

Сегодня немного пройдемся по внутренней кухне Node.js и моим, связанным с ней (странным) экспериментам.
Если вы работали с бинарными данными в Node.js или, например, пытались реализовать драйвер БД с бинарным протоколом, вам знаком класс Buffer из одноименного модуля.
Любопытно то, что сами бинарные данные Buffer хранит off-heap, а в куче хранится только объект с метаданными. Соответственно, при создании буфера вызывается аллокатор (Node.js использует системный аллокатор). Освобождение off-heap памяти завязано на GC.
Аллоцировать буфер можно многими способами и вот некоторые из них.
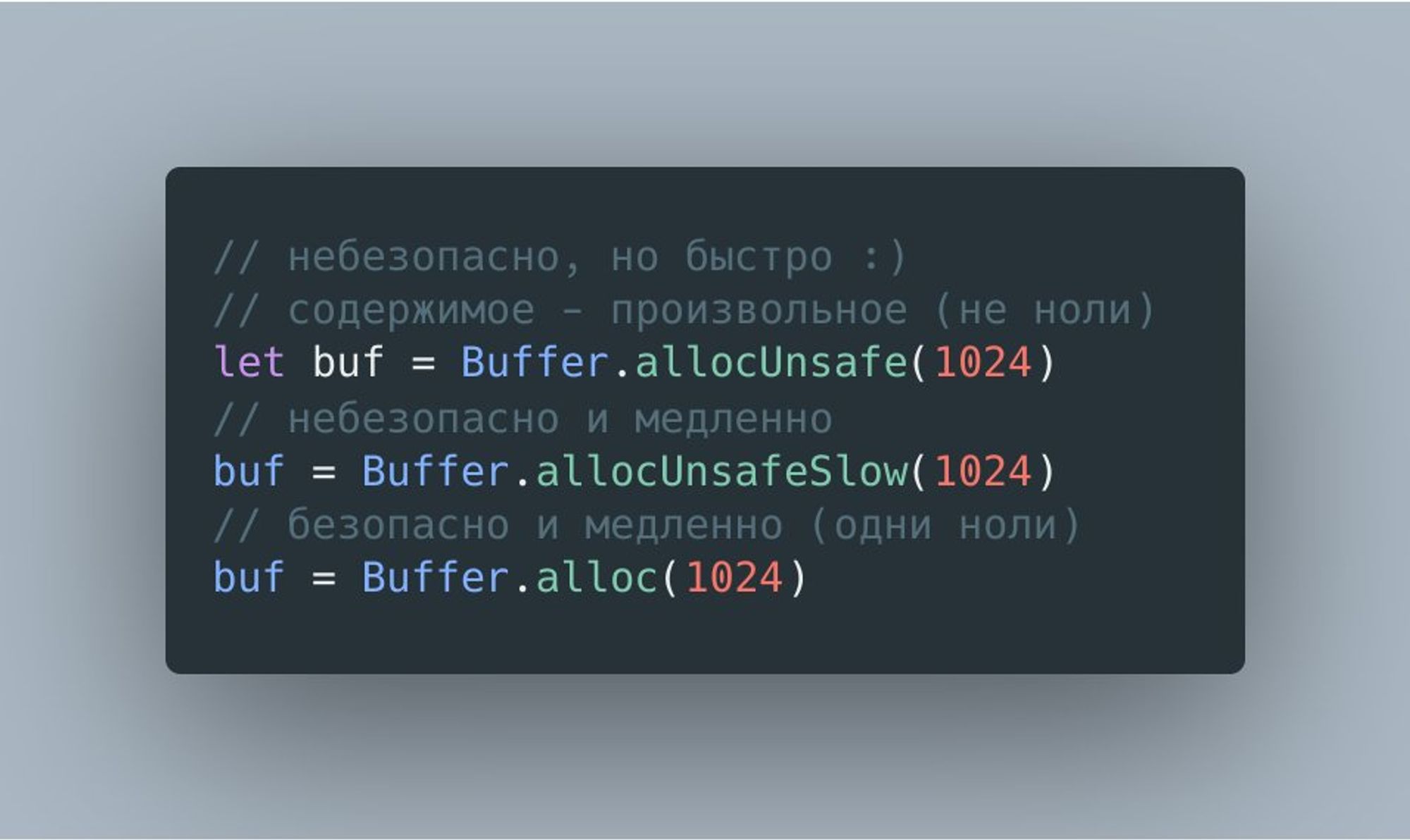
Думаю, что вы уже догадались, что аллокация буфера процесс относительно "дорогой" и задались вопросом, почему помимо небезопасной функции allocUnsafe() есть еще и allocUnsafeSlow().
Дело в том, что для небольших буферов в Node.js предусмотрена оптимизация. Системная библиотека сначала аллоцирует буфер-пул (назовем его так, хотя это и не пул в привычном смысле), размер которого задается свойством Buffer.poolSize.
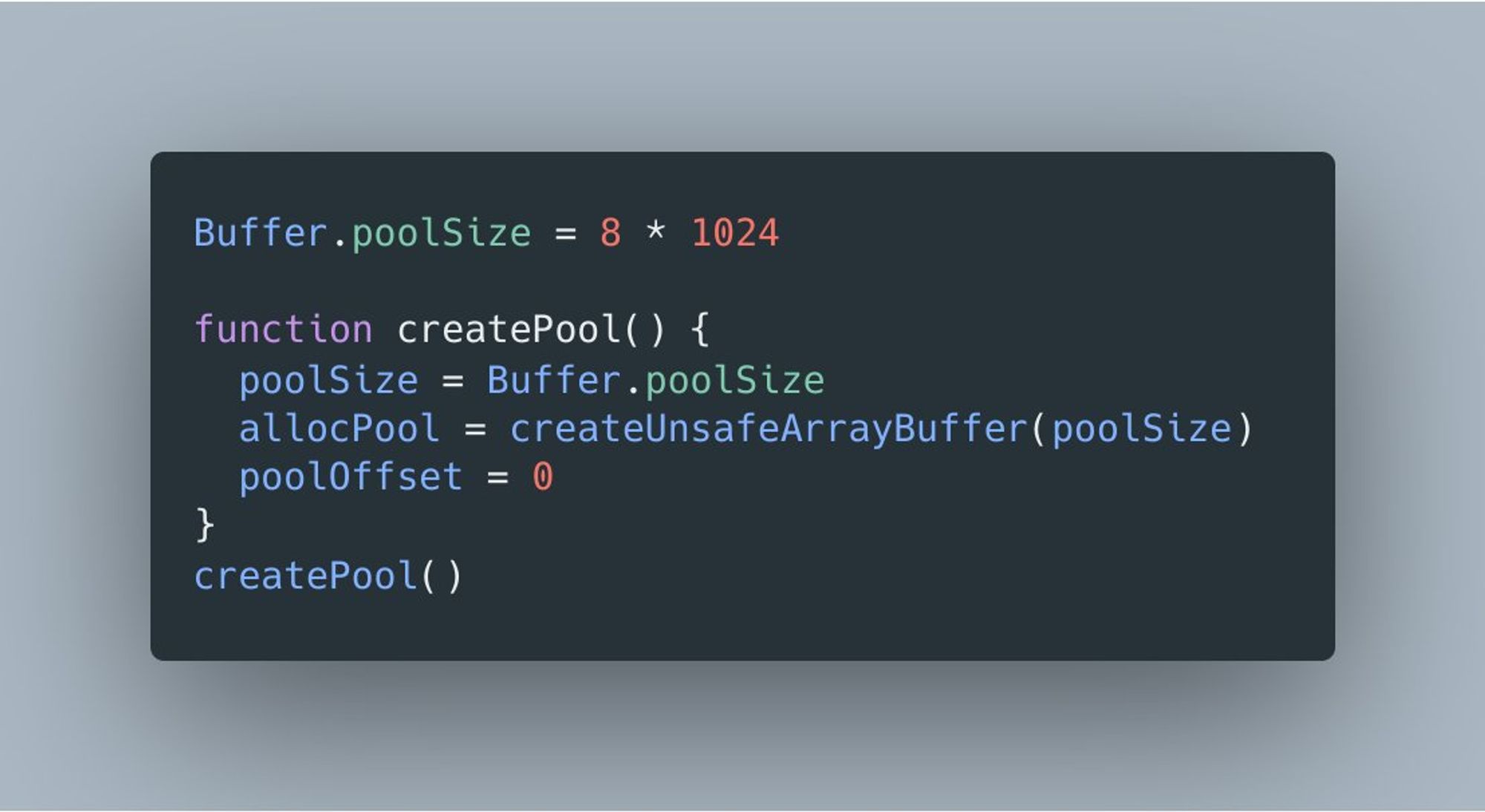
Затем при вызове allocUnsafe() проверяется запрошенный размер и, если он достаточно мал, буфер создается как slice из пула.
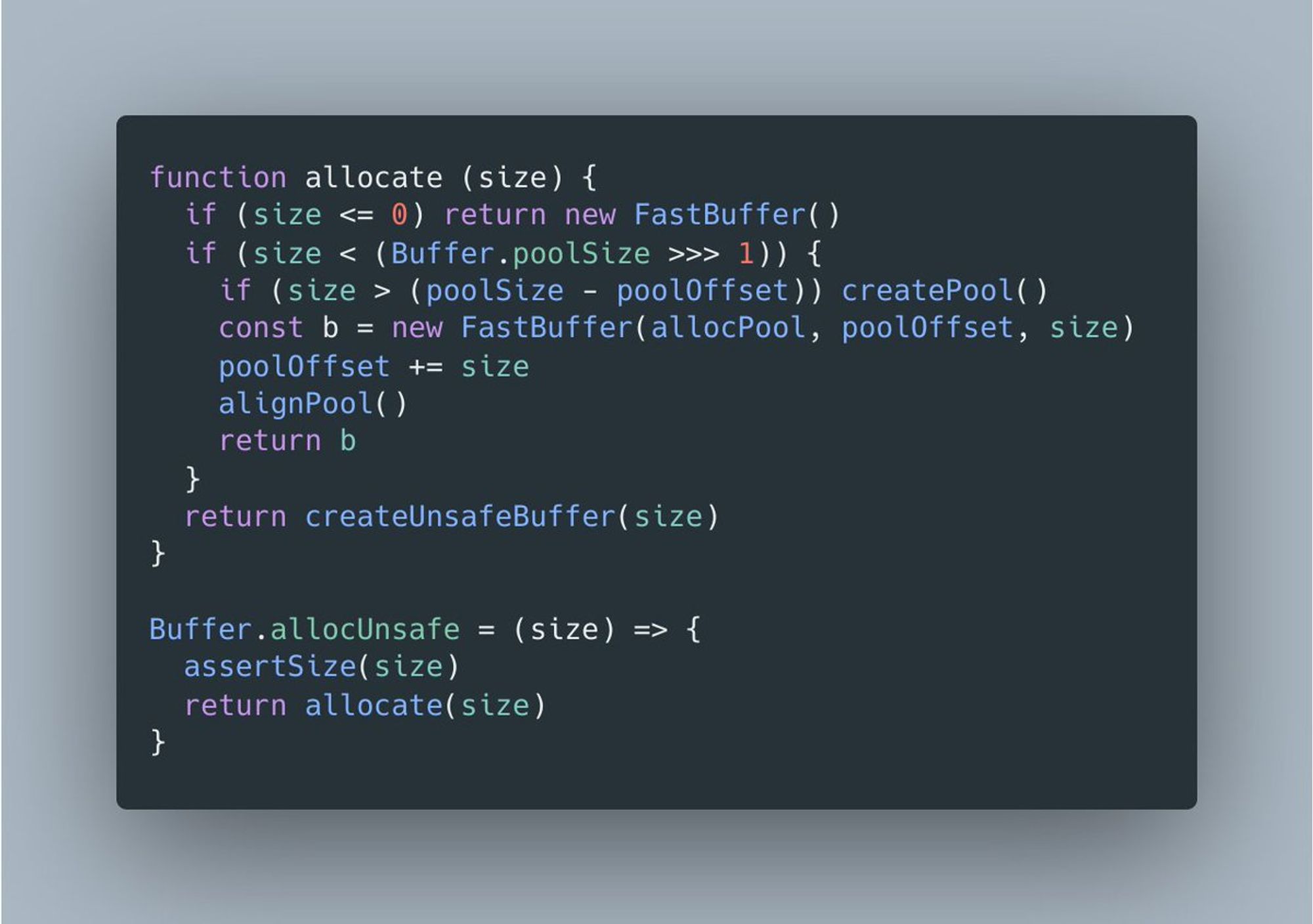
Это существенно уменьшает накладные расходы для allocUnsafe(). А, соответственно, allocUnsafeSlow() лишен этой оптимизации и напрямую аллоцирует каждый новый буфер.
Значение Buffer.poolSize по умолчанию это 8КБ, что совсем немного для современного серверного железа. Если его увеличить, это немного улучшит производительность самого core и некоторых библиотек, но, с другой стороны, это увеличит потребление памяти, что плохо для IoT устройств.
Поэтому тут напрашивается идея использования "честного" пула, т.е. API, которое позволит переиспользовать уже ненужные буферы. Обычно такие API используют явные вызовы alloc/offer, что требует дисциплины и в случае багов чревато mem leak'ами.
Лирическое отступление. В core есть класс FreeList, который реализует простейший пул. Он используется в модуле http для переиспользования объектов HTTPParser.
github.com/nodejs/node/bl…
github.com/nodejs/node/bl…
Но есть и альтернатива такому "ручному" подходу. Что если использовать финализаторы для возврата буферов в пул? Идея эксперимента появилась в ходе обсуждения проблем глобального свойства Buffer.poolSize с коллабораторами. Подробнее тут.
github.com/nodejs/node/is…
Сказано - сделано. Исходники и результаты эксперимента можно посмотреть тут.
github.com/puzpuzpuz/nbuf…
P.S. FinalizationGroup это старое название FinalizationRegistry.
Вкратце можно сказать следующее. Ожидаемо, экспериментальный пул оказался быстрее. Однако, из-за особенностей аллокатора libc (предполжительно) в особенно "горячих" сценариях RSS Node.js процесса рос как на дрожжах. Вывод - "ручной" подход предпочтительнее в силу предсказуемости.
Надеюсь, что такое обсуждение внутрянки Node.js не показалось вам излишним. Завтра мы пройдемся по небольшой выборке любопытных инициатив и экспериментов, которые могут повлиять на core и экосистему.