

В 2018 году, собрав фидбек от пользователей, мы поняли, что отображения превью на отдельном шаге недостаточно.
Пользователи хотели видеть:
— как меняется резюме прямо в процессе редактирования;
— как их контент помещается на А4-страницы в PDF.
👇
Поэтому мы разработали новую версию редактора, правую часть экрана в котором занимает лайв-превью с (внимание!) постраничной навигацией.
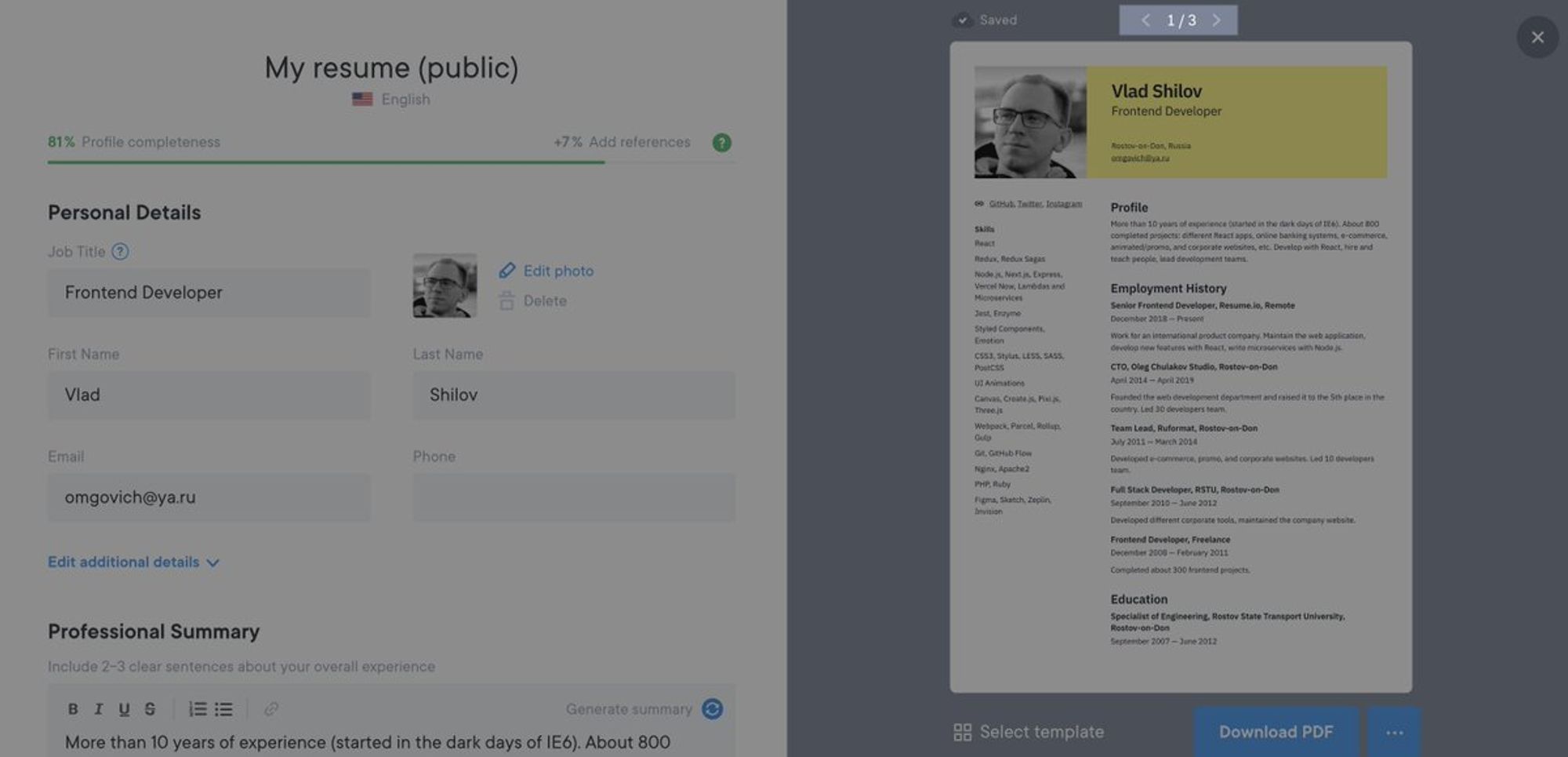
Принцип отрисовки самого превью мы не поменяли — это все еще были обычные HTML и CSS, которые показывали через iframe.
Но теперь ко всему этому добавилась необходимость эмулировать разделение контента на страницы А4.
И вот тут проблемы снова «полезли, как червячки»...
Суть в том, что веб-страница это просто длинное "полотно" и разделения на страницы у нее нет.
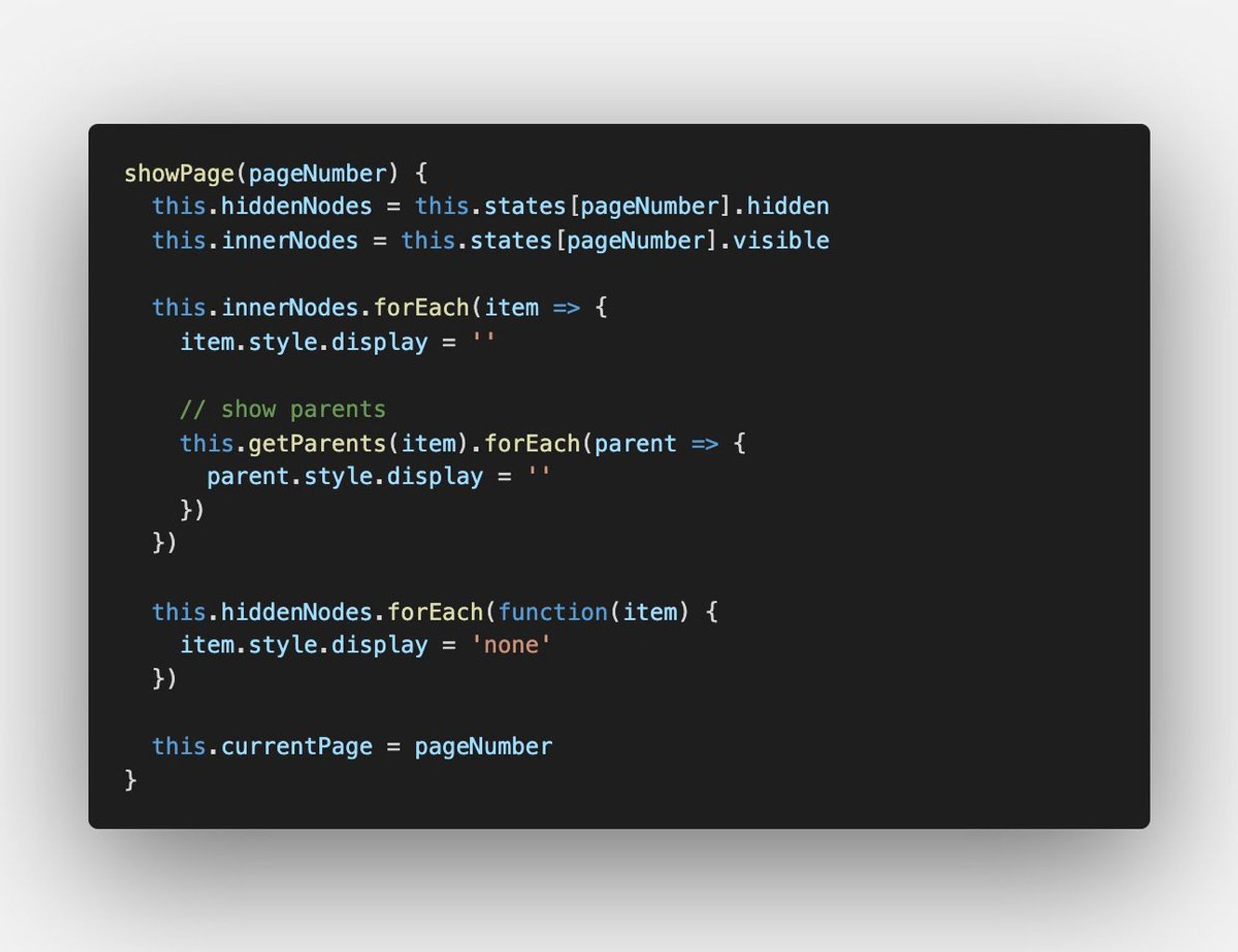
В попытках решить эту проблему, мы написали JS-скрипт под названием Paguin 🐧, который подключали на страницу превью (отображается внутри iframe).
Скрипт пробегался по всем HTML-элементам и проверял, попадают ли они в зону указанного размера и, таким образом собирал массивы элементов для каждой А4-страницы.
Общение между Paguin-ом в iframe и нашим редактором резюме осуществлялось через postMessage.
Paguin посылал "наверх" число страниц, на которое он разбил элементы страницы. А наше React-приложение посылало ему "вниз" команды на переключение страниц.
Смена страниц производилась без перезагрузки iframe — мы просто устанавливали display: none всем элементам, которые не попадали в массив для нужной страницы.
Вроде бы это все должно было решить проблему с превью, но увы...
Главной темой жалоб в поддержку стало то, что пользователи, глядя на превью, заполняли резюме, так чтобы оно помещалось на 1-2 страницы, а после скачивания получали другое число страниц и вообще другие переносы.
Дело в том, что полностью повторить, то как Chrome разбивает контент на А4-страницы при печати у нас не вышло. Из-за этого структура документа в превью часто отличалась от той, что была в скачанном PDF-файле.
Например, в сделанной Puppeteer-ом PDF-ке параграф текста мог начаться на одной странице, а закончится на другой. Мы не могли такое повторить, так как для нашего скрипта параграф — это один неразрывный HTML-элемент.
Были и более жестокие проколы. Например, некоторые пользователи заполняли резюме так, что у них попадался непрервыный текст размером превышающий лист А4. Из-за этого наш скрипт попадал в бесконечный цикл и "вешал" браузер.
Кроме того, так как сами PDF-файлы мы генерировали с помощью Headless Chrome, у пользователей, например, Edge и Firefox, HTML-превью не было похоже на PDF еще сильнее. Другой рендеринг шрифтов, другие переносы в тексте и т.д. Короче, беда.

В течение года мы предпринимали разные попытки потюнить скрипт пагинации, но быстро стало понятно, что эту битву нам не выйграть. Не получится сделать HTML+CSS превью, которое будет в достаточной мере похоже на PDF-файл, который делается из этих же HTML+CSS.