

Архив недели @AndreyPechkurov.
Понедельник
Привет из Воронежа. Меня зовут Андрей (@AndreyPechkurov) и на этой неделе мы поговорим про Node.js. Надесь, что темы будут для вас новыми и интересными: поговорим про нишевые core API и разного рода эксперименты, которые могут оказать влияние на runtime и экосистему.
Сегодня мы поговорим про модуль async_hooks и, в частности, класс AsyncLocalStorage (ALS), который недавно в нем появился. Это CLS (Continuation Local Storage) API, который имеет шансы вскоре выйти из экспериментального статуса (в отличие от самих async_hooks).
Начнем мы с простого примера использования ALS. Предположим, что мы хотим добавить id запроса во все сообщения журнала (log), с ним связанные. Самое простое решение - передавать контекст между всеми нашими модулями.
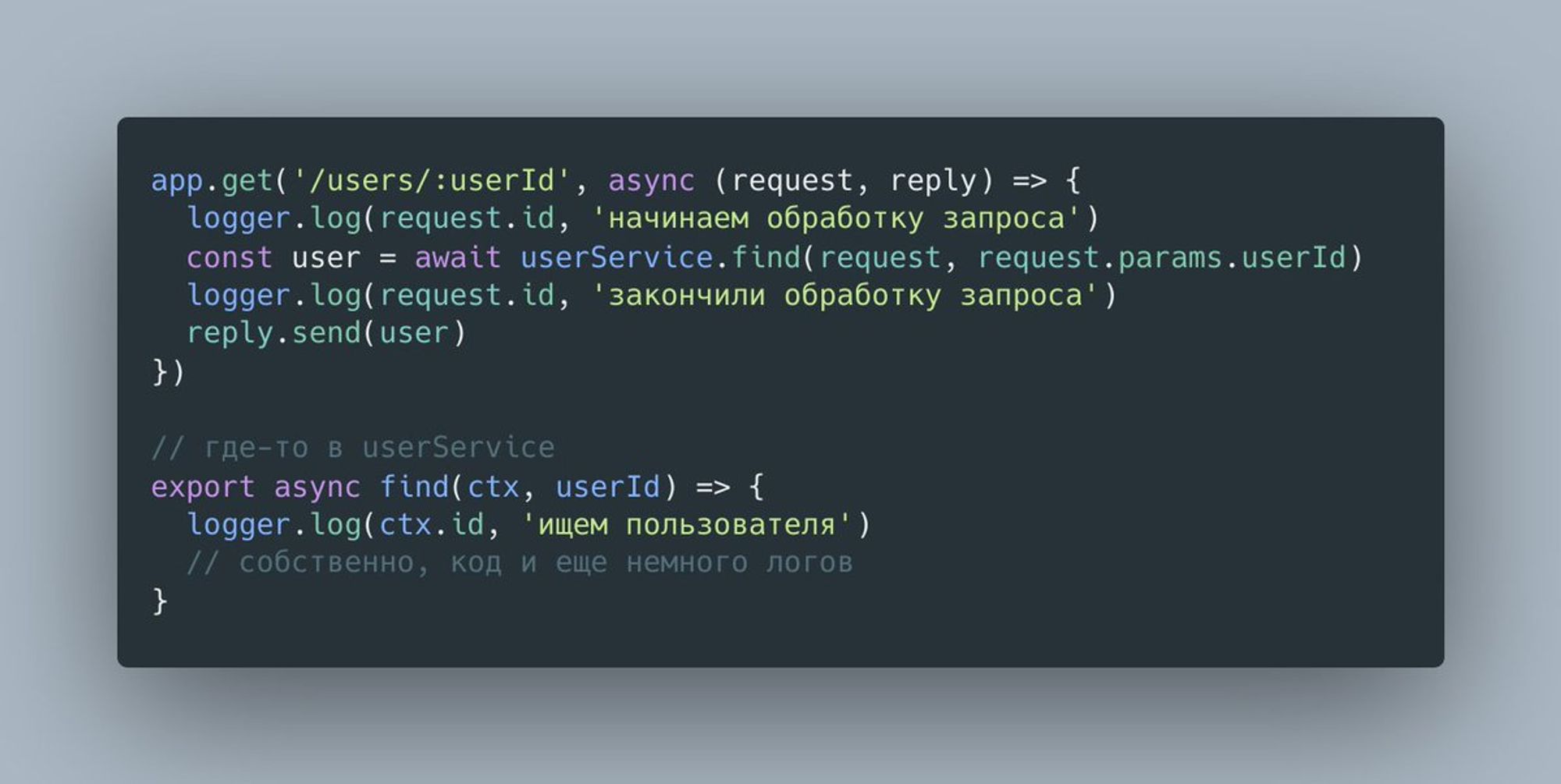
Но программисты народ ленивый (в хорошем смысле) и всегда пытаются уменьшить связность модулей и кол-во кода на сферическую фичу в вакууме. На помощь приходит ALS, позволяющий ассоциировать контекст с асинхронной цепочкой вызовов. Вот как это выглядит в случае с Fastify plugin.
Думаю те, кто работал с ThreadLocal в Java и AsyncLocal в .NET, увидели сходство. То, что было давно доступно в других runtime, в Node.js core появилось только в этом году после неоднократных обсуждений в TSC.
Что же было в экосистеме до появления ALS? Это были разнообразные user-land модули, самыми известными из которых были continuation-local-storage (отсюда аббревиатура - CLS) и его наследник cls-hooked. Их API во многом повлиял на ALS.
Любопытно, что оригинальный CLS был основан на древнем process.addAsyncListener API, который доступен только в Node.js v0.11, и его polyfill, реализованном за счет monkey patch'ей релевантных core API. А cls-hooked уже работал на async_hooks.
Тред (Андрей Печкуров)
Продолжим тему ALS. Не секрет, что у async_hooks есть "накладные расходы", связанные с трекингом ЖЦ объектов-ресурсов и вызовами хуков. Появление CLS API в core позволило реализовать некоторые оптимизации, уменьшающие overhead от ALS.
Например, в отличие от user-land библиотек, ALS не использует destroy хуков (благодаря функции executionAsyncResource()), поэтому для его работы не нужно отслеживать объекты-ресурсы, destroy событие которых зависит от GC.
Особенно, "дорого" это в случае нативных промисов. Но в недавних коммитах это отслеживание было отключено для AsyncResource (embedder API для async_hooks) и нативных промисов для случаев, когда активных destroy хуков нет. Как результат, overhead от ALS удалость снизить.
Недавно я портировал cls-rtracer, маленькую библиотеку, основанную на CLS API, с cls-hooked на ALS и сделал замер производительности простого HTTP echo сервера с несколькими записями в логи. Вот результат для Node.js v14.4.0.
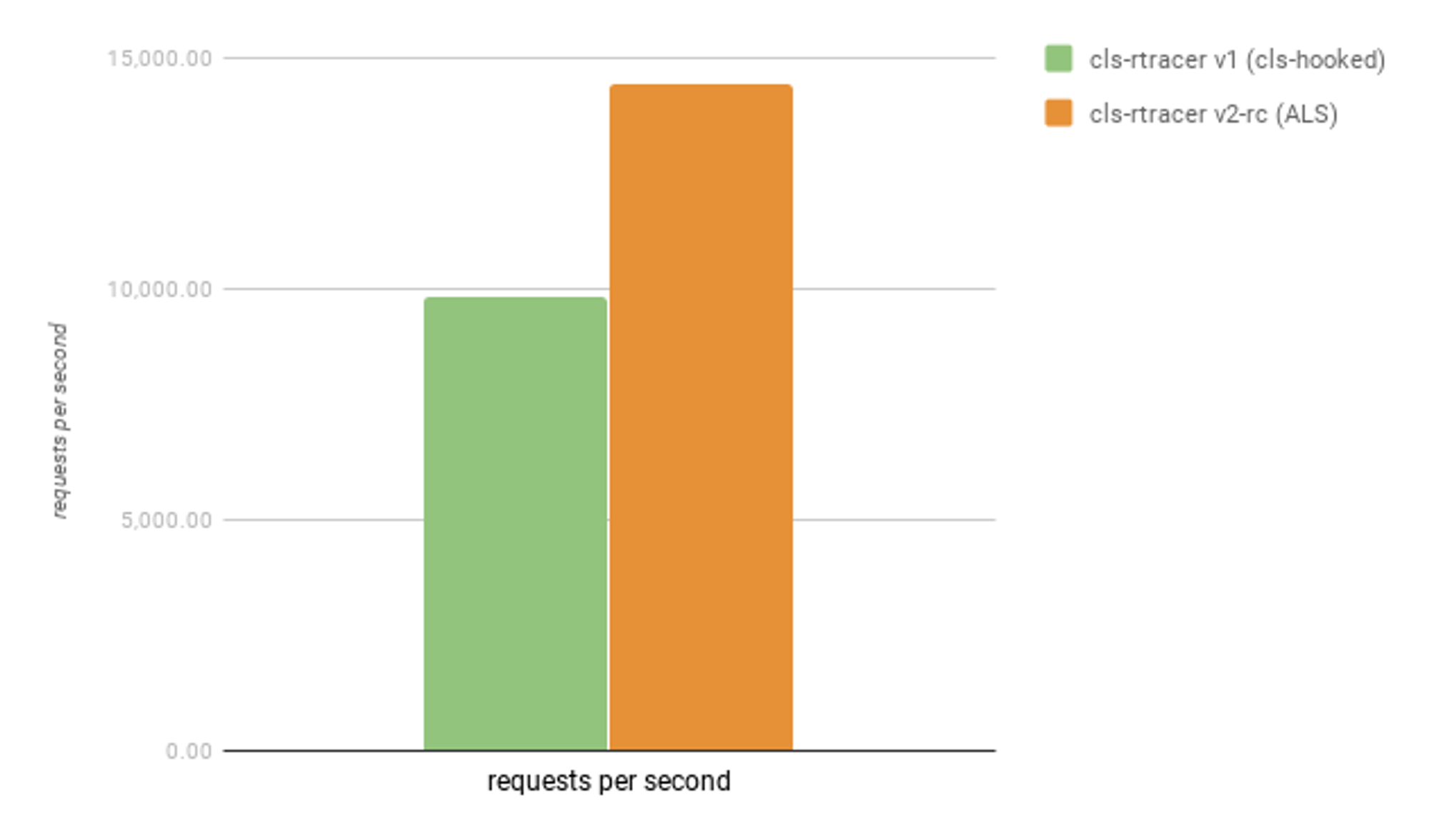
Этот бенчмарк наглядно показывает снижение расходов на CLS. Эти расходы, конечно, в любом случае остаются ненулевыми, но в будущем могут быть реализованы новые оптимизации, уменьшающие их.
Тред (Андрей Печкуров)
Конечно, логи это далеко не единственный пример использования CLS API. Для начала, давайте поговорим про внутрянку APM агентов (Application Performance Management).
Эти агенты в первую очередь нужны для отслеживания производительности веб-приложений. А это значит, что им нужно отслеживать контрольные точки обработки запросов. Как они это делают? Большинство из них устроены так.
Во-первых, они monkey patch'ат веб-фреймворки (включая, модуль http), драйверы БД и прочие популярные библиотеки, в которых нужно отследить контрольную точку. Но этого недостаточно. Нужно откуда-то взять контекст запроса (время его начала, контрольные точки и т.д.).
Поэтому, во-вторых, они используют CLS API в том или ином виде. Иногда он основан на диких monkey patch'ах core API, иногда на async_hooks и точечных патчах библиотек, которые не дружат с хуками.
Впрочем, есть надежда, что некоторые из них вскоре переедут на ALS, а популярные библиотеки начнут вести себя приличнее.
Если интересно посмотреть на исходный код одного из APM агентов, то вот пример:
github.com/googleapis/clo…
Кроме того, на async_hooks можно построить полезные диагностические инструменты. Такие как, например, bubbleprof визуализация из Clinic.js:
clinicjs.org/bubbleprof/
Наконец, async_hooks можно использовать для наблюдения за необработанными исключениями. Пример - модуль domain, который был портирован на async_hooks. С его помощью вы, например, можете сделать в таких случаях запись в лог и включить туда диагностическую информацию.
Тред (Андрей Печкуров)
Давайте теперь поговорим про перспективы ALS в рамках всей JS экосистемы.
Последняя ветка про этот API на сегодня, обещаю. :)
FE разработчики, пишущие на Angular, знакомы с Zone.js. Его API включает в себя концепцию CLS. Более того, реализация для Node.js некоторое время назад была основана на async_hooks. Сейчас там monkey patch'и, если я ничего не путаю.
В TC39 даже вносили на рассмотрение черновик стандарта, основанного на Zone.js. Но тема заглохла и его реализации мы уже вряд ли увидим.
Но есть идея повторить попытку и внести в TC39 на рассмотрение более простой стандарт, вдохновленный ALS подмножеством модуля async_hooks:
github.com/legendecas/pro…
Не знаю, что из этого выйдет, но было бы здорово увидеть такой API в браузерах.
Как обещал, завершаю эту тему. Если кому-то интересно поговорить про "внутрянку" async_hooks/ALS, спрашивайте. Постараюсь ответить на вопросы.
Тред (Андрей Печкуров)
Вторник
Сегодня мы пообщаемся на тему WeakRef + FinalizationRegistry. Эти API находятся на Stage 3 (Candidate) в TC39 и имеют все шансы выйти в свет в ближайшем будущем.
Слабые ссылки, они же WeakRef, просты, как песня, и многим хорошо знакомы по другим runtime.
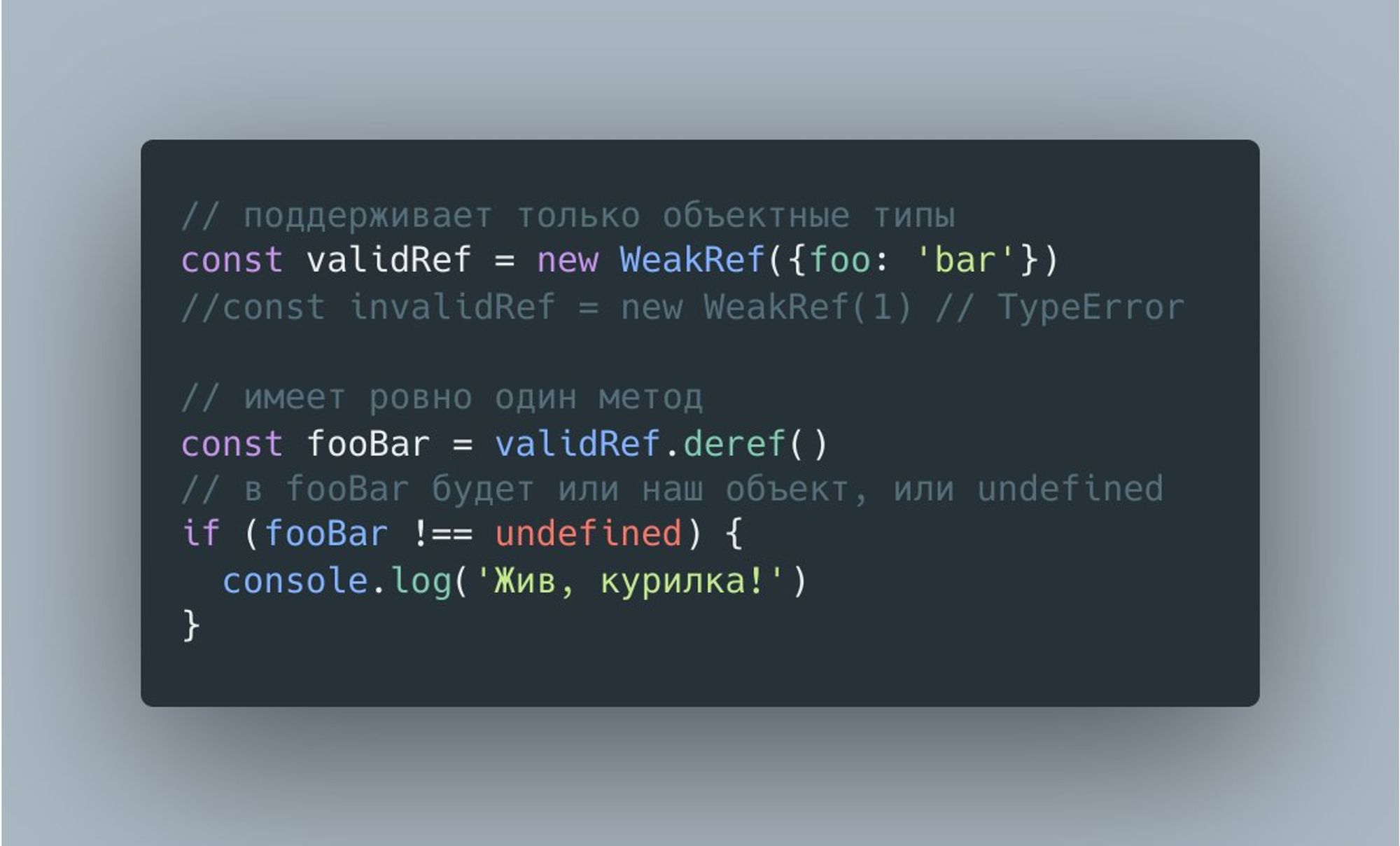
FinalizationRegistry немного сложнее и, как следует из названия, реализует механизм финализации объектов. Простейший пример его выглядит так.
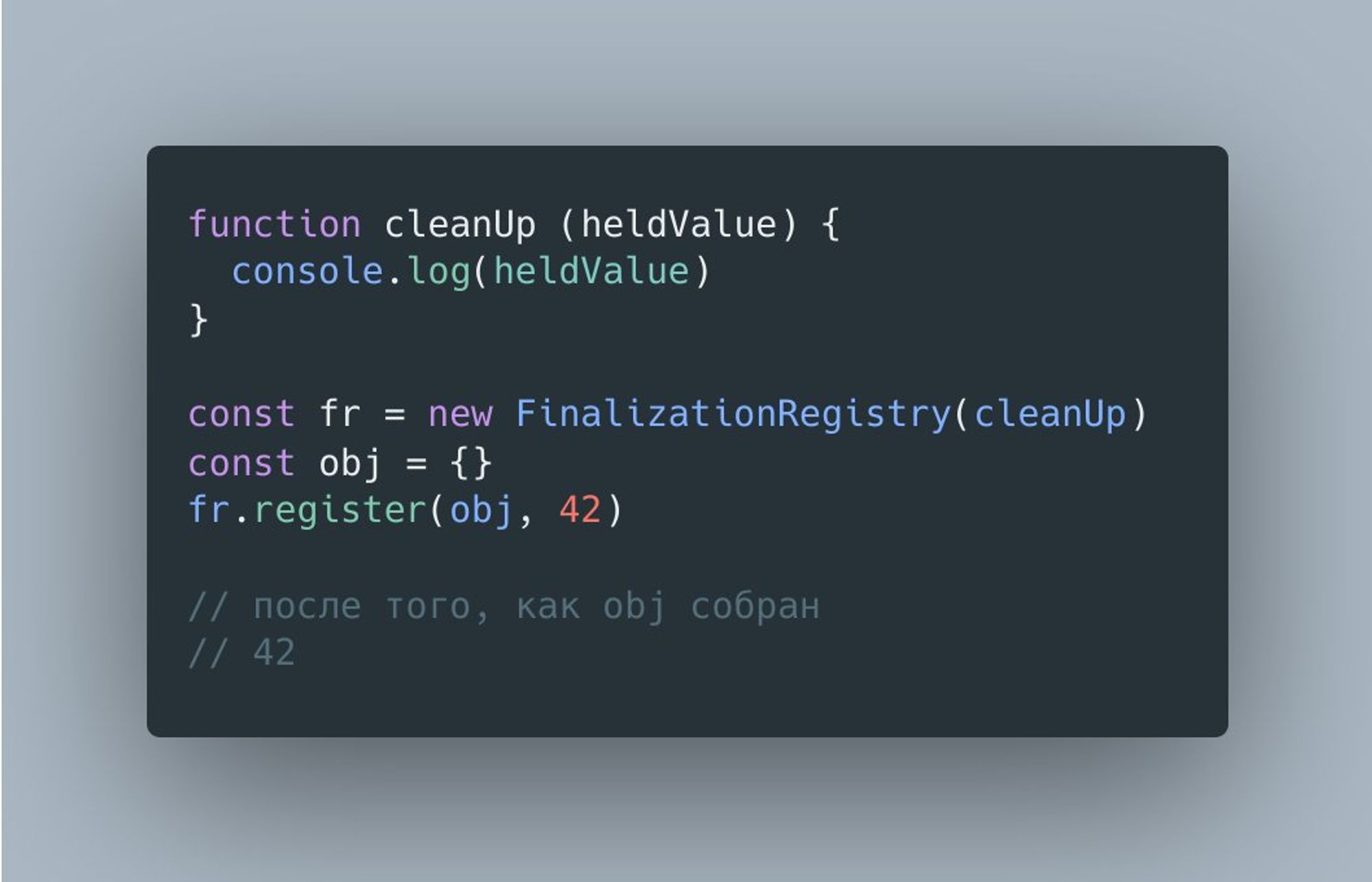
Эти API можно пощупать в Node.js v12+, указав флаг --harmony-weak-refs.
Но в core слабые ссылки уже давно используются во многих местах. Например, для хранения ссылок на JS объекты в нативных модулях.
github.com/nodejs/node/bl…
Есть и собственный утилитный класс WeakReference, который используется в domain.
github.com/nodejs/node/bl…
Про WeakMap и WeakSet, думаю, и говорить не нужно. Они используются в нескольких модулях.
Кстати, любопытно то, что WeakRef + Map !== WeakMap. Дело в возможных ссылках между ключами и значениями.
WeakMap построен на механизме ephemerons, позволяющем GC корректно обрабатывать циклы. Его семантика такова: пока не собран ключ, ссылка на значение - strong; когда же ключ собран, ссылка на значение трактуется, как weak.
Думаю, многих интересуют хорошие примеры применений новых API.
Примеры использования слабых ссылок в core подсказывают нам, что этот API пригодится вам в случаях, если вы не управляете ЖЦ пользовательских объектов, но хотите иметь доступ к ним, пока они достижимы.
Другой неплохой пример - очистка ресурсов WebAssembly при сборке JS объектов. Он хорошо расписан тут.
github.com/tc39/proposal-…
Другие примеры из этого документа я бы назвал хорошими с большой натяжкой. Кэш с WeakRef не дает вам гарантий по времени нахождения в нем значений и я бы предпочел ему LRU/LFU кэш. Другие примеры тоже не идеальные и причина в этом одна.
Дело в том, что оба API, ожидаемо, не дают никаких гарантий по детерменистичности своей работы, поскольку они завязаны на GC. Это проблема характерна подобных API во всех языках, а не только для JS.
Поэтому точно не стоит освобождать системные ресурсы (скажем, fd в Linux) или соединения с БД через финализаторы. Иначе, вы рискуете словить непредсказуемые баги в произвольных условиях. Старый добрый блок finally (условно, конечно) куда лучше подходит для подобных случаев.
Если вы знаете еще какие-то хорошие use case'ы для этих экспериментальных API, пишите. Думаю, это будет очень полезно для сообщества.
Тред (Андрей Печкуров)
Среда
Сегодня немного пройдемся по внутренней кухне Node.js и моим, связанным с ней (странным) экспериментам.
Если вы работали с бинарными данными в Node.js или, например, пытались реализовать драйвер БД с бинарным протоколом, вам знаком класс Buffer из одноименного модуля.
Любопытно то, что сами бинарные данные Buffer хранит off-heap, а в куче хранится только объект с метаданными. Соответственно, при создании буфера вызывается аллокатор (Node.js использует системный аллокатор). Освобождение off-heap памяти завязано на GC.
Аллоцировать буфер можно многими способами и вот некоторые из них.
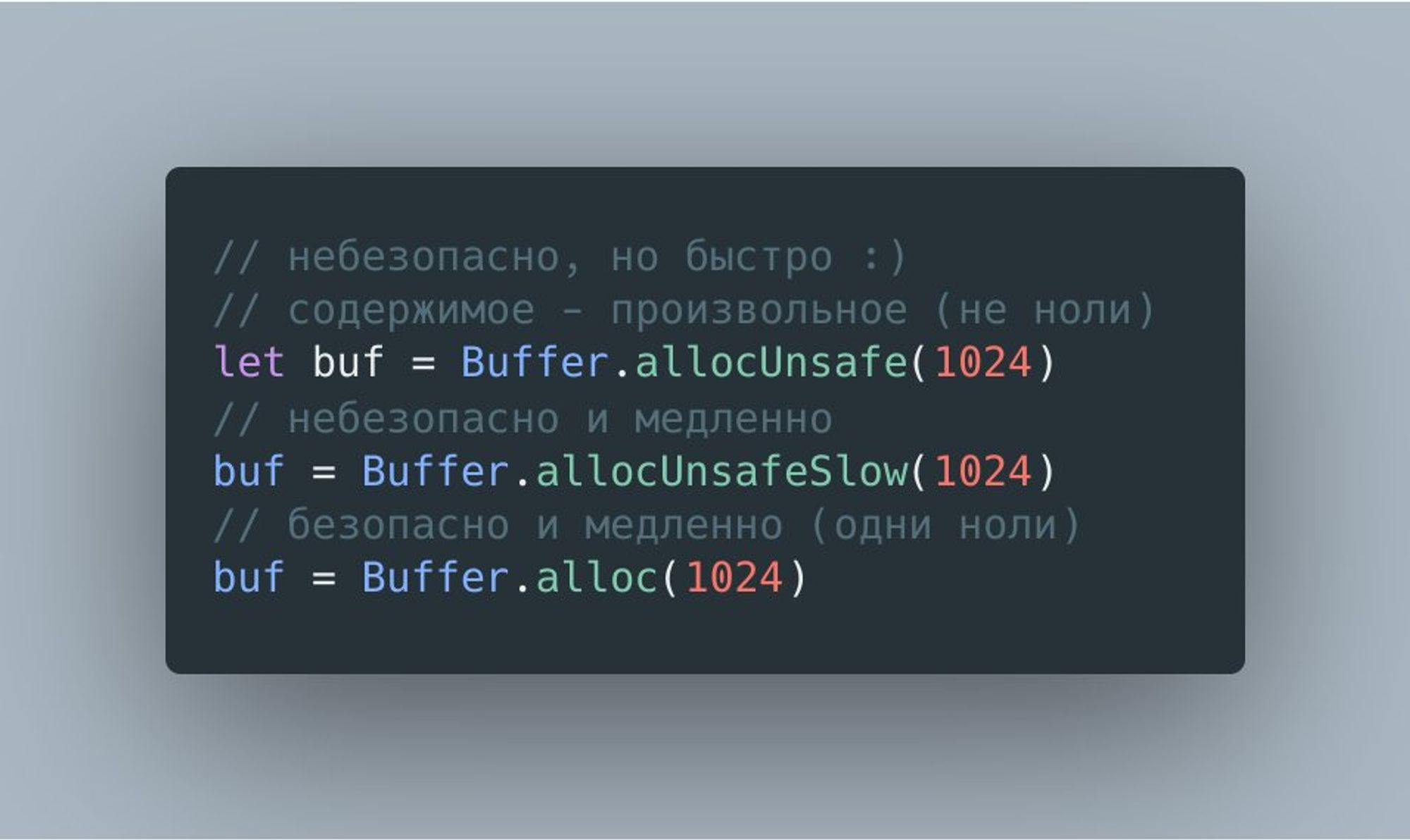
Думаю, что вы уже догадались, что аллокация буфера процесс относительно "дорогой" и задались вопросом, почему помимо небезопасной функции allocUnsafe() есть еще и allocUnsafeSlow().
Дело в том, что для небольших буферов в Node.js предусмотрена оптимизация. Системная библиотека сначала аллоцирует буфер-пул (назовем его так, хотя это и не пул в привычном смысле), размер которого задается свойством Buffer.poolSize.
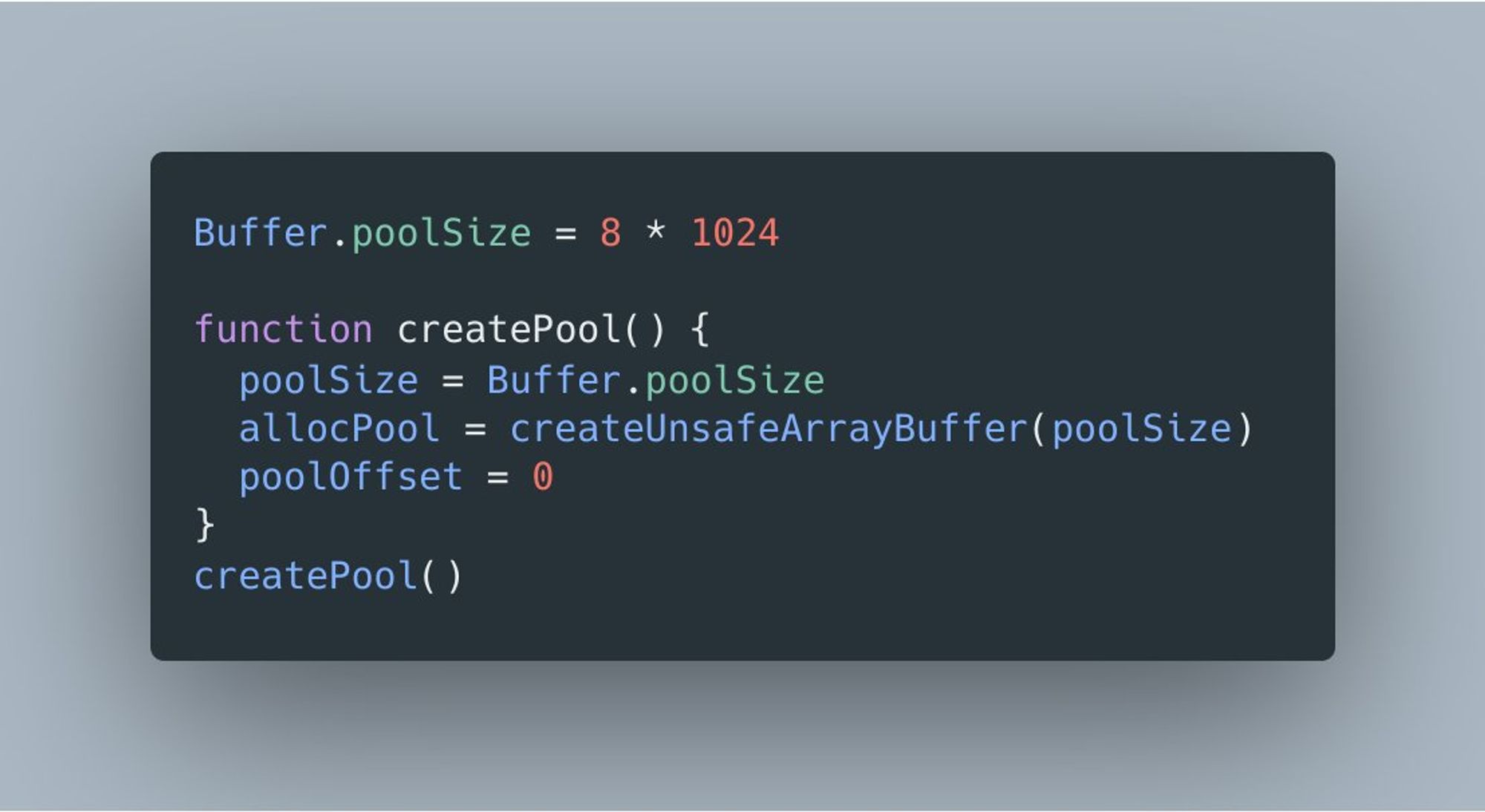
Затем при вызове allocUnsafe() проверяется запрошенный размер и, если он достаточно мал, буфер создается как slice из пула.
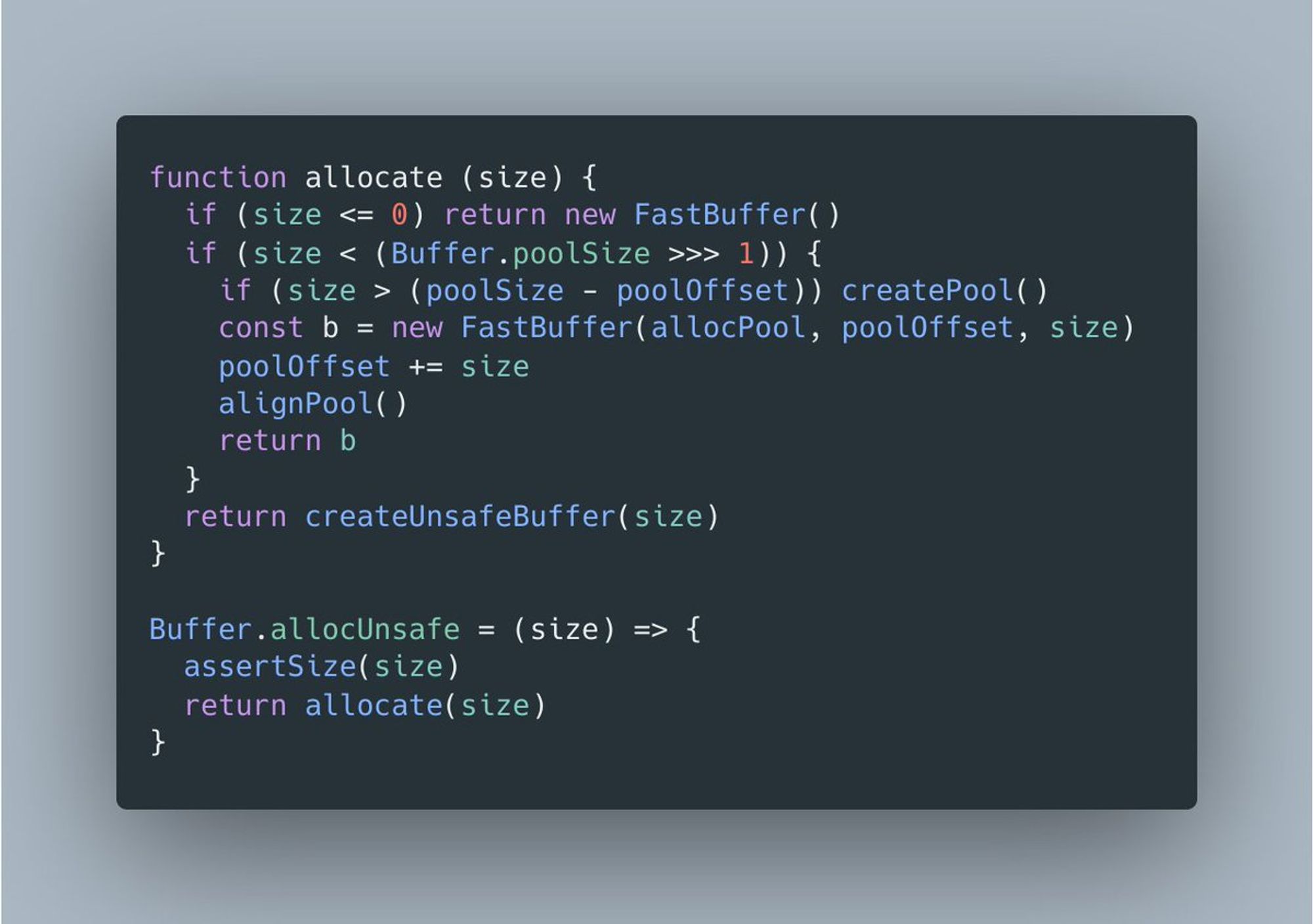
Это существенно уменьшает накладные расходы для allocUnsafe(). А, соответственно, allocUnsafeSlow() лишен этой оптимизации и напрямую аллоцирует каждый новый буфер.
Значение Buffer.poolSize по умолчанию это 8КБ, что совсем немного для современного серверного железа. Если его увеличить, это немного улучшит производительность самого core и некоторых библиотек, но, с другой стороны, это увеличит потребление памяти, что плохо для IoT устройств.
Поэтому тут напрашивается идея использования "честного" пула, т.е. API, которое позволит переиспользовать уже ненужные буферы. Обычно такие API используют явные вызовы alloc/offer, что требует дисциплины и в случае багов чревато mem leak'ами.
Лирическое отступление. В core есть класс FreeList, который реализует простейший пул. Он используется в модуле http для переиспользования объектов HTTPParser.
github.com/nodejs/node/bl…
github.com/nodejs/node/bl…
Но есть и альтернатива такому "ручному" подходу. Что если использовать финализаторы для возврата буферов в пул? Идея эксперимента появилась в ходе обсуждения проблем глобального свойства Buffer.poolSize с коллабораторами. Подробнее тут.
github.com/nodejs/node/is…
Сказано - сделано. Исходники и результаты эксперимента можно посмотреть тут.
github.com/puzpuzpuz/nbuf…
P.S. FinalizationGroup это старое название FinalizationRegistry.
Вкратце можно сказать следующее. Ожидаемо, экспериментальный пул оказался быстрее. Однако, из-за особенностей аллокатора libc (предполжительно) в особенно "горячих" сценариях RSS Node.js процесса рос как на дрожжах. Вывод - "ручной" подход предпочтительнее в силу предсказуемости.
Надеюсь, что такое обсуждение внутрянки Node.js не показалось вам излишним. Завтра мы пройдемся по небольшой выборке любопытных инициатив и экспериментов, которые могут повлиять на core и экосистему.
Тред (Андрей Печкуров)
Четверг
Как договаривались, сегодня пройдемся по экспериментам и инициативам, которые могут повлиять на core и экосистему. Подборка субъективная и намеренно нишевая. Если вы знаете что-то, чем можно поделиться в рамках этой темы, пишите, пожалуйста.
Начнем мы с эксперимента по поддержке io_uring, свежего механизма для асинхронного ввода/вывода в ядре Linux, в libuv. Вот тут можно посмотреть на экспериментальный PR:
github.com/libuv/libuv/pu…
Если кто-то не слышал про libuv, то это кросс-платформенная библиотека для асинхронного I/O (и не только), на которой основывается Node.js.
Сейчас libuv в Linux для сетевого I/O использует epoll, механизм мультиплексирования, позволяющий работать сразу со многими сокетами и не блокироваться в ожидании готовности к чтению/записи. Вот краткий, но емкий доклад про epoll:
youtu.be/P9csgxBgaZ8
Использование более эффективного механизма может дать прирост производительности нагруженных сетевых приложений.
Вот очень подробная статья про устройство io_uring:
lwn.net/Articles/77670…
Тред (Андрей Печкуров)
Идем дальше. Недавно в V8 добавили очень классную фичу, а именно, pointer compression. Подробности в этой классной статье от команды V8:
v8.dev/blog/pointer-c…
Идея заключается в том, чтобы хранить ссылки на объекты в куче в 32 битах на 64-битных архитектурах, а затем получать конечный адрес с нолями в первых 4 октетах. Так можно адресовать до 4ГБ памяти.
Логично, что это ведет к ощутимой экономии памяти. К тому же, как ни удивительно, эта фича еще и дала прирост производительности.
Конечно, уже есть инициатива по интеграции pointer compression в Node.js. Там есть нюансы с нативными модулями, но их можно решить. Подробное обсуждение тут:
github.com/nodejs/TSC/iss…
Тред (Андрей Печкуров)
Вы могли слышать, что в Node.js 12.5.0 ускорили время старта за счет так называемых V8 snapshots. Подробности можно почитать тут.
v8.dev/blog/custom-st…
github.com/nodejs/node/is…
github.com/nodejs/node/pu…
Однако, интеграция была частичная и заметного сокращения времени старта это не дало. На данный момент ведутся работы по дальнейшей интеграции и это должно дать ощутимый эффект. Подробности в этом PR:
github.com/nodejs/node/pu…
HTTP/3 еще находится в стадии черновика и активно идет работа по совершенствованию стандарта. И похоже, что Node.js станет одной из первых платформ, поддерживающих HTTP/3.
Об этом можно судить хотя бы по PR'ам, реализующим QUIC, транспортный протокол поверх UDP, поверх которого работает HTTP/3. Поскольку о поддержке на уровне ОС пока говорить рано, его приходится писать в самом runtime. Кстати, вот свежий PR на тему QUIC:
github.com/nodejs/node/pu…
Если вы хотите провести какой-то эксперимент с Node.js, то лучше сначала поискать в GH issues. Например, я как-то задался вопросом, что будет, если системный аллокатор заменить на jemalloc. И, конечно же, нашелся результат такого эксперимента:
github.com/nodejs/node/is…
Если кто-то не знаком с jemalloc, то это аллокатор памяти, изначально реализованный для FreeBSD, а теперь активно поддерживаемый Facebook. Вот статья, описывающая его оригинальный дизайн (в текущей версии много изменилось, но суть та же):
people.freebsd.org/~jasone/jemall…
В момент появления jemalloc хорошо выглядел в сравнении с libc аллокатором, но сейчас уже все не так однозначно. Что наглядно показывает GH issue с результатами эксперимента. Поэтому Node.js по-прежнему используется системный аллокатор.
Небольшой офтопик для знакомых с Java. Дизайн jemalloc был использован для off-heap аллокатора в сетевом фреймворке Netty. Да-да, вы не ослышались, в Netty есть off-heap аллокатор, написанный на Java.
Предлагаю на сегодня на этом остановиться. Завтра мы пообщаемся на тему инструментов анализа производительности и диагностики Node.js приложений.
Тред (Андрей Печкуров)
Пятница
Как договаривались, сегодня обсуждаем инструменты анализа производительности и диагностики Node.js приложений. Мой опыт в основном сводится в оптимизации сетевых библиотек, поэтому если есть чем поделиться, пишите.
Все знаю мантру "don't block the event loop (or libuv worker pool)", но в Node.js приложениях, как правило, куча зависимостей и поэтому бывает очень сложно сказать наверняка, что event loop ничто не блокирует.
Поэтому бывает полезно прогнать приложение с флагом --trace-sync-io. Он выводит в консоль предупреждение, если вызов синхронного API происходит после первый итерации event loop.
nodejs.org/api/cli.html#c…
Так, например, можно узнать, что uuid/v4 из популярной библиотеки содержит синхронный вызов. Один из пользователей воспользовался этим флагом и нашел проблему в моей библиотеке (посыпаю голову пеплом).
github.com/puzpuzpuz/cls-…
В Node.js есть встроенный профилировщик (на самом деле, это V8 profiler). Запустить его можно через флаг --prof.
Он сэмплирующий, т.е. он делает сэмплы стека вызовов с равномерным интервалом и пишет результат в отчет. Соответственно, потом этот отчет можно перевести в человекочитаемый файл, где приведена статистика по вызовам.

Классно то, что профилировщик корректно работает с нативными вызовами, а не только с JS кодом. При этом, к сожалению, вся документация на него сводится вот к этой статье:
nodejs.org/en/docs/guides…
Из человекочитаемого представления можно почерпнуть, какие вызовы выглядят подозрительно (они, как правило, будут где-то в топе). Но бывает полезно построить flame graph. Проще всего это сделать с помощью библиотеки 0x. Подробнее в гайде:
nodejs.org/en/docs/guides…
На flame graph нужно смотреть на так называемые плато, т.е. вызовы, оказавшиеся во многих сэмплах. Но в реальных бенчмарках ярко выраженных плато может не оказаться или же они могут быть false positive. В этом случае придется перебирать подозрительные вызовы и строить гипотезы.

Вообще, прежде чем браться за профилировщик, советую изолировать анализируемую часть функционала в бенчмарк и уже его профилировать. Если запустить профилировщик на всем приложении, разобраться в полученных данных будет почти невозможно.
И разумеется, если у вас проблемы с памятью, то этот профилировщик вам не поможет.
Тред (Андрей Печкуров)
Что касается анализа потребления памяти и поиска mem leak'ов, то тут все банально. Локально можно пользоваться профилировщиком памяти из Chrome DevTools. Он умеет делать heap snapshot'ы и сравнивать их, отслеживать аллокации и не только.
В production можно делать heap dump, если уверены, что есть примерно x2 памяти для этого. Если хочется делать snapshot, когда память кончилась, то core dump это более практичный вариант (пока). Вот тут можно почитать подробнее, почему так.
github.com/nodejs/node/is…
Еще сложно выявляемая одна проблема в приложениях, это unhandled promise rejection. Боль в том, что они делаю ваш код менее пресказуемым и, в некоторых ситуациях, чреваты утечкой ресурсов, а иногда, и памяти.
Лично я склоняюсь к тому, что fail fast поведение в ответ на unhandled promise rejection - это наиболее разумное решение. Само собой это подразумевает запись в логи и рестарт приложения.
Такую логику несложно написать самому. Ну, или использовать готовый модуль навроде этого:
github.com/mcollina/make-…
И еще немного на тему диагностики production приложений. В Node.js есть классные диагностические отчеты, сбор которых можно гибко настроить.
nodejs.org/api/report.html
На этом на сегодня все. Ну, и как всегда, если есть чем поделиться, пишите, пожалуйста.
Суббота
Сегодня поговорим, как можно помочь Node.js, как open source проекту.
Во-первых, можно улучшить тесты. Если видите, что в каком-то модуле нет 100% покрытия по веткам, это повод для улучшения тестов. Текущее покрытие можно смотреть тут:
coverage.nodejs.org
Во-вторых, документация всегда требует внимания и совершенствования. Заметили неточность или недостаток информации, "вешайте" PR с улучшением. Исходники документации находятся тут:
github.com/nodejs/node/tr…
В-третьих, можно взять одну из good first issues:
github.com/nodejs/node/is…
Наконец, если у вас есть идея по улучшению core APIs, советую сначала поискать в старых issue и PR'ах, а потом создать свою GH issue и узнать мнение collaborator'ов об идее. Так можно получить ценные советы и подойти к реализации идеи подготовленным.
Тред (Андрей Печкуров)
Воскресенье
Неделя заканчивается и я предлагаю внести чуть больше интерактива в наше общение. Что вы хотели бы изменить или добавить в Node.js core?
Неделя пролетела быстро. Надеюсь, вам общение показалось таким же интересным, как и мне. Всем пока!







