Проект по сей день в альфа-версии, а топ-контрибьютор — “renovate-bot”.
И может сложиться впечатление, что Guess.js заброшен, или даже (почему-то) перестал нести пользу.
Но нет.
Я попробую изложить свои предположения почему так происходит.
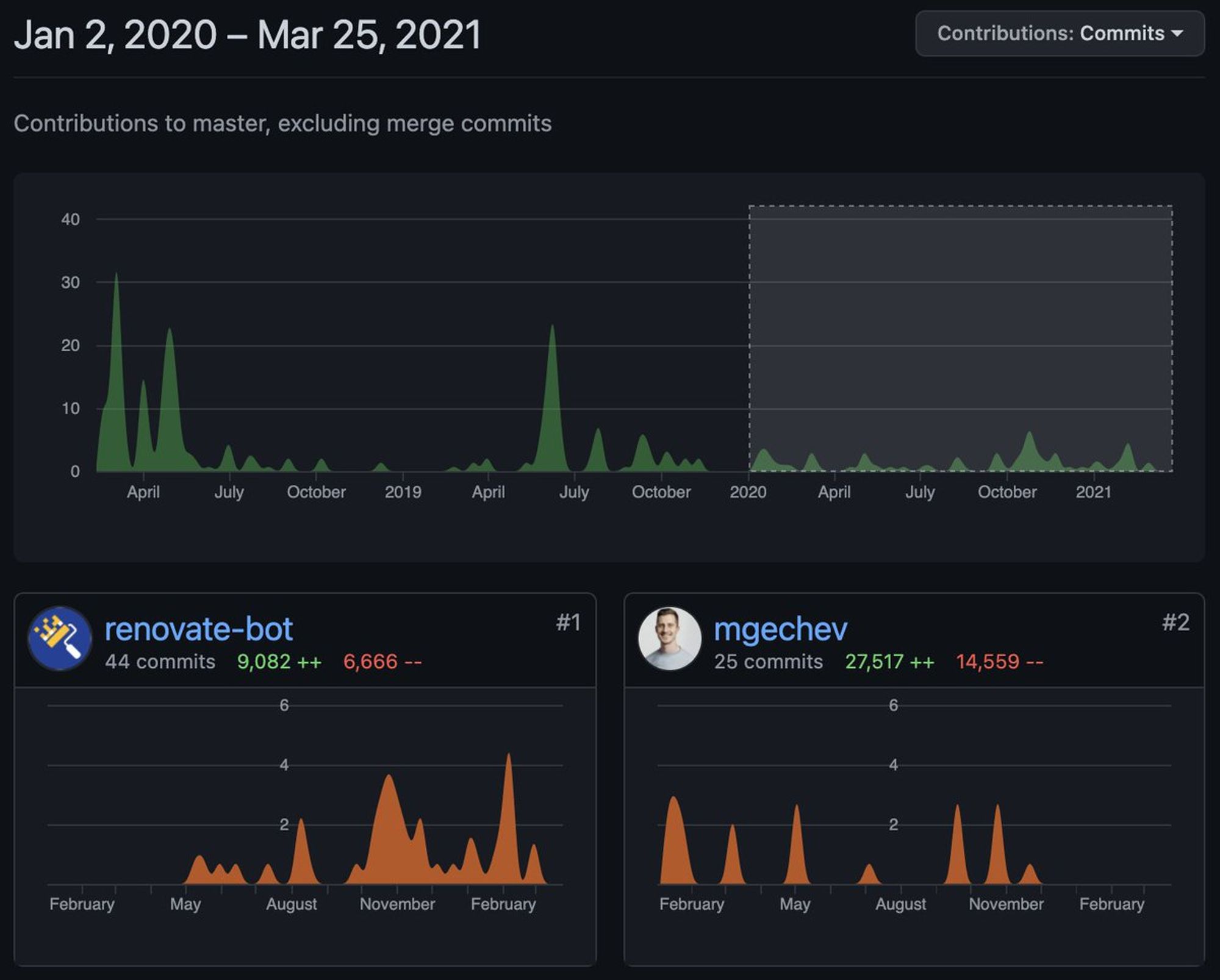
В сторону предиктивной загрузки ислледуют множество компаний. У каждой свои цели.
Вот, например, патент* MS для втраивания нейронки в браузер – patents.google.com/patent/US10795…
мы же все поняли, что это для Edge?
В научном же мире (пока в техническом тишина) солидные авторы, в авторитетных журналах, публикуют достойные научные труды.
Вот, что я нашёл из самого авторитетного - docs.google.com/document/d/1MA…
Короче говоря, у меня сложилось впечатление, что предиктивный фетчинг — это не совсем про «Open Source», а больше про конкурентные преимущества. 💰
Поэтому, мы продолжаем слышать про «машинное обучение» ото всюду, но открытых реализаций не видим.
Anyway...
💡 Идея предиктивной загрузки модулей заключается в следующем:
На этапе сборки приложения, для каждого роута определяются вероятность перехода на другой. Затем, берётся 1-3 самых вероятных и их ассеты предзагружаются посредством rel=”preload”.
developer.mozilla.org/ru/docs/Web/HT…
Итог — переход на роут практически мгновенный, так как все его ассеты (или большинство) уже предзагружены и остаётся потратить время только на загрузку HTML.
👍 Плюсы идеи:
меньше нагрузка на сеть.
меньше нагрузка на CPU, так как загрузка и парсинг выполняются с низким приоритетом и в простое.
не нужно гнаться за размером бандла (уж так сильно).
Короче говоря — оверкилл по всем пунктам.
😓 Минусы:
внедрить в сборку (затратно)
настроить сборку (ещё сложнее)
отладить сборку (совсем фатально)
🧐 Что нужно понимать для интеграции предиктивной загрузки?
По сути, для реализации этой задачи хватает базового знания «Computer Science» и азов «Machine Learning». 🤖
Досконально необходимо вникнуть только в сборку приложения и работу с API аналитики.
🦸♂️ На данный момент, главный «компонент» предиктивной аналитики — цепи Маркова.
en.wikipedia.org/wiki/Markov_mo…
Эта модель имеет убеждение, что при фиксированном настоящем будущее независимо от прошлого.
Модель имеет ряд разновидностей, которые тоже используются для «тренировки» на данных.
Например, скрытая Марковская модель - en.wikipedia.org/wiki/Hidden_Ma…
Дополнительно, с моделью задействуется метод Монте-Карло, для вычисления вероятностей - en.wikipedia.org/wiki/Monte_Car…
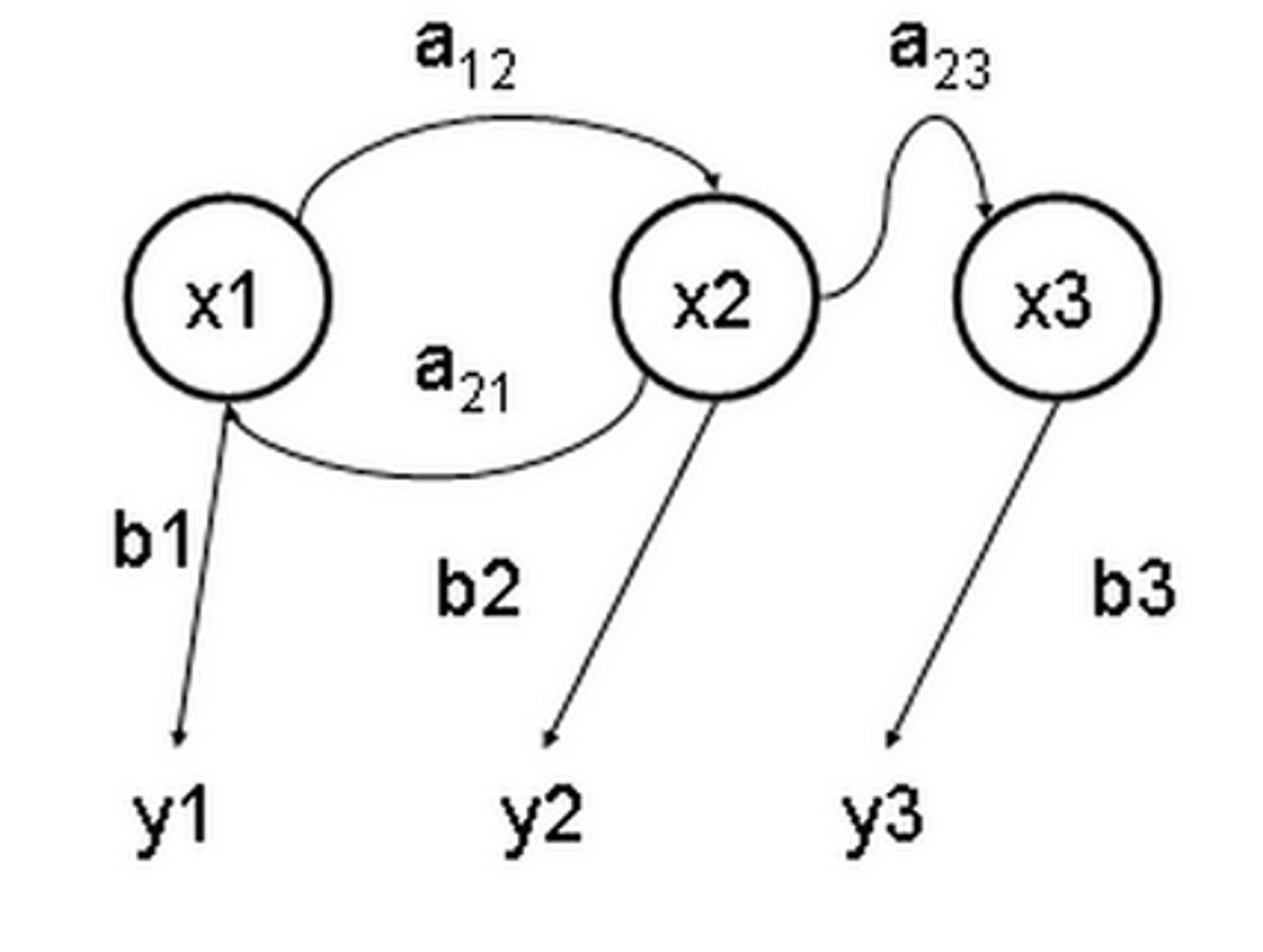
Для того, чтобы в ориентированном графе приложения искать роуты с сильной связностью, используется алгоритм Тарьяна. Находит он за линейное время.
en.wikipedia.org/wiki/Tarjan%27…
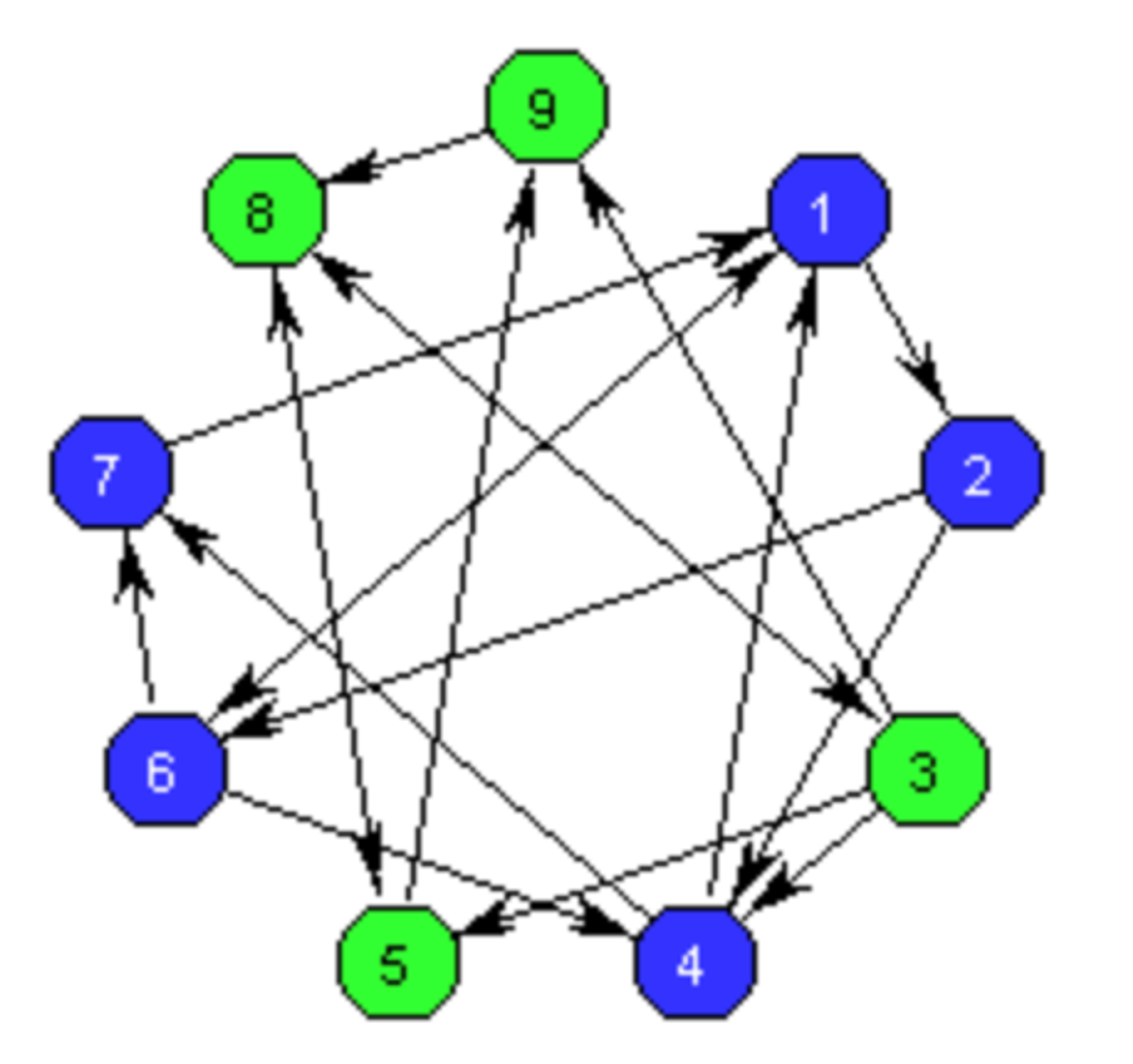
Опционально, для группировки роутов в группы, используется кластеризация методом k-средних.
В основном же, этим методом разбивают пользователей на группы. То есть для какой группы подгрузить тот или иной набор последующих роутов.
en.wikipedia.org/wiki/K-means_c…
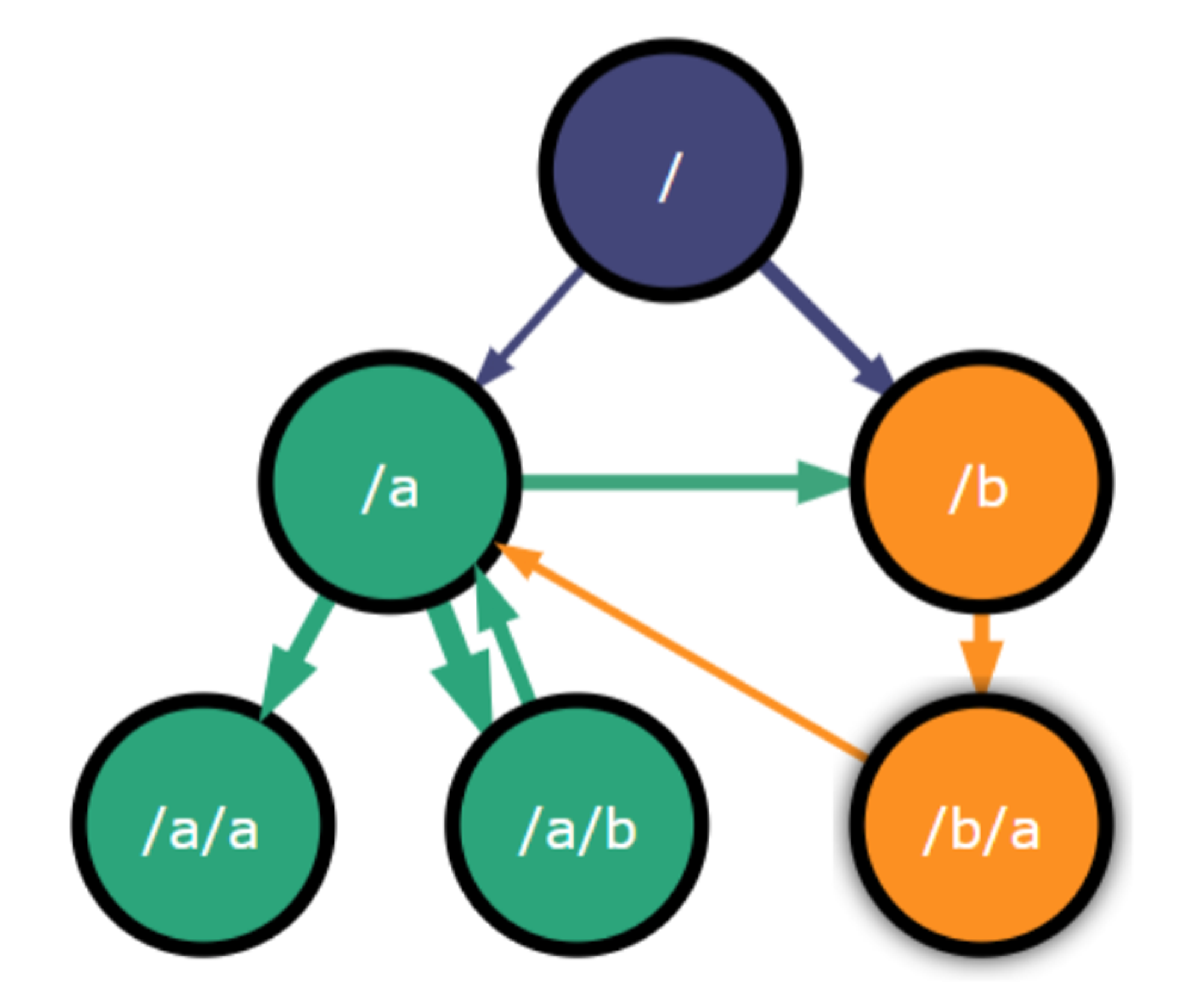
👀 То есть, предиктивная загрузка - это сборка, цепи Маркова (или скрытая Марковская модель), метод Монте-Карло, алгоритм Тарьяна, кластеризация, аналитический источник и ориентированные графы.
И у всей этой истории есть даже Early Adopters: iihnordic.com/blog/machine-l…
🧐 Итого, что мы имеем:
Предиктивная загрузка распространяется не таким уж стремительным темпом, как маркетинг «ML».
В научном мире, статьи о предиктивной загрузке только набирают темп. Одна проблема — дальше «PoC», у академиков, дело не особо далеко заходит.
И это грустно. 🥲
Тред (@belov)
@jsunderhood а в чем профит если посчитать в деньгах (business value)?
«Amazon» ещё в 2017 запатентовали предиктивный поиск с предзагрузкой информации о результатах: patents.google.com/patent/US10572…
У них с монетами всё в порядке. 💰
twitter.com/8gene/status/1…
🧐 Что нужно понимать для интеграции предиктивной загрузки? По сути, для реализации этой задачи хватает базового знания «Computer Science» и азов «Machine Learning». 🤖 Досконально необходимо вникнуть только в сборку приложения и работу с API аналитики.
Там не «Рокет саенс», можно и с батутом справиться.
twitter.com/jsunderhood/st…
💡 Идея предиктивной загрузки модулей заключается в следующем: На этапе сборки приложения, для каждого роута определяются вероятность перехода на другой. Затем, берётся 1-3 самых вероятных и их ассеты предзагружаются посредством rel=”preload”. developer.mozilla.org/ru/docs/Web/HT…
О! У меня есть версия для тех, кто искал оптимальный путь... 🧐
Предиктивная загрузка — взвешенный граф. ⚛️
twitter.com/jsunderhood/st…
Пятница
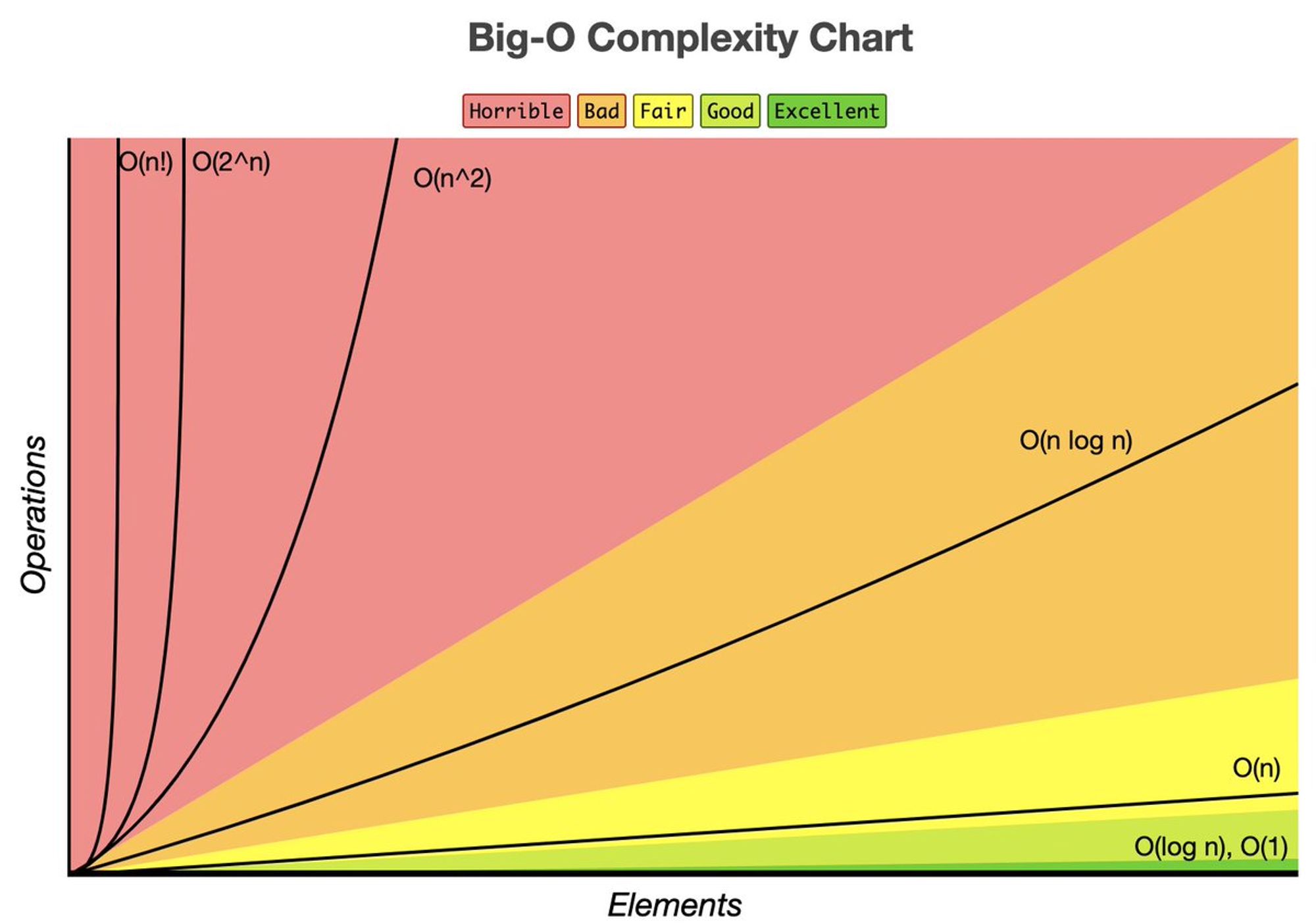
🧑🏫 Почему «BigO» так важен в «Web Performance»?
В этом треде автор постарается объяснить, почему в «Web Perf» нет места хакам, а подебажить алгоритм на бумаге — это круто.
📝 Disclaimer
Автор треда — адепт старой школы и в 2k21 зачем-то учится в универе, хотя это уже не модно. Убеждён, что если у тебя нет фундаментальных знаний, то «инженером» называть себя не стоит. Примерно о том же говорит и Wikipedia в определении «Engineer».
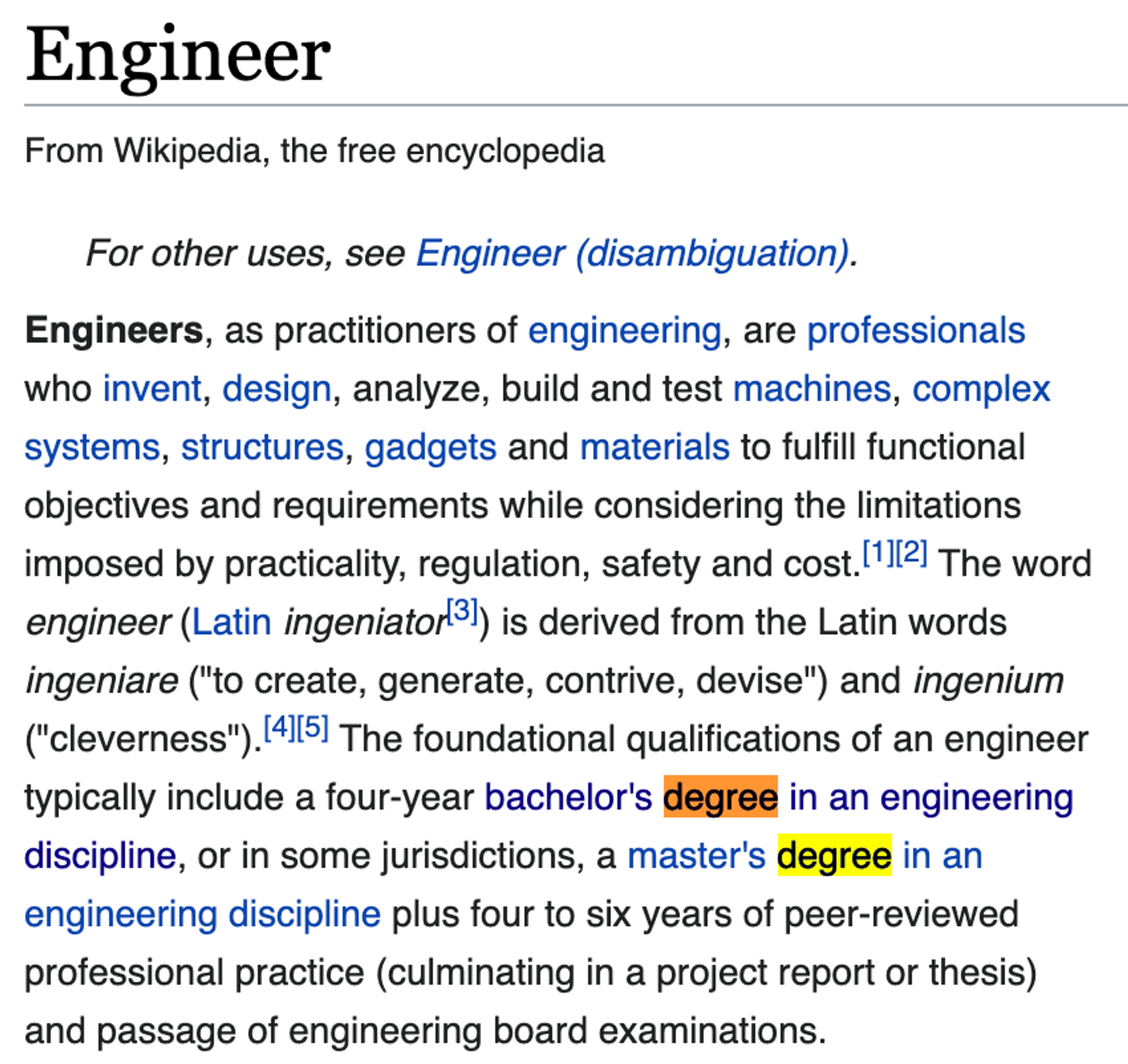
Я не уверен, знают ли ребята без фундаментального образования, как обозначается блок модификации на блок-схеме, да и о чём он вообще.
Алгоритмизация закаляется в учебных заведениях. Сейчас же, в эпоху шейминга вышки, если сам не выучил, то… я даже не знаю что.
Ничего?

Если ты начертился на бумаге алгоритмов, то ставь класс.

Придётся рассказать про опыт «старой школы» — мой.
Конкретно у меня было 2 преподавателя по алгоритмизации с абсолютно разными подходами.
Алгоритмизация (опыт в техникуме)
Преподаватель давал разные задачи и принимал решения любой ценой.
Это олимпиадный подход. Ты забиваешь на всё и решаешь на скорость. Лишь бы потом эту программу было не лень вбивать в Pascal.
И это хороший опыт.
Алгоритмизация (опыт в универе)
Преподаватель давал не ёмкие задачи и принимал только максимально оптимизированные решения.
И это лучший, как мне кажется, опыт!
P. S. У меня как-то не приняли лабу, потому что сложность была «N», а не «N-1».
Было забавно наблюдать за проверкой алгоритмов. Студент с алгоритмом на 10 блоков мог отлететь, а вот блок-схема на 3 листа сдавалась на «ОТЛ».
Кажется, где-то на этих занятиях я стал понимать как интерпретатор идёт по коду, процессор делает такт, а в памяти создаётся ячейка. 🤖
НО!
Я не могу понять почему не использовал даже простые оптимизации первые 2 года в своём коде, вообще.
Наверное, пока ты юниор, ты все силы тратишь на то, чтобы код был читаемым, а не эффективным.
И это нормально, нет проблем. Точите паттерны, ребята!

Когда алгоритмическая база освоена, самое время расширить свои знания о структурах данных. Ещё.
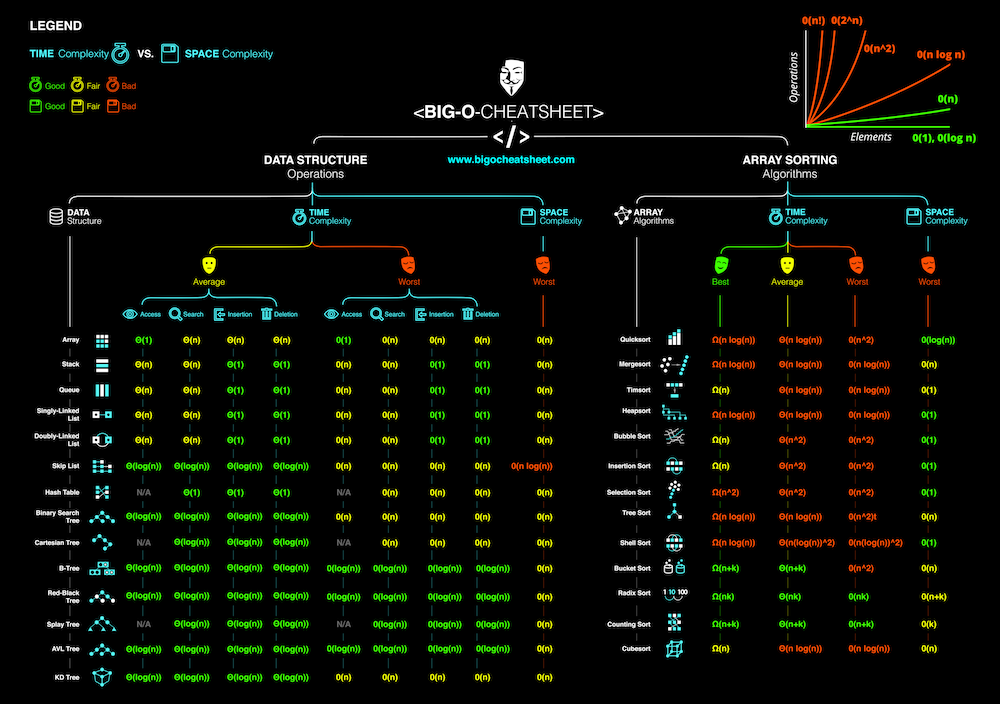
Ибо если загуглить «BigO», то одним из топ-результатов будет bigocheatsheet.com , где чётко понимаешь, что тут структур данных больше, чем ожидал. Надо гуглить.
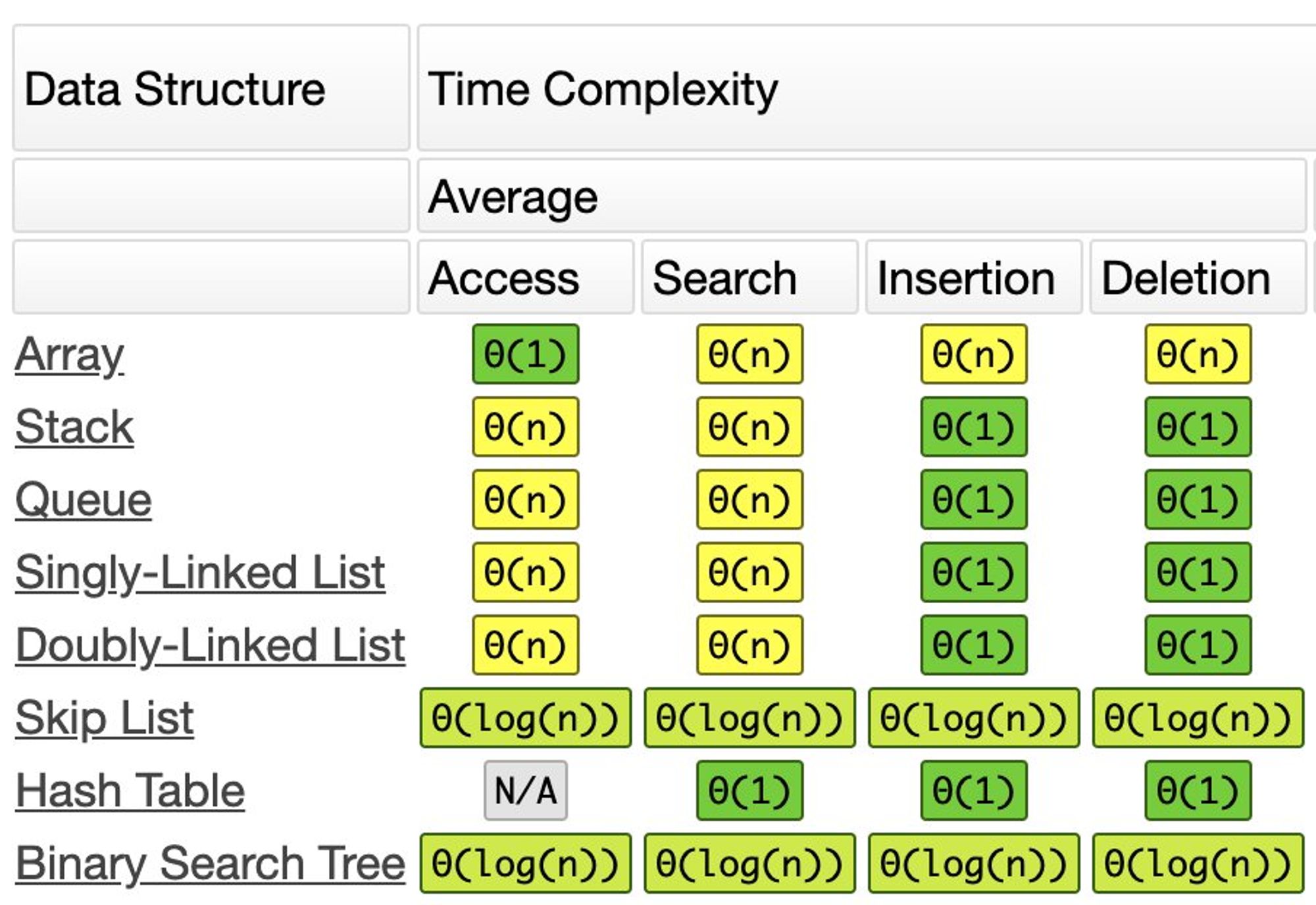
– «Плохие программисты беспокоятся о коде. Хорошие программисты беспокоятся о структурах данных и их отношениях» ©
Собственно, эту фразу Линус Торвальдс говорил в контексте «Git». Так что, тут говорится не об отличиях списка и массива. Повысьте градус контекста этой цитаты.
«BigO» и понимание структур данных — неотъемлемы.
Поэтому, затраты на: чтение, поиск, вставку и удаление сначала (увы, тупо) заучиваешь.
Потом, уже понимаешь «почему так?».
Затем, больше не возвращаться к шпаргалкам.
Там еще есть такой прикольный момент, когда ты сам понимаешь цену вставки:
- в начало
- в середину
- и в конец
для всех ходовых типов данных.
Потом, так же понимаешь и про «удаление».
Рекоммендую. Прикольное чувство.

И вот когда у тебя в голове есть понимание структур данных, а твои руки могу зачертить блок-схему, чтобы это понял кто-то из команды, то ты оптимизируешь иначе.
Со временем, у тебя появляются следующие повадки:
- Ты исследуешь алгоритм на неоптимальность;
- У тебя намётан глаз на квадратичную сложность;
- Ты чётко видишь лишнюю работу в чейне вызовов;
- Профайлер начинает кипятить Макбук;
- ???
- Ты начинаешь исследовать.
🥲
И восприятие эвристики оптимизации программы, меняются.
Нпример, помню свои мысли, когда увидел
optimize-js: «Ого, вот это показатели!»
Сейчас, более интересным кажется раздел объяснения алгоритма: github.com/nolanlawson/op…
И вердикт: «Использовать я его, конечно, не буду».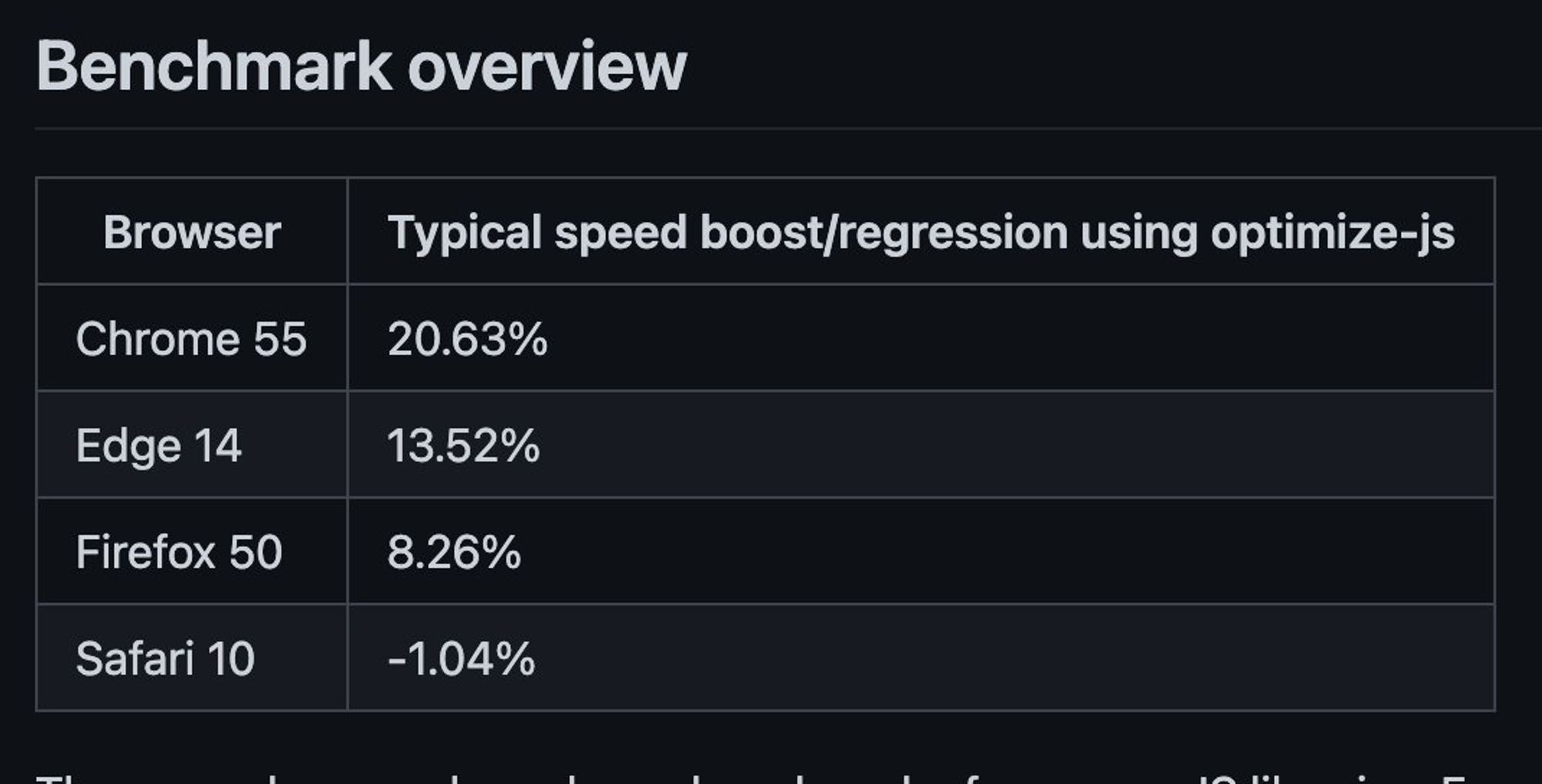
В трюк с обёртыванием объектов в
JSON.parse уже хочется вникнуть, а не просто использовать.
Что ж, идешь и смотришь объяснение от Матиаса: youtu.be/ff4fgQxPaO0?t=…
Всё становится на свои места.
Ref: v8.dev/blog/cost-of-j…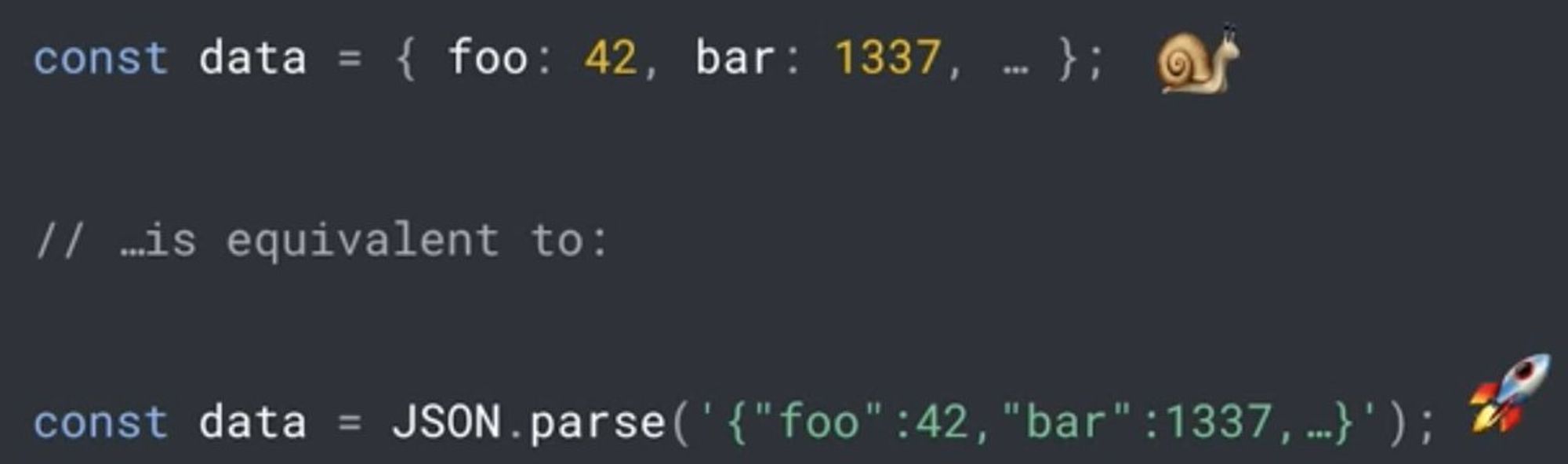
А затем у тебя начинают вызывать вопрос:
React.memo, shouldComponentUpdate и кастомные компараторы.
– «А зачем в этот узел вообще текут данные, если на вход мемоизация? Может, структуру компонента и поток данных сначала пересмотреть?»
Нам надо чаще думать о потоке данных.Итого, что нам даёт понимание «BigO» и структуры данных?
Они дают надежду, что «Web Performance» не скатится в чек-лист быстрых решений, а оптимизаторы будут не только созерцать графики «Web Vitals», но и думать о «Total Blocking Time».
web.dev/tbt/
И тогда, придёт и понимание того, что «UX» не заканчивается при остановке профайлера в "Idle", путь пользователя здесь только начинается.
С этими знаниями, может, и не потеряем инженерную культуру. 🥲
Тред (@belov)
Суббота
Если у вас есть желание поговорить о «Web Performance» (и вышке), то завтра в 19:00 МСК залетайте в «ClubHouse»!
joinclubhouse.com/event/xqYw7A8D
Воскресенье
🚀 Web Performance Profiling: 101
В этом треде найдём все неоптимизированные строки кода в рамках одного файла и поговорим о нюансах работы DevTools.
Хорошая привычка, если не хочешь копить Perf-долг.
⚠️ Disclaimer:
От этого треда не стоит ждать решения всех Performance-проблем. Ибо «DevTools» – не тот инструмент, мануал которого можно изложить в одном треде.
en.wikipedia.org/wiki/101_(topi…
📝 Предварительные требования:
Понимать что такое стек вызовов (LIFO)
Примерно понимать как интерпретатор JS «идёт» по коду
Ref: ru.hexlet.io/courses/js-asy…
Крайне желательно, чтобы были подключены «SourceMap».
Сердитый вариант —
cheap-module-source-map.
И помните, что чем больше вы хотите знать информации из карт, тем дольше будет идти (пере)сборка проекта.
Документация по различиям карт кода всё ещё тут: webpack.js.org/configuration/…🧑🏫 Дано:
Написан код, который вызывает подозрения.
Мы понимаем, что он тормозит, но не совсем понимаем, где и в каком объёме.
Здесь, в примере — это функции и префиксом
slow*.Действия:
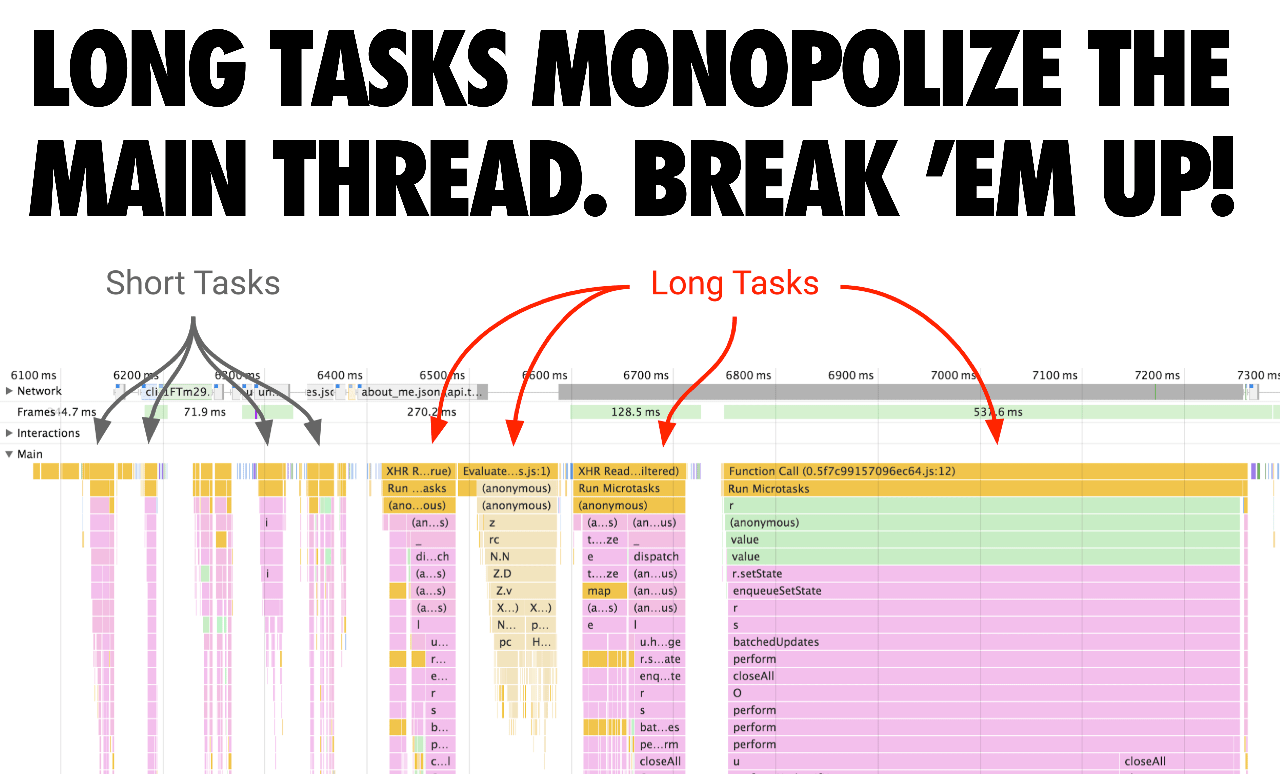
Открываем приложение и жмём «F12» > «Performance»
Для контраста замеров, выставляем троттлинг: ⚙️> «CPU» > «6x slowdown»
опционально, если есть корреляция скорости кода от API-вызовов, троттлим сеть: ⚙️> «Network» > «Fast 3G»
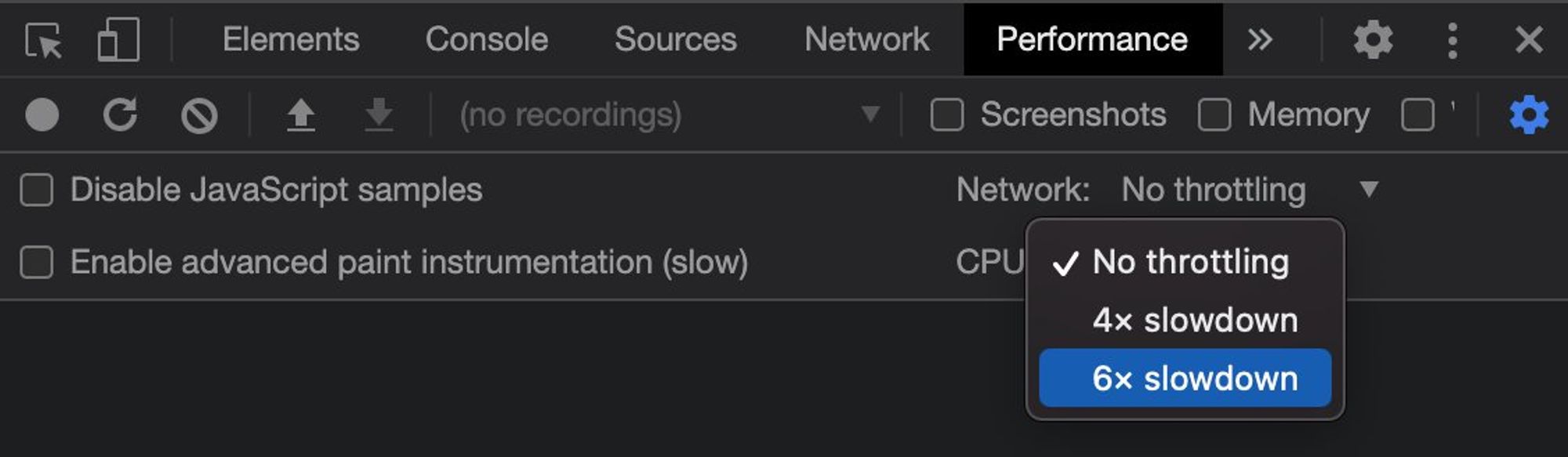
Теперь нам необходимо записать профайлером работу замеряемого кода. Здесь может быть два алгоритма:
Код вызывается при старте приложения (до ухода приложения в Idle). Просто жмём: 🔄
Код вызывается при взаимодействии. Жмём 🔴 и триггерим вызов кода (кликом, наверное).
Когда Profile-таймлайн отобразился, то можно сразу перейти в нижнюю часть панели, и нажать «Bottom-up».
Нам будут релевантны обе колонки:
«Self Time»: время выполнения функции
«Total Time»: общее время выполнения функции за профайл
Выделить главную — трудно. Анализируйте.
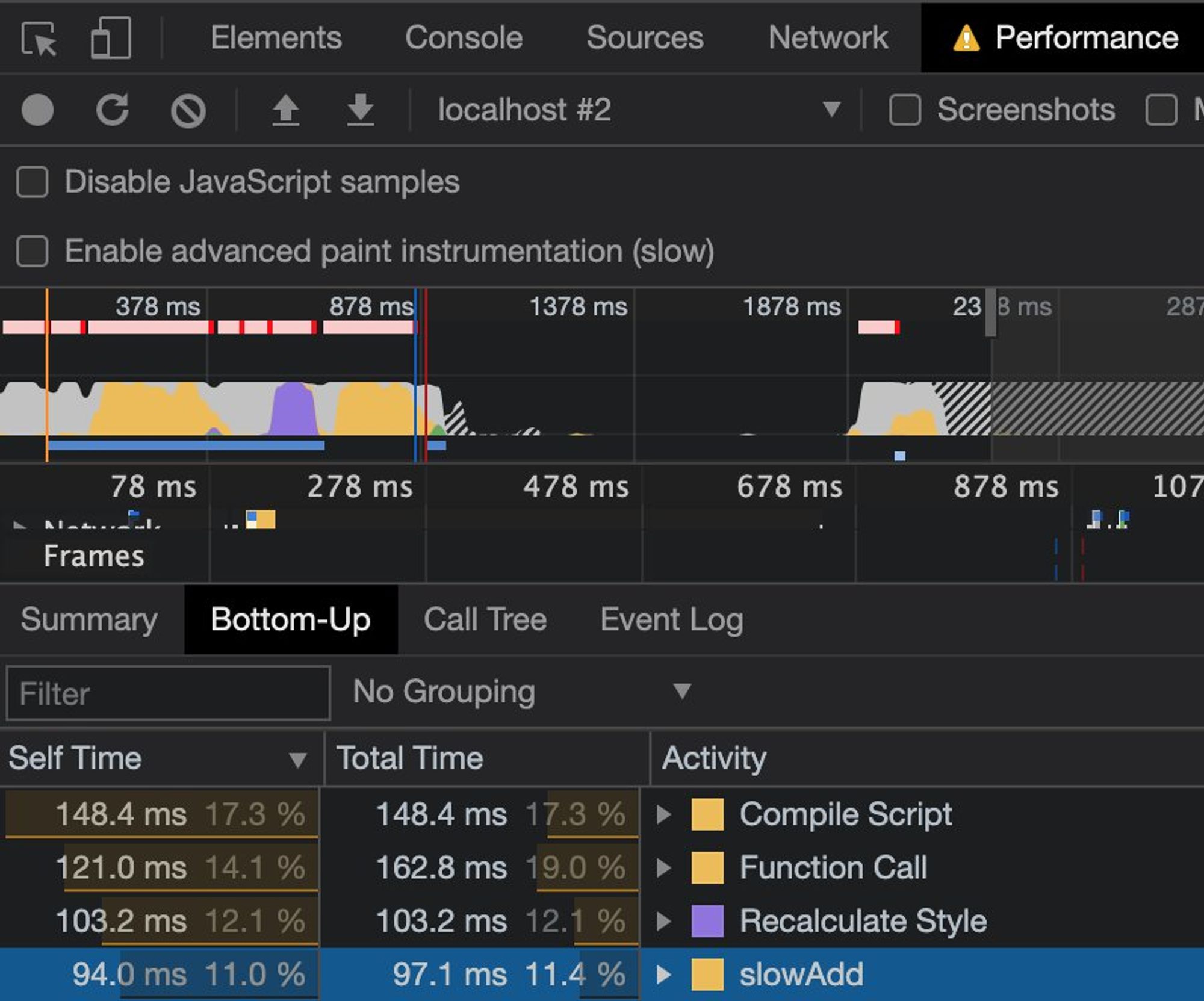
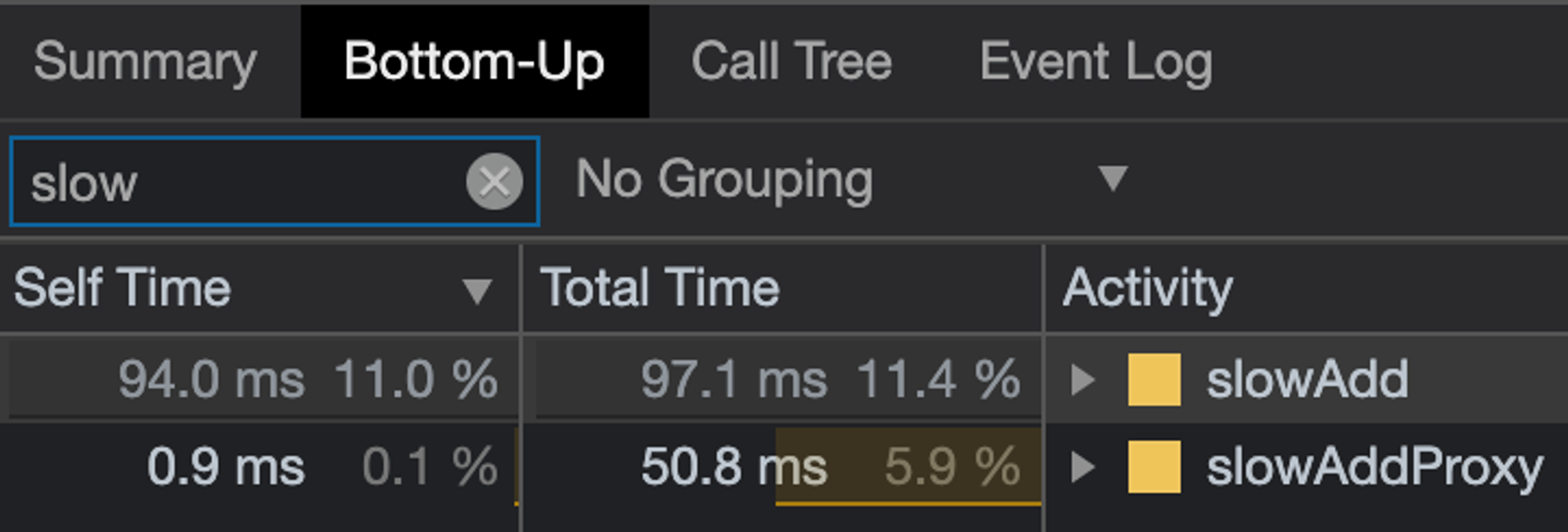
Если исследуемая функция в ТОПе по времени, то ОК — дебажим дальше.
Если нет, можно отфильтровать функцию по имени и прикинуть — стоит её оптимизировать или нет.
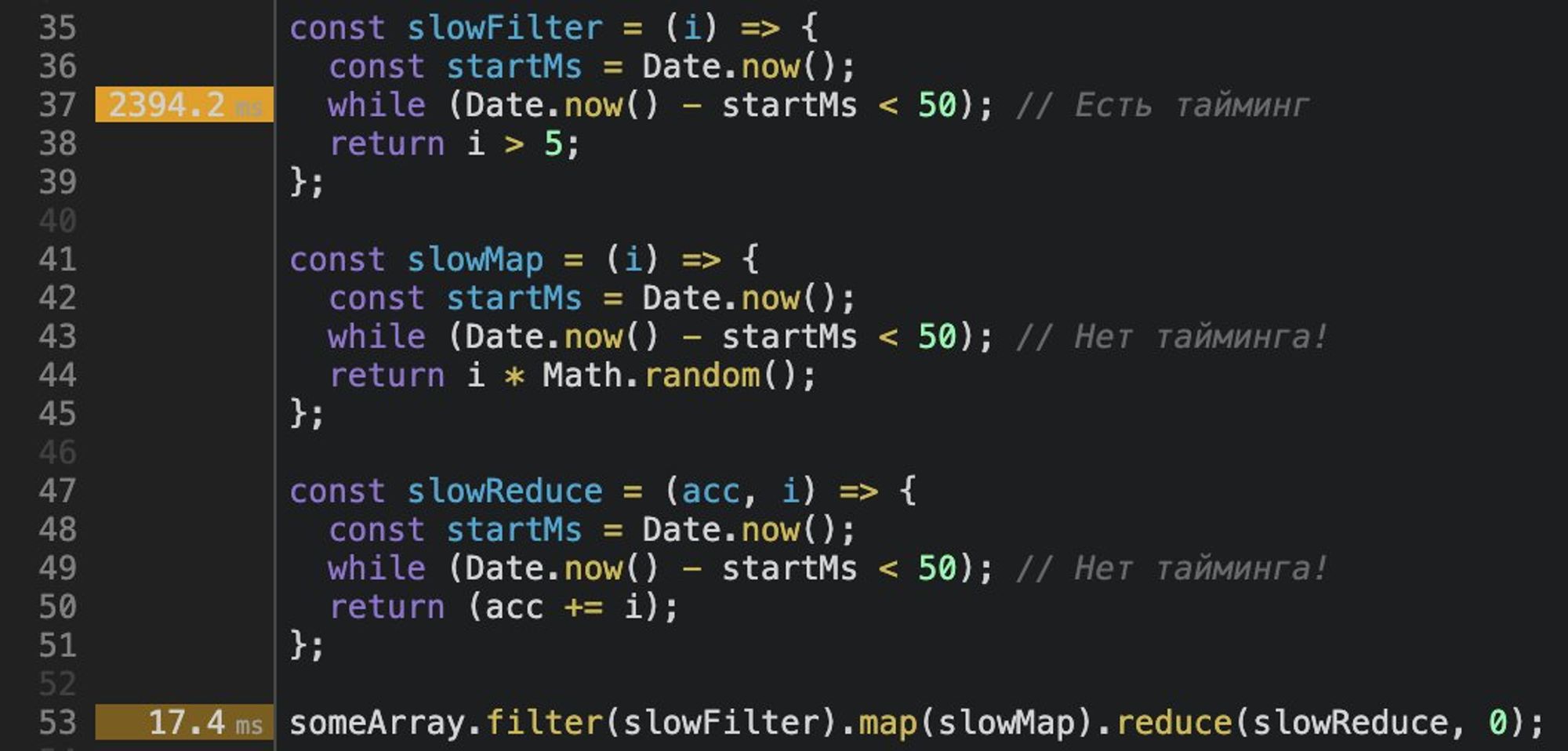
Теперь, посмотрим на тайминги каждой строки в панели «Sources».
Тут 2 варианта перехода:
Нажимаем правой кнопкой по функции в списке и пытаемся найти пункт «Show in Source».
Если пункта нет, то для перехода будет достаточно проставить
console.log и кликнуть по имени.
И тут есть пара не самых очевидных моментов при работе с этими таймингами.
Покажу на примерах...
Тайминги возле строк — суммарные.
Всегда будьте внимательны при отслеживании цепочки вызовов. «Тормозящими» могут казаться функции-обёртки или прокси.
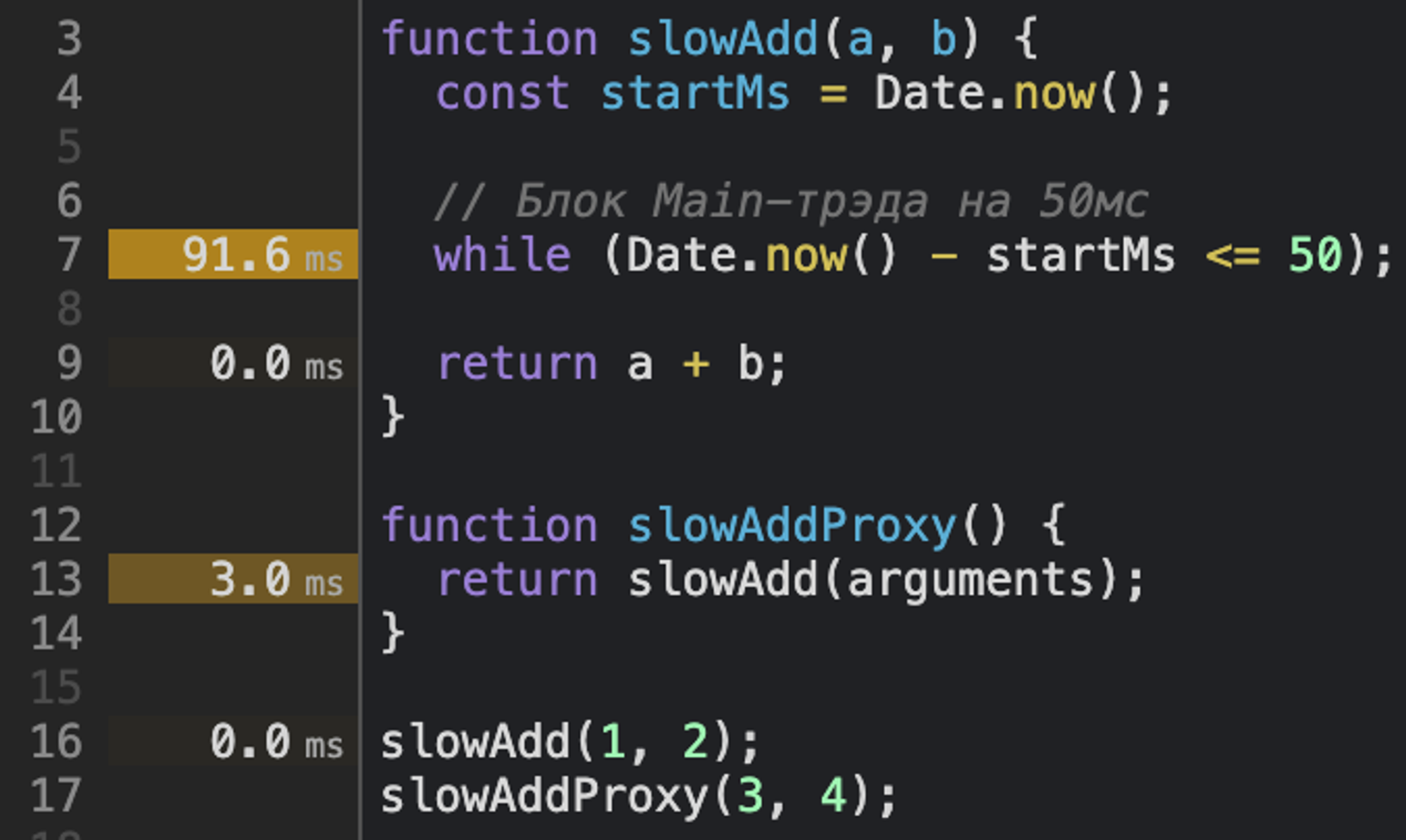
Для наших целей хватит
console.time, который по-старинке а̶л̶ё̶р̶т̶а̶м̶и̶ в консоль выведет промежуточные замеры по метке.
P. S. «Performance API» в этом треде не используем.
developer.mozilla.org/ru/docs/Web/AP…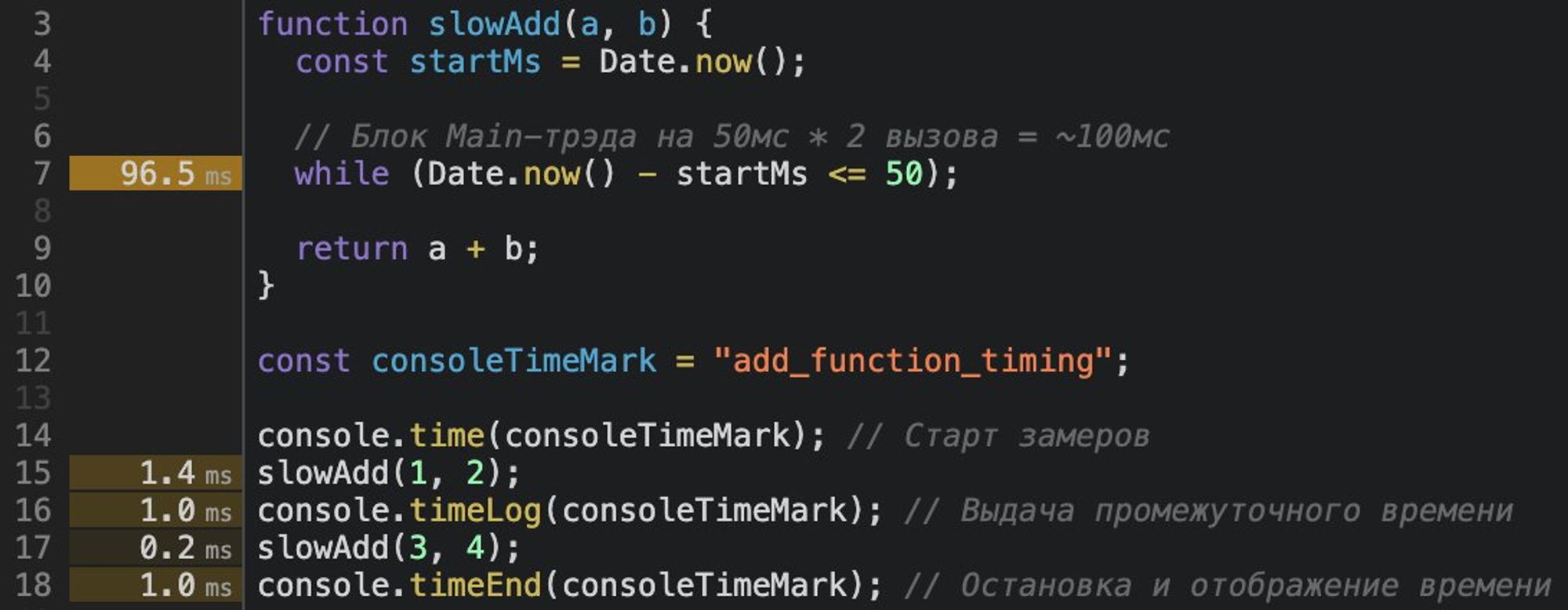
🧐 Pro Tip
Если вы дебажите цикл\генератор\подписку и устали фильтровать результаты из общей массы, то рискну напомнить про
console.table().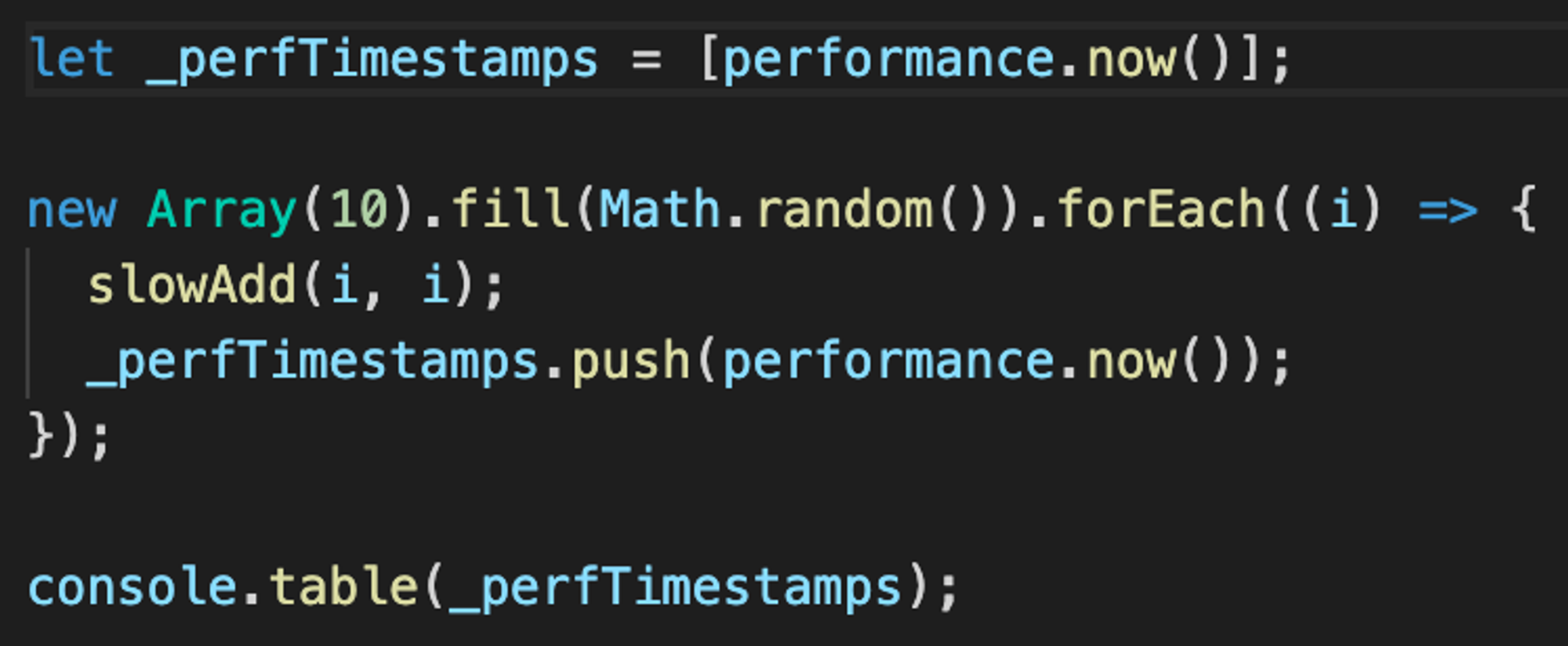
И для адептов FP – про тайминги у чейнингов.
Они, (на данный момент?), профайлятся не всегда стабильно.
Поэтому, если вы уверены, что код не оптимален, а DevTools молчит, то есть смысл облегчить профайлеру работу посредством инлайна методов, разбиения чейна на результаты, итд.
Q: Хотелось бы больше... а через какие курсы сейчас вкатываются в «DevTools»?
A: Сейчас? Не знаю, сам же был Early Bird у этого курса: frontendmasters.com/courses/chrome…
P. S. Не могу слепо рекомендовать, так как курс 2018 года. Но по заголовкам погуглить стоит.
Тред (@belov)
📝 Recap тредов недели от @belov для JSUnderhood:
🧑🔬 Ревёрс-инжиниринг медленного Твиттера Так получилось, что Твиттер в этой стране работает не шустро. Давайте представим, что мы в штате и должны предложить решения этой проблемы.
⚛️ Is React Suspense Ready Yet? Тред о том, чему можно поучиться у инженеров «FB», что закладывали Suspense-логику в реконсилер. Ну... помимо того, что код можно ещё и релизить.
🧑🏫 Почему «BigO» так важен в «Web Performance»? В этом треде автор постарается объяснить, почему в «Web Perf» нет места хакам, а подебажить алгоритм на бумаге — это круто.
🧑🔬 ML & JS: Предиктивная загрузка модулей веб-приложений В этом треде я постараюсь популярно описать положение дел в этом направлении, так как уже 3 семестра магистратуры экспериментирую над этой темой вместе с профессором. 🧐
🚀 Web Performance Profiling: 101 В этом треде найдём все неоптимизированные строки кода в рамках одного файла и поговорим о нюансах работы DevTools. Хорошая привычка, если не хочешь копить Perf-долг.
Тред (@belov)